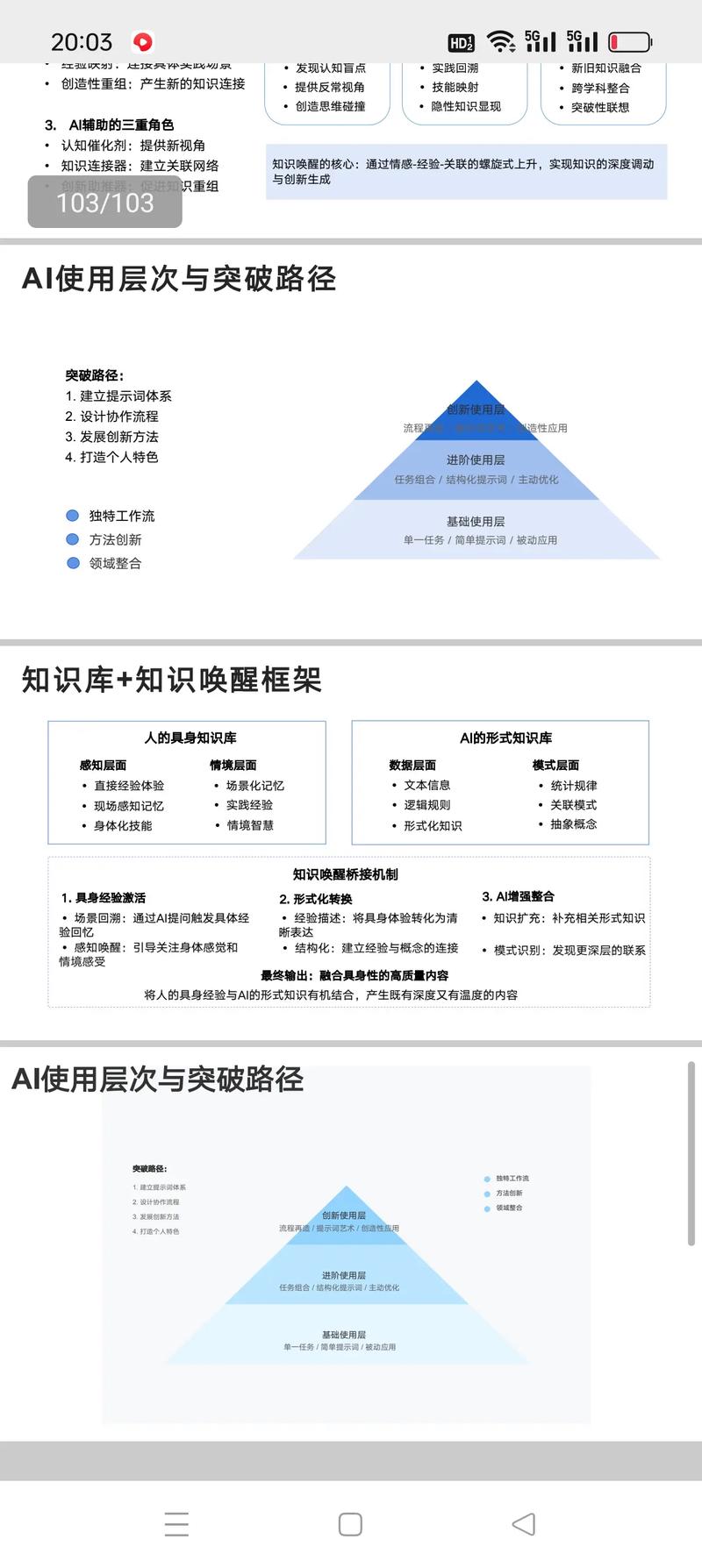
AI工具
发布文章-
发布了文章 2个月前
Unique3D – 清华大学团队开源的图像到3D生成模型
Unique3D是由清华大学团队开源的一个单张图像到3D模型转换的框架,通过结合多视图扩散模型和法线扩散模型,以及一种高效的多级上采样策略,能够从单张图片中快速生成具有高保真度和丰富纹理的3D网格。...
