AI工具
发布文章-
发布了文章 2个月前
Speech 2.5 – MiniMax推出的新一代语音生成模型
Speech 2.5 是 MiniMax 推出的新一代语音生成模型,在多语种表现力、音色复刻和语言覆盖范围上实现重大突破。模型支持40种语言,能精准还原不同语言和口音的细节,复刻音色时保留风格与情绪,跨语种切换依然逼真。...
-
发布了文章 2个月前
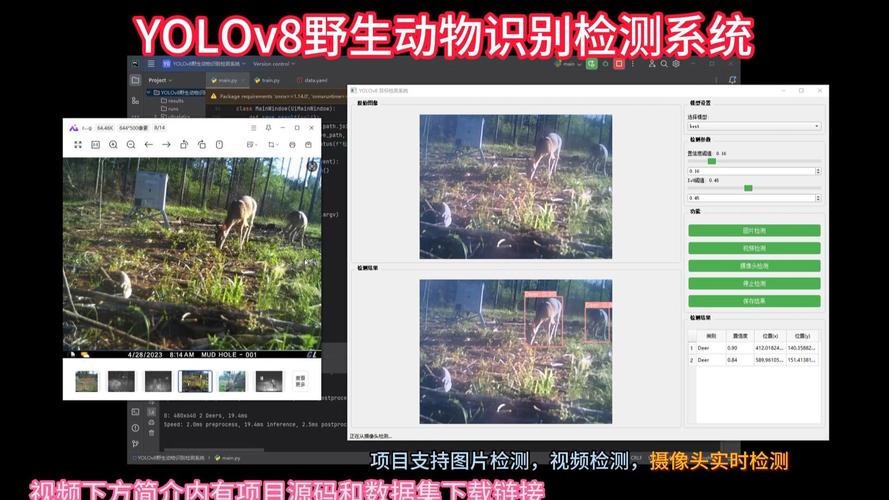
SpeciesNet – Google 开源的动物物种识别 AI 模型
SpeciesNet 是 Google 开源的人工智能模型,通过分析相机陷阱拍摄的照片来识别动物物种。基于超过 6500 万张图像训练而成,能识别超过 2000 种标签,包括动物物种、分类单元以及非动物对象。...
-
发布了文章 2个月前
Speakr – 免费AI会议助手,本地完成数据处理
Speakr是开源免费的AI会议助手,支持确保数据绝对私密的前提下,自动化完成会议录音转写、内容摘要提炼与智能问答。Speakr无需联网就能运行,所有数据处理均在本地完成,彻底杜绝商业机密或敏感对话泄露的风险。...
-
发布了文章 2个月前
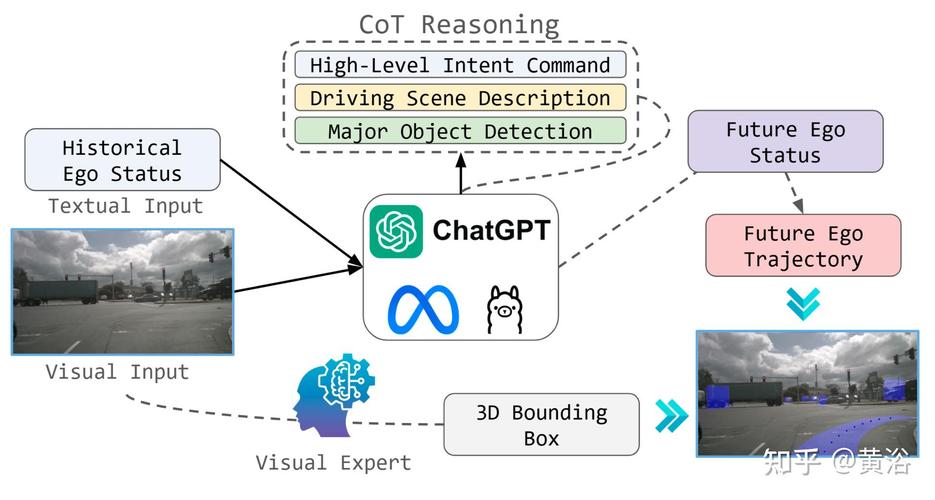
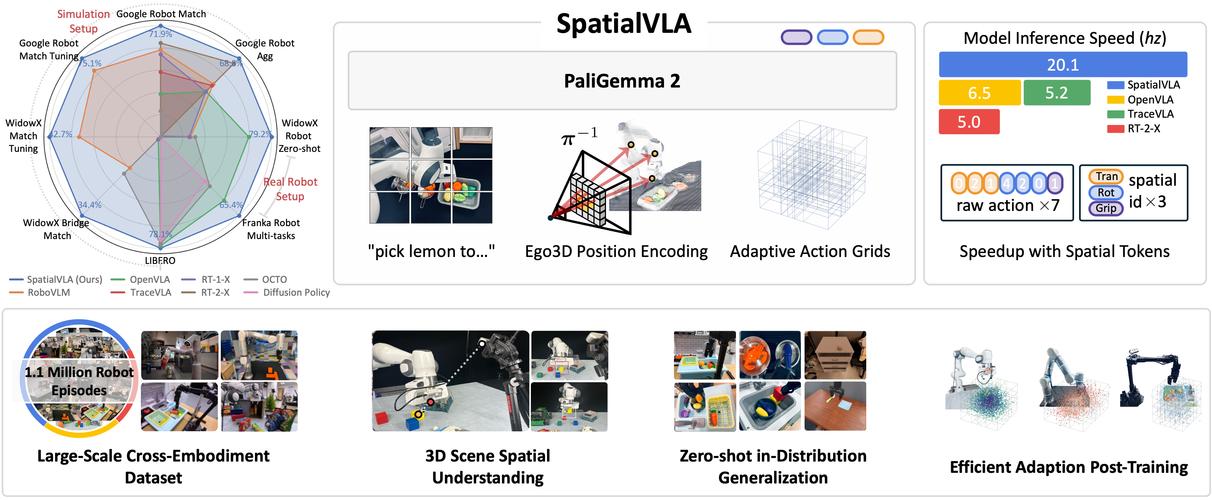
SpatialVLA – 上海 AI Lab 联合上科大等推出的空间具身通用操作模型
SpatialVLA 是上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构共同推出的新型空间具身通用操作模型,基于百万真实数据预训练,为机器人赋予通用的3D空间理解能力。SpatialVLA基于Ego3D位置编码...
-
发布了文章 2个月前
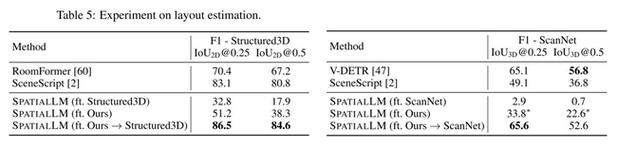
SpatialLM – 群核科技开源的空间理解多模态模型
SpatialLM 是群核科技开源的空间理解多模态模型,赋予机器人和智能系统类似人类的空间认知能力。通过分析普通手机拍摄的视频,能重建出详细的 3D 场景布局,标注出房间结构、家具摆放、通道宽度等信息。...
