UniTalker是推出的音频驱动3D面部动画生成模型,能根据输入的音频生成逼真的面部动作。采用统一的多头架构模型,用带有不同标注的数据集,支持多语言和多种音频类型的处理,包括语音和歌曲。不管是清晰的人声,还是带点噪音的歌声,UniTalker 都处理得很好。UniTalker可以同时给多个角色生成面部动作,不需要重新设计,非常灵活方便。

(图片来源网络,侵删)


UniTalker是推出的音频驱动3D面部动画生成模型,能根据输入的音频生成逼真的面部动作。采用统一的多头架构模型,用带有不同标注的数据集,支持多语言和多种音频类型的处理,包括语音和歌曲。不管是清晰的人声,还是带点噪音的歌声,UniTalker 都处理得很好。UniTalker可以同时给多个角色生成面部动作,不需要重新设计,非常灵活方便。

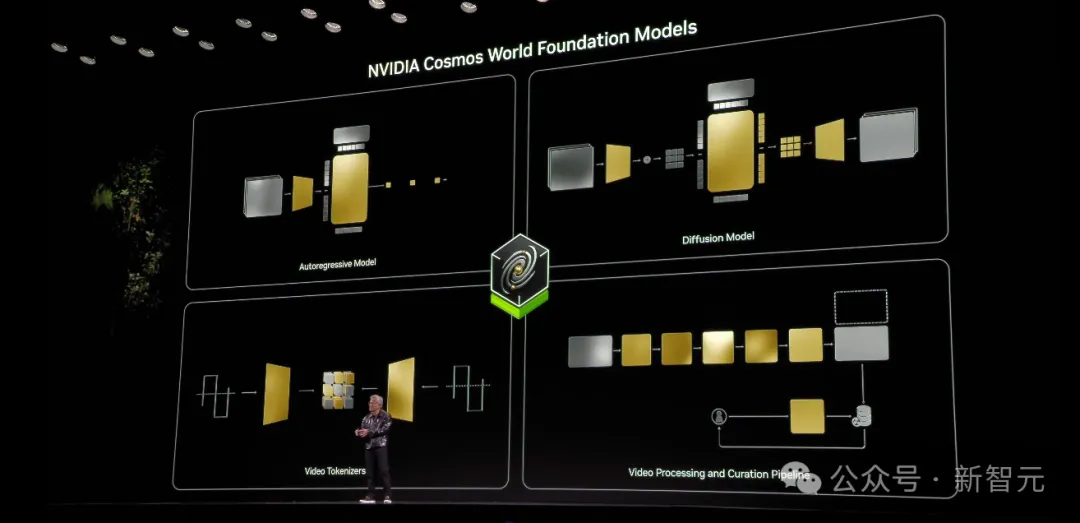
商汤破解世界模型秘诀,「日日新」实现AI大一统!原生融合模型破纪录双冠王 大模型发展到今天,下一步该走向何方?就在刚刚,商汤给出了答案——原生融合模态!最近的CES大会上,英伟达提出能理解世界的「世界模型」Cosmos...


