AI工具
发布文章-
发布了文章 2个月前
Teacher2Task – 谷歌推出的多教师学习框架
Teacher2Task是谷歌团队推出的多教师学习框架,引入教师特定的输入标记和重新构思训练过程,消除对手动聚合启发式方法的需求。框架不依赖聚合标签,将训练数据转化为N+1个任务,包括N个辅助任务预测每位教师的标记风格,及一...
-
发布了文章 2个月前
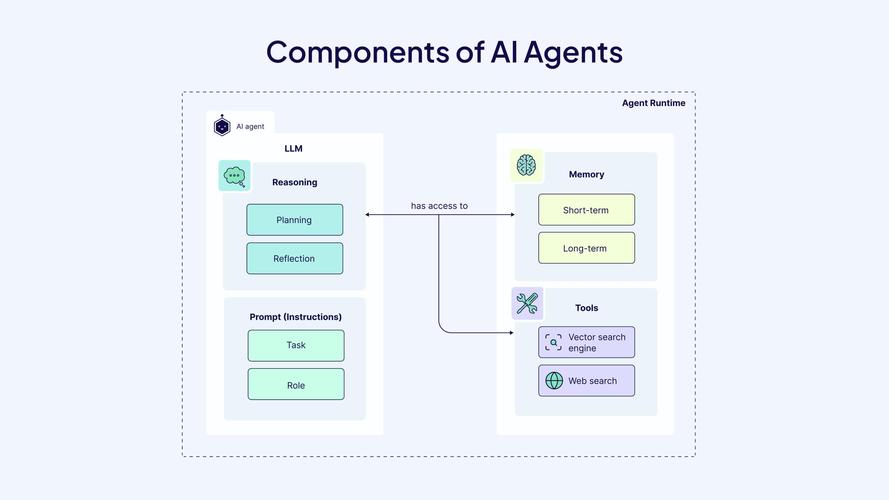
TaskWeaver – 微软推出代码优先的AI智能体框架
TaskWeaver是由微软推出的一个代码优先的AI智能体框架,专注于无缝规划和执行数据分析任务。基于代码片段解释用户请求,高效协调各种插件(以函数形式)执行数据分析任务,支持状态化的执行方式。TaskWeaver支持丰富的...
-
发布了文章 2个月前
Tarsier2 – 字节跳动推出的视觉理解大模型
Tarsier2是字节跳动推出的先进的大规模视觉语言模型(LVLM),生成详细且准确的视频描述,在多种视频理解任务中表现出色。模型通过三个关键升级实现性能提升,将预训练数据从1100万扩展到4000万视频文本对,丰富了数据量...
-
发布了文章 2个月前
TaoAvatar – 阿里推出的实时高清3D全身对话数字人技术
TaoAvatar是阿里巴巴集团研究团队推出的高保真、轻量级的3D全身对话虚拟人技术。基于3D高斯溅射技术,能生成照片级逼真的3D全身虚拟形象,支持高分辨率渲染且存储需求低。...
-
发布了文章 2个月前
Talker-baidu09Reasoner – 谷歌DeepMind推出的双思维AI代理架构
Talker-Reasoner是谷歌DeepMind推出的AI代理架构,借鉴人类的认知理论,将代理分为两个模块:Talker和Reasoner。Talker模拟人类的快速直觉思维(System 1),处理即时对话和反应;Re...
-
发布了文章 2个月前
Takin AudioLLM – 喜马拉雅推出的系列零样本语音生成模型
Takin AudioLLM是喜马拉雅Everest团队推出的一系列高质量零样本语音生成模型,包括Takin TTS、Takin VC和Takin Morphing。模型用最新的大型语言模型技术,专注于有声书制作,能生成接近...