-
发布了文章 2个月前
SpatialLM 1.5 – 群核科技推出的空间语言模型
SpatialLM 1.5 是群核科技推出的强大的空间语言模型。模型基于大语言模型训练,能理解自然语言指令,输出包含空间结构、物体关系和物理参数的空间语言。用户能通过对话交互系统 SpatialLM-Chat,用简单文本描述...
-
发布了文章 2个月前
SpatialGen – 群核科技开源的3D场景生成模型
SpatialGen 是群核科技开源的 3D 场景生成模型。模型基于扩散模型架构,支持根据文字描述、参考图像和 3D 空间布局,生成时空一致的多视角图像,且能进一步得到 3D 高斯场景并渲染漫游视频。...
-
发布了文章 2个月前
Spatial-baidu09RAG – 埃默里大学等机构推出的空间推理能力框架
Spatial-RAG(Spatial Retrieval-Augmented Generation)是美国埃默里大学、德克萨斯大学奥斯汀分校推出的用在提升大型语言模型(LLMs)空间推理能力的框架。结合稀疏空间检索(基于空...
-
发布了文章 2个月前
Spark-baidu09TTS – AI文本转语音工具,支持中英零样本语音克隆
Spark-TTS 是SparkAudio 团队开源的基于大型语言模型(LLM)的高效文本转语音(TTS)工具, 无需额外的生成模型,直接从 LLM 预测的编码中重建音频,实现零样本文本到语音的转换。Spark-TTS 支持...
-
发布了文章 2个月前
Sparc3D – 南洋理工等机构推出的3D模型生成框架
Sparc3D是南洋理工大学联合Sensory Universe和帝国理工学院推出的用在高分辨率3D模型生成框架,解决传统3D生成方法中细节丢失和效率低下的问题。框架结合稀疏可变形Marching Cubes表示(Sparc...
-
发布了文章 2个月前
Soundwave – 港中文深圳开源的语音理解大模型
Soundwave是香港中文大学(深圳)开源的语音理解大模型,专注于语音与文本的智能对齐和理解。通过创新的对齐适配器和压缩适配器技术,有效解决了语音和文本在表示空间上的差异,实现了高效的语音特征压缩,能更好地处理语音任务。...