-
发布了文章 2个月前
UniToken – 复旦联合美团等机构推出的统一视觉编码框架
UniToken 是新型的自回归生成模型,专为多模态理解与生成任务设计。通过结合离散和连续的视觉表示,构建了一种统一的视觉编码框架,能同时捕捉图像的高级语义和低级细节。...
-
发布了文章 2个月前
UniTok – 字节联合港大、华中科技推出的统一视觉分词器
UniTok 是字节跳动联合香港大学和华中科技大学推出的统一视觉分词器,能同时支持视觉生成和理解任务。基于多码本量化技术,将视觉特征分割成多个小块,每块用独立的子码本进行量化,极大地扩展离散分词的表示能力,解决传统分词器在细...
-
发布了文章 2个月前
UniTalker – 商汤推出的音频驱动3D面部动画生成模型
UniTalker是推出的音频驱动3D面部动画生成模型,能根据输入的音频生成逼真的面部动作。采用统一的多头架构模型,用带有不同标注的数据集,支持多语言和多种音频类型的处理,包括语音和歌曲。...

-
发布了文章 2个月前
UniRig – 清华联合 VAST 开源的通用自动骨骼绑定框架
UniRig是清华大学计算机系和VAST联合推出的创新自动骨骼绑定框架,用在处理复杂和多样化的3D模型。基于大型自回归模型和骨骼点交叉注意力机制,生成高质量的骨骼结构和蒙皮权重。...
-
发布了文章 2个月前
UniReal – 港大联合 Adobe 推出的通用图像生成和编辑框架
UniReal是什么 UniReal是香港大学和Adobe研究院共同推出的框架,专注于实现多种图像生成和编辑任务。框架基于模拟现实世界动态,能在单一模型中处理包括图像生成、编辑、定制和合成在内的广泛任务。UniReal将不同...
-
发布了文章 2个月前
UniPortrait – 阿里推出的AI人像图像个性化编辑工具
...
-
发布了文章 2个月前
UniFluid – 谷歌联合麻省理工推出的多模态图像生成与理解框架
UniFluid 是谷歌 DeepMind 和麻省理工学院联合推出的,统一的自回归框架,用在联合视觉生成和理解任务。基于连续视觉标记处理多模态图像和文本输入,生成离散文本标记和连续图像标记。框架基于预训练的 Gemma 模型...
-
发布了文章 2个月前
UniEdit – 免训练调优的统一视频编辑框架
UniEdit是由浙江大学、微软研究院和北京大学的研究人员推出的一个创新的视频编辑框架,允许用户在不需要进行模型微调的情况下,对视频的运动和外观进行编辑,能够同时处理视频的时间维度(如动作变化)和空间维度(如风格化、物体替换...
-
发布了文章 2个月前
UniBench – Meta推出的视觉语言模型(VLM)评估框架
UniBench是Meta FAIR机构推出的视觉语言模型(VLM 评估框架,对视觉语言模型(VLM 进行全面评估。UniBench包含50多个基准测试,涵盖物体识别、空间理解、推理等多维度能力。...
-
发布了文章 2个月前
UniAct – 清华、商汤、北大、上海AI Lab共同推出的具身基础模型框架
UniAct 是新型的具身基础模型框架,解决不同机器人之间行为异构性的问题。通过学习通用行为,捕捉不同机器人共享的原子行为特征,消除因物理形态和控制接口差异导致的行为异构性。...
-
发布了文章 2个月前
Uni-baidu09AdaFocus – 清华大学推出通用的高效视频理解框架
Uni-AdaFocus是清华大学自动化系的研究团队推出的通用的高效视频理解框架,框架通过自适应聚焦机制,动态调整计算资源的分配,实现对视频内容的高效处理。...
-
发布了文章 2个月前
Unbounded – 谷歌推出的首款AI生成式无限人生模拟游戏
Unbounded是谷歌和北卡罗来纳大学教堂山分校共同推出的无限人生模拟游戏。游戏突破传统视频游戏的局限,用生成模型,如大型语言模型(LLM 和视觉生成模型,创造一个没有固定规则和边界的游戏体验。玩家与自己的虚拟角色互动,用...