-
发布了文章 2个月前
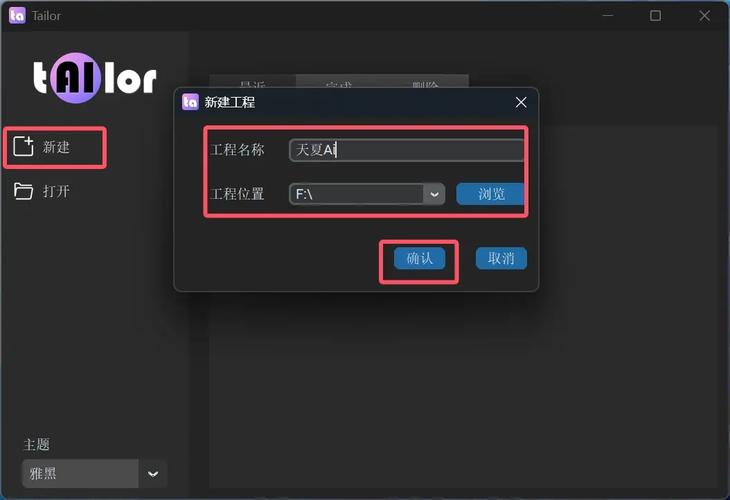
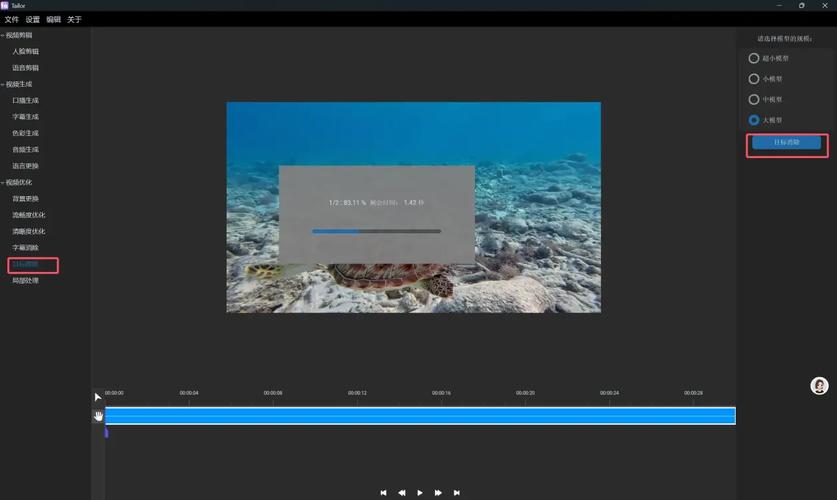
Tailor – 免费开源的AI视频编辑工具
Tailor是免费开源的AI视频编辑工具,集成了人脸识别、语音识别等智能技术,提供视频编辑、生成和优化三大功能。能实现人脸剪辑、语音剪辑、口播生成、字幕和色彩生成等,支持背景更换和流畅度、清晰度优化,让视频创作更高效。...
-
发布了文章 2个月前
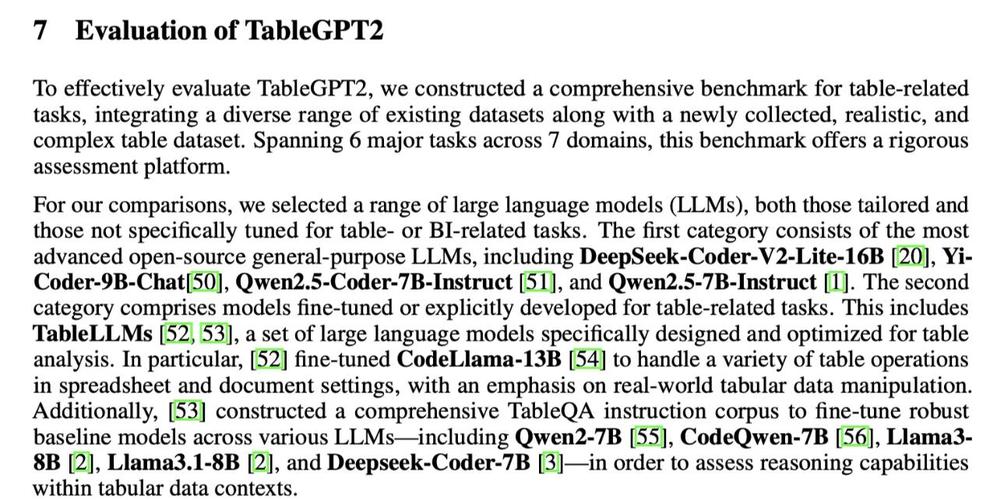
TableGPT2 – 浙大推出整合与处理表格数据的多模态大模型
TableGPT2是浙江大学推出的新型大型多模态模型,针对表格数据的整合与处理。首次将结构化数据作为独立模态进行训练,直接理解并操作数据库、Excel等数据,执行SQL查询、数据分析等任务。模型包含创新的表格编码器,强化对不...
-
发布了文章 2个月前
TRELLIS – 微软联合清华和中科大推出的高质量 3D 生成模型
TRELLIS是清华大学、中国科学技术大学和微软研究院推出的3D生成模型,基于Structured LATent(SLAT)表示法,从文本或图像提示中生成高质量、多样化的3D资产。模型融合稀疏的3D网格结构和从多视角提取的密...
-
发布了文章 2个月前
TPO – AI优化框架,动态调整推理模型的输出,更符合人类偏好
TPO(Test-Time Preference Optimization)是新型的AI优化框架,在推理阶段对语言模型输出进行动态优化,更符合人类偏好。TPO通过将奖励信号转化为文本反馈,将模型生成的优质响应标记为“选择”输...
-
发布了文章 2个月前
TPDM – 西湖大学联合北大等高校推出的时间预测扩散模型
TPDM(Time Prediction Diffusion Model)是西湖大学MAPLE实验室、南方科技大学、北京大学及西湖大学高等研究院先进技术研究所联合推出的图像生成模型,能自适应地调整去噪时间表,优化图像质量和生...
