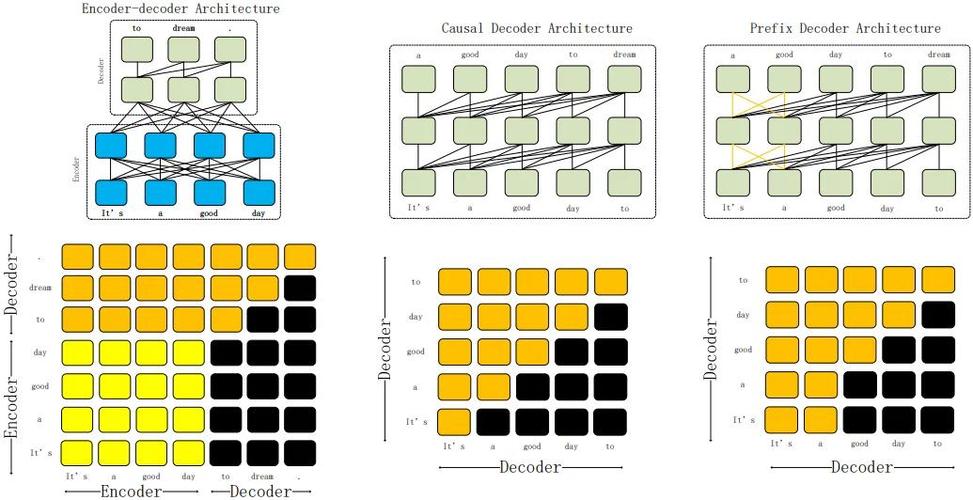
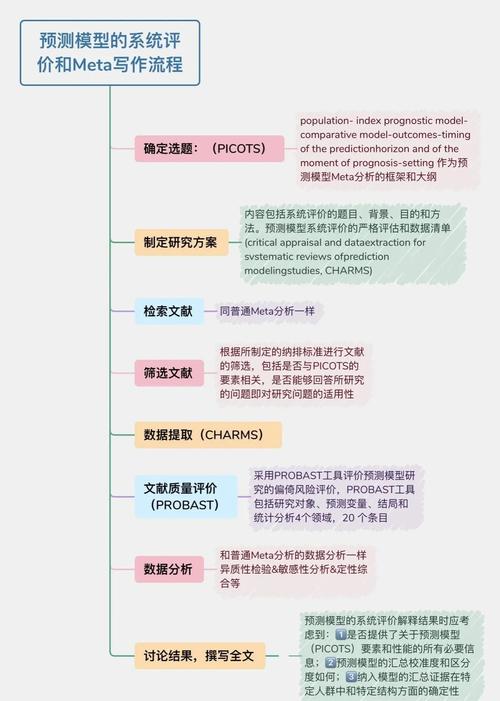
AI工具
发布文章-
发布了文章 2个月前
SigLIP 2 – 谷歌 DeepMind 推出的多语言视觉语言编码器模型
SigLIP 2 是Google DeepMind 提出先进的多语言视觉-语言模型 ,是 SigLIP 的升级版本,提升图像与文本之间的对齐能力。通过改进的训练方法和架构,显著增强了模型在多语言理解、零样本分类、图像-文本检...
-
发布了文章 2个月前
ShowUI – 新加坡国立联合微软推出用于 GUI 自动化的视觉-baidu09语言-baidu09操作模型
ShowUI是新加坡国立大学Show Lab和微软共同推出的视觉-语言-行动模型,能提升图形用户界面(GUI)助手的工作效率。模型基于UI引导的视觉令牌选择减少计算成本,用交错视觉-语言-行动流统一GUI任务中的多样化需求,...
-
发布了文章 2个月前
Show-baidu09o – 新加坡国立Show Lab联合字节推出的多模态理解与生成的统一模型
Show-o是集成了多模态理解和生成的统一Transformer模型。通过结合自回归和离散扩散建模,能灵活处理包括视觉问答、文本到图像生成、文本引导的修复和扩展,混合模态生成在内的广泛视觉语言任务。Show-o模型在多模态理...