-
发布了文章 2个月前
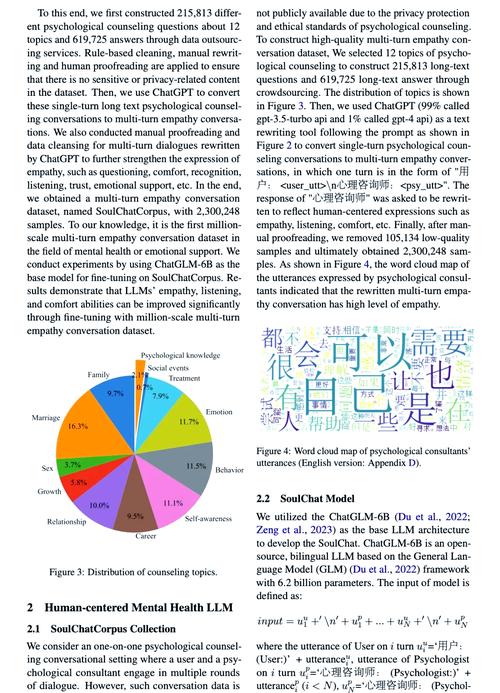
SoulChat2.0 – 华南理工大学推出的心理咨询师数字孪生大语言模型
SoulChat2.0是华南理工大学未来技术学院-广东省数字孪生人重点实验室基于SoulChat1.0模型推出的心理咨询师数字孪生大语言模型。首次定义了特定心理咨询师的数字孪生任务,旨在通过模拟真实心理咨询师的语言风格和疗法...
-
发布了文章 2个月前
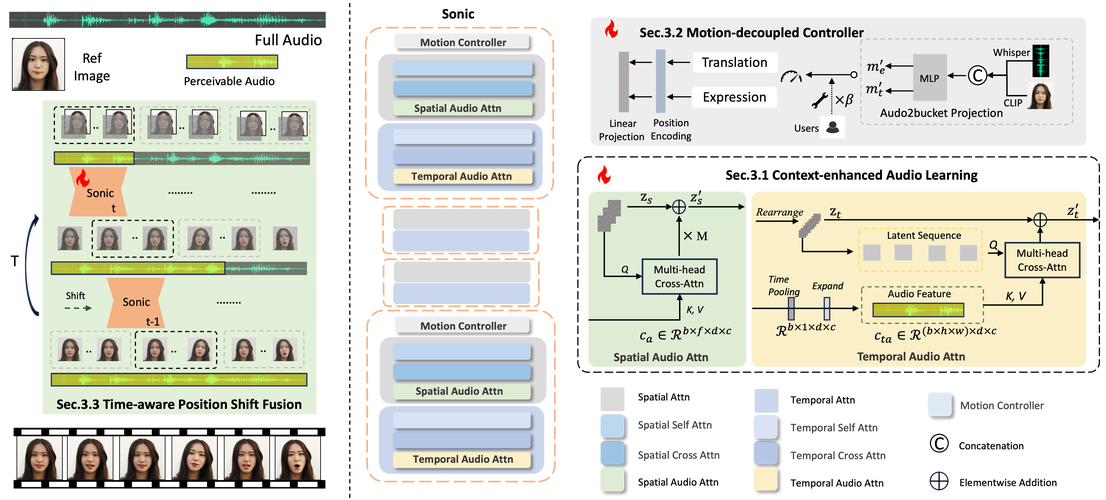
Sonic – 腾讯联合浙大推出的音频驱动肖像动画框架
Sonic是腾讯和浙江大学推出的音频驱动肖像动画框架,基于全局音频感知生成逼真的面部表情和动作。Sonic基于上下文增强音频学习和运动解耦控制器,分别提取音频片段内的长期时间音频知识和独立控制头部与表情运动,增强局部音频感知...
-
发布了文章 2个月前
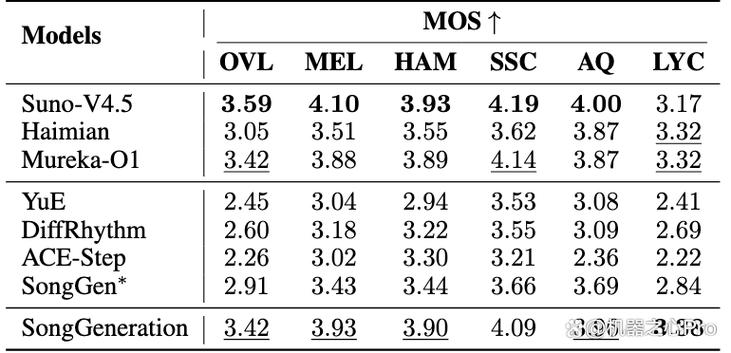
SongGeneration – 腾讯AI Lab开源的音乐生成大模型
SongGeneration是腾讯AI Lab推出的AI音乐生成大模型。模型支持解决音乐AIGC领域中的音质、音乐性与生成速度等关键问题,SongGeneration基于LLM-DiT融合架构,显著提升音质表现和生成速度,生...
-
发布了文章 2个月前
SongGen – 上海 AI Lab 和北航、港中文推出的歌曲生成模型
SongGen是上海AI Lab、北京航空航天大学和香港中文大学推出的单阶段自回归Transformer模型,用在从文本生成歌曲。SongGen基于歌词和描述性文本(如乐器、风格、情感等)作为输入,支持混合模式和双轨模式两种...