-
发布了文章 2个月前
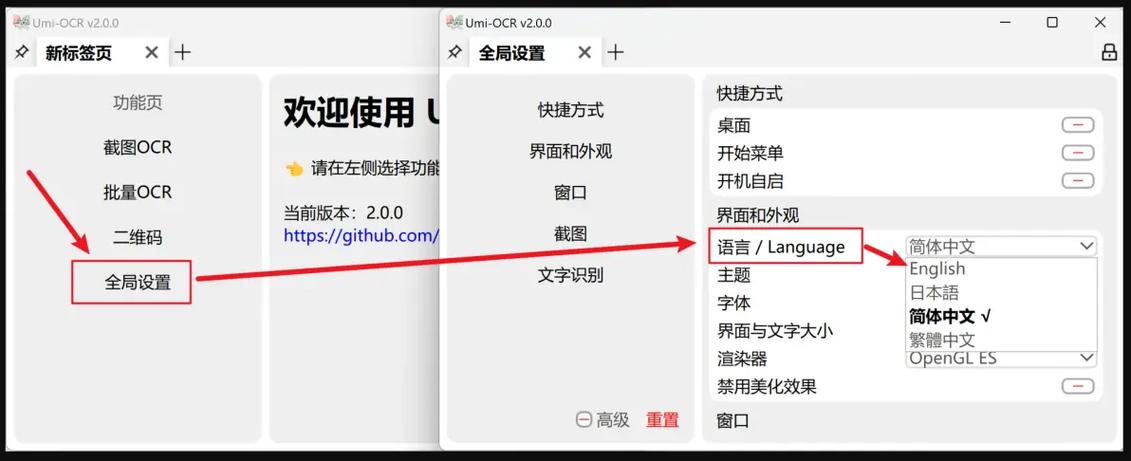
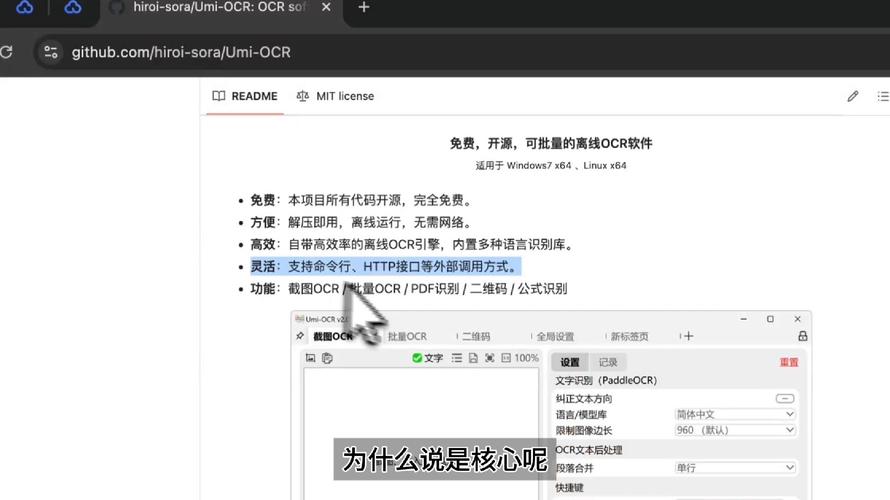
Umi-baidu09OCR – 免费 OCR 文字识别工具,支持截图、批量图片排版解析
Umi-OCR 是免费开源的离线 OCR 文字识别软件。无需联网,解压即用,支持截图、批量图片、PDF 扫描件的文字识别,能识别数学公式、二维码,可生成双层可搜索 PDF。内置多语言识别库,界面支持多语言切换,提供命令行和...
-
发布了文章 2个月前
Ultravox – 端到端多模态大模型,直接理解文本和人类语音
Ultravox是新型的多模态大型语言模型(LLM),能直接理解文本和人类语音,无需依赖单独的自动语音识别(ASR)阶段。基于多模态投影器技术将音频数据转换为高维空间表示,与LLM直接耦合,显著减少处理延迟,提高响应速度。...