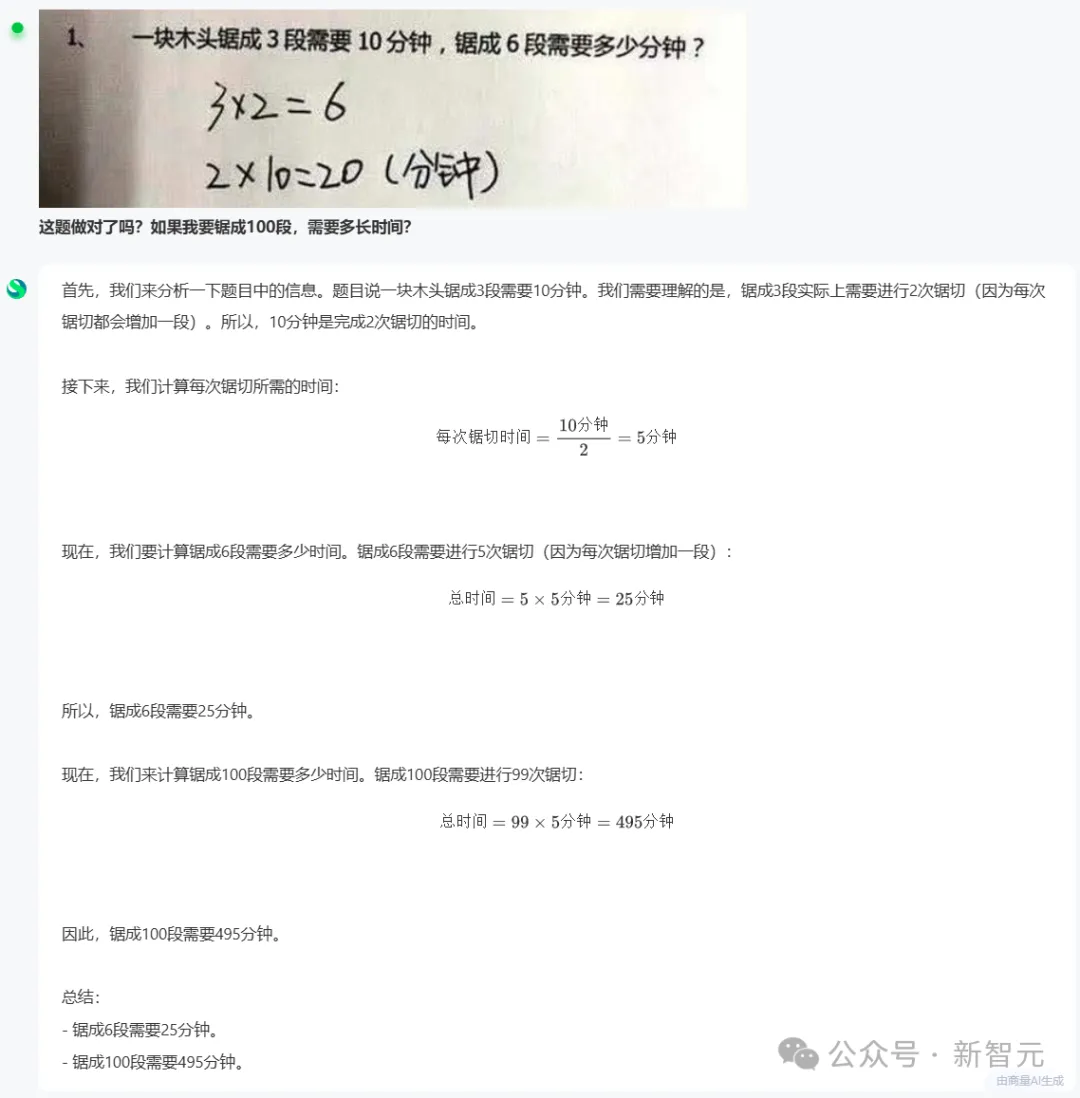
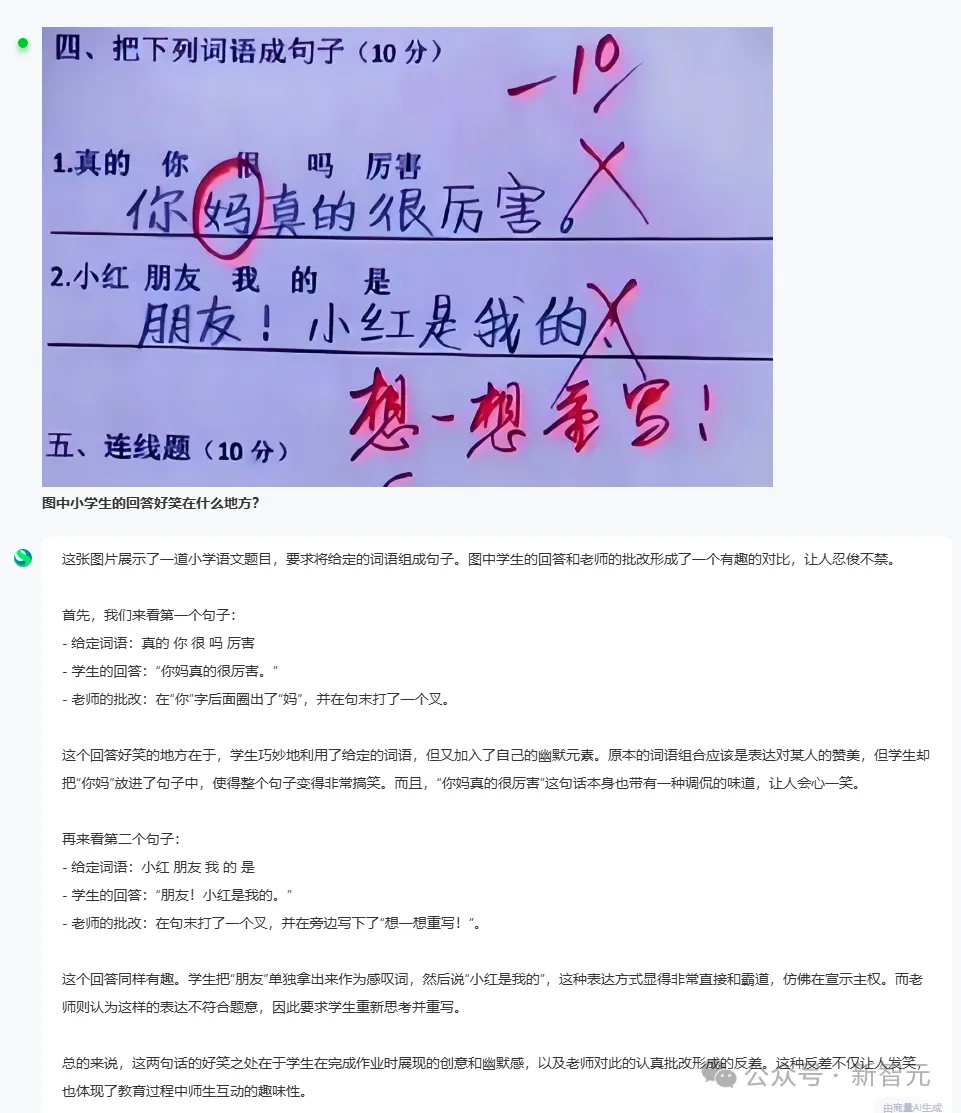

商汤SenseColor人像留色技术助攻联发科技Helio P90发布-2018年12月13日,联发科技在深圳正式发布新一代移动平台Helio P90。搭载全新超强AI引擎APU 2.0的Helio P90芯片拥有旗舰级AI...

全部评论
留言在赶来的路上...
发表评论