AI工具
发布文章-
发布了文章 2个月前
Stagehand – AI网页浏览框架,提供简单和可扩展的网页自动化解决方案
Stagehand是简单和可扩展的AI网页浏览框架,是Playwright的继承者,提供act、extract和observe三个简单的API,支持自然语言驱动的网页操作。Stagehand提供一个轻量级、可配置、模块化的框...
-
发布了文章 2个月前
StableV2V – 中国科技大学开源的视频编辑项目
StableV2V是中国科技大学推出的开源视频编辑项目,基于文本、草图、图片等输入实现视频中物体的精准编辑和替换。项目用形状一致的编辑范式,基于三个主要组件:Prompted First-frame Editor(PFE)、...
-
发布了文章 2个月前
StableDrag – 腾讯联合南京大学推出的AI图像编辑框架
StableDrag是腾讯联合南京大学推出的AI图像编辑框架。让拖拽图片变得既稳又准,就像给图片装上了精准的GPS。无论你想怎么调整,StableDrag都能帮你准确无误地实现。通过点控制和手动拖拽,让图像编辑变得更加高效,...
-
发布了文章 2个月前
StableAnimator – 复旦联合微软等机构推出的端到端身份一致性视频扩散框架
StableAnimator是复旦大学、微软亚洲研究院、虎牙公司和卡内基梅隆大学共同推出的端到端高质量身份保持视频扩散框架。StableAnimator能根据一张参考图像和一系列姿态,无需任何后处理工具,直接合成高保真度且保...
-
发布了文章 2个月前
Stable Virtual Camera – Stability AI 等机构推出的 AI 模型,2D图像转3D视频
Stable Virtual Camera 是 Stability AI 推出的 AI 模型,能将 2D 图像转换为具有真实深度和透视感的 3D 视频。用户可以通过指定相机轨迹和多种动态路径(如螺旋、推拉变焦、平移等)来生成...
-
发布了文章 2个月前
Stable Video 3D (SV3D) – 多视角合成和3D生成模型,由Stability AI推出
Stable Video 3D(简称SV3D)是由Stability AI公司开发的一项先进的3D技术,能够从单张图片生成高质量的新视角视图和3D网格。该模型在之前发布的Stable Video Diffusion模型的基础...
-
发布了文章 2个月前
Stable Fast 3D – Stability AI推出的AI新模型,0.5秒将图片转为3D
Stable Fast 3D(SF3D)是Stability AI推出的一种创新3D网格重建技术,能在0.5秒内从单张图片生成高质量的3D模型。Stable Fast 3D采用先进的Transformer网络,结合快速UV展...
-
发布了文章 2个月前
Stable Diffusion整合包 – 秋葉发布的SD绘画本地部署解决方案
Stable Diffusion整合包是B站UP主秋葉aaaki发布的SD绘画本地部署解决方案,包含了Stable Diffusion WebUI、必要的运行环境、预装模型以及一些常用插件的集合。整合包的目的是为了让新手用户...

-
发布了文章 2个月前
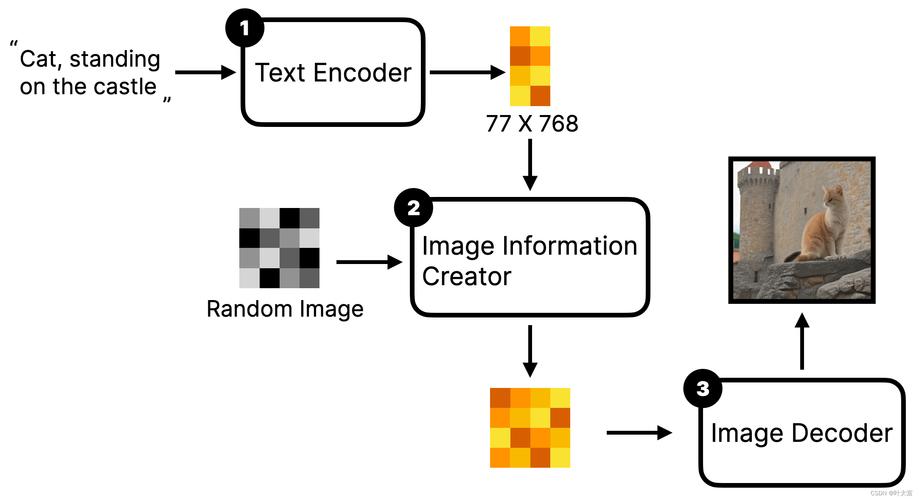
Stable Diffusion 3.5 – Stability AI最新开源的图像生成模型
Stable Diffusion 3.5是Stability AI公司最新推出的一系列先进的AI图像生成模型,包括Stable Diffusion 3.5 Large、Stable Diffusion 3.5 Large T...
-
发布了文章 2个月前
Stable Diffusion 3 – Stability AI推出的新一代图像生成模型
Stable Diffusion 3 是由 Stability AI 开发的一款先进的文本到图像生成模型,是 Stable Diffusion 系列模型的最新迭代,旨在通过文本提示生成高质量的图像。该模型相较于上代模型在多个...
-
发布了文章 2个月前
Stable Audio Open Small – Stability AI和Arm推出的文本到音频生成模型
Stable Audio Open Small 是 Stability AI 与 Arm 合作推出的轻量级文本到音频生成模型。基于 Stable Audio Open 模型,参数量从11亿减少到3.41亿,生成速度更快,能在...
-
发布了文章 2个月前
Stability AI开源Stable Diffusion 3 Medium文生图模型
人工智能初创公司Stability AI宣布正式开源发布其最新的文本到图像生成模型——Stable Diffusion 3 Medium(SD3 Medium)。Stable Diffusion 3 Medium 包含 20...
-
发布了文章 2个月前
Spirit LM – Meta推出多模态语言模型,无缝集成语音和文本
Spirit LM是由Meta AI团队推出的一种多模态语言模型,能无缝地混合文本和语音数据。Spirit LM基于一个预训练的文本语言模型,用持续在文本和语音单元上的训练扩展到语音模态。模型有两个版本:基础版(BASE)和...
-
发布了文章 2个月前
SpeechGPT 2.0-baidu09preview – 复旦大学推出的端到端实时语音交互模型
SpeechGPT 2.0-preview 是复旦大学 OpenMOSS 团队推出的拟人化实时交互系统,基于百万小时级中文语音数据训练,采用端到端架构,实现了语音与文本模态的高度融合。模型具有拟人口语化表达、百毫秒级低延迟响...
-
发布了文章 2个月前
Speech-baidu0902 – MiniMax 推出的新一代文本转语音模型
Speech-02 是 MiniMax 推出的新一代文本到语音(TTS)模型。模型基于回归 Transformer 架构,实现零样本语音克隆,仅需几秒参考语音能生成高度相似的目标语音。Flow-VAE 架构增强了语音生成的信...