-
发布了文章 2个月前
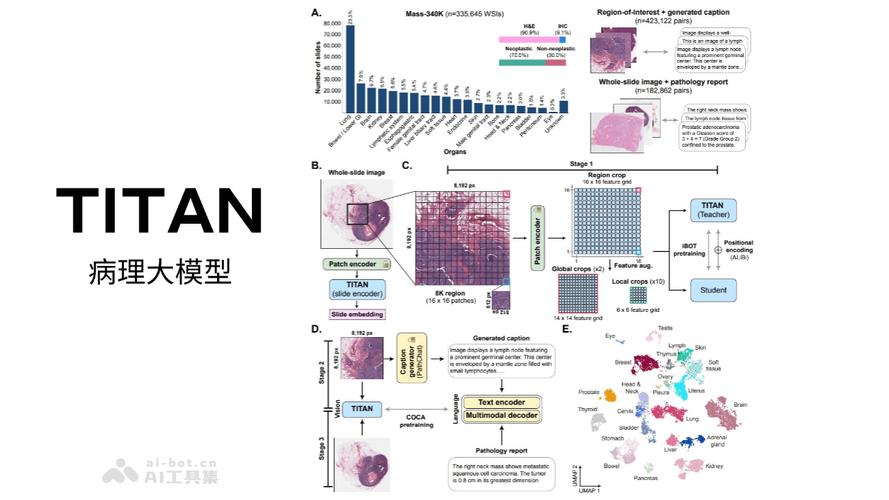
TITAN – 哈佛医学院研究推出的多模态全切片病理基础模型
TITAN是哈佛医学院研究团队开发的多模态全切片病理基础模型,通过视觉自监督学习和视觉-语言对齐预训练,能在无需微调或临床标签的情况下提取通用的切片表示,生成病理报告。它使用了335,645张全切片图像(WSIs)以及相应的...
-
发布了文章 2个月前
TIP-baidu09I2V – 超170万大规模真实文本和图像提示数据集
TIP-I2V是大规模真实文本和图像提示数据集,用在图像到视频生成领域。TIP-I2V包含超过170万独特的用户文本和图像提示,及五种SOTA图生视频模型生成的相应视频。数据集能推动更好、更安全的图像到视频模型的发展,帮助研...
-
发布了文章 2个月前
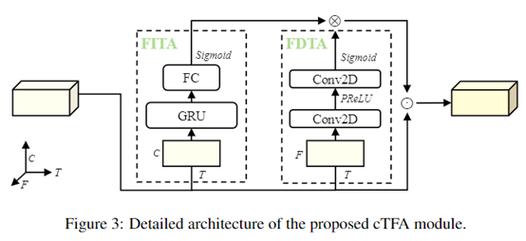
TIGER – 清华大学推出的轻量级语音分离模型
TIGER(Time-frequency Interleaved Gain Extraction and Reconstruction Network)是清华大学研究团队提出的轻量级语音分离模型,通过时频交叉建模策略,结合频...
-
发布了文章 2个月前
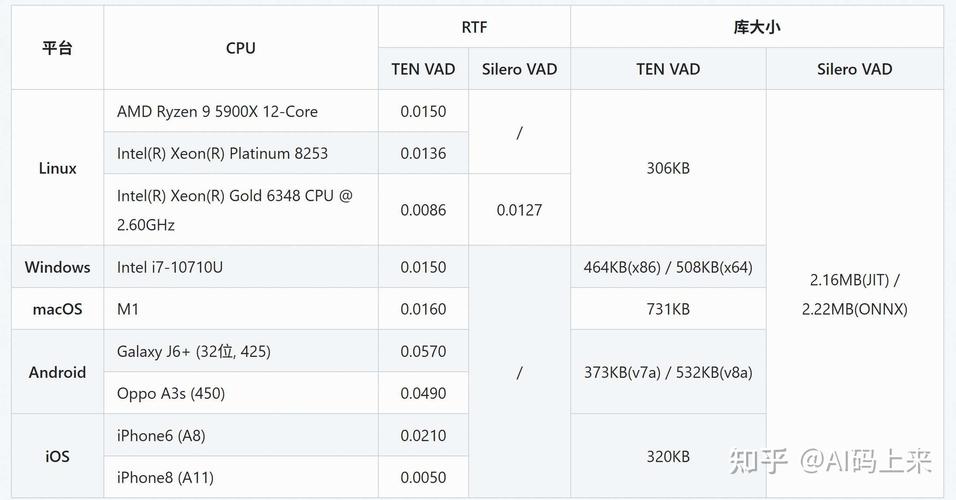
TEN VAD – AI实时语音活动检测系统,低延迟、轻量级、高精度
TEN VAD 是高性能的实时语音活动检测系统,专为企业级应用设计。TEN VAD能精确地检测音频流中的语音活动,具有低延迟、轻量级和高精度的特点。TEN VAD 基于先进的 AI 技术,如深度学习模型,快速区分语音和非语音...