-
发布了文章 2个月前
ShotAdapter – Adobe联合UIUC推出的多镜头视频生成框架
ShotAdapter是Adobe联合UIUC推出的用在文本到多镜头视频生成的框架,基于微调预训练的文本到视频模型,引入过渡标记和局部注意力掩码策略,实现对多镜头视频的生成。框架能确保角色在不同镜头中的身份一致性,支持用户用...
-
发布了文章 2个月前
Shandu – AI研究工具,自动进行多层次信息挖掘和分析
Shandu 是开源的 AI 研究自动化工具,结合了 LangChain 和 LangGraph 技术,能自动化地进行多层次信息挖掘和分析,生成结构化的研究报告。Shandu 的核心功能包括递归探索、多引擎搜索、智能网页爬取...
-
发布了文章 2个月前
Shadow – 开源的AI编程Agent,提供实时任务状态更新
Shadow 是开源的AI编程Agent,能帮助开发者理解、推理并贡献现有的代码库。Shadow 支持 GitHub 仓库集成,能生成拉取请求、管理分支,提供实时任务状态更新。Shadow 提供多语言模型支持,具备代码生成、...
-
发布了文章 2个月前
SepLLM – 基于分隔符压缩加速大语言模型的高效框架
SepLLM是香港大学、华为诺亚方舟实验室等机构联合提出的用于加速大语言模型(LLM)的高效框架,通过压缩段落信息并消除冗余标记,显著提高了模型的推理速度和计算效率。SepLLM的核心是利用分隔符(如标点符号)对注意力机制的...
-
发布了文章 2个月前
SeniorTalk – 智源联合南开开源的超高龄老年人中文对话语音数据集
SeniorTalk 是智源研究院联合南开大学计算机学院人类语言技术实验室(HLT Lab)推出的全球首个中文超高龄老年人对话语音数据集。数据集包含202位75岁及以上超高龄老年人的语音数据,总时长达到 55.53小时。...
-
发布了文章 2个月前
Self-baidu09Taught Evaluators – Meta推出的新型模型评估方法
Self-Taught Evaluators是一种新型的模型评估方法,基于自我训练的方式提高大型语言模型(LLM)的评估能力,无需人工标注数据。从未经标记的指令开始,用迭代自我改进方案生成对比模型输出。用LLM作为裁判,生成...
-
发布了文章 2个月前
Self-baidu09Lengthen – 阿里千问推出的提升输出长度迭代训练框架
Self-Lengthen是阿里巴巴千问团队推出的创新的迭代训练框架,能提升大型语言模型(LLMs)生成长文本的能力。框架基于两个角色,生成器和扩展器协同工作,生成器负责生成初始响应,扩展器将响应拆分、扩展产生更长的文本。...
-
发布了文章 2个月前
Self Forcing – Adobe联合德克萨斯大学推出的视频生成模型
Self Forcing 是 Adobe Research 与德克萨斯大学奥斯汀分校联合推出的新型自回归视频生成算法,解决传统生成模型在训练与测试时的暴露偏差问题。通过在训练阶段模拟自生成过程,以先前生成的帧为条件生成后续帧...
-
发布了文章 2个月前
Seer – 上海 AI Lab 联合北大等机构推出的端到端操作模型
Seer是由上海AI实验室、北京大学计算机科学与技术学院、北京大学软件与微电子学院等机构联合推出的端到端操作模型,实现机器人视觉预测与动作执行的高度协同。模型结合历史信息和目标信号(如语言指令),预测未来时刻的状态,用逆动力...
-
发布了文章 2个月前
Seedream 3.0 – 字节推出的 AI 图片生成模型,精准生成复杂中文内容
Seedream 3.0(即梦3.0)是字节跳动推出的AI图片生成模型,模型支持原生 2K 分辨率图像输出,快速生成高品质图像,仅需 3 秒。模型在小字生成与排版、美感与结构准确性等方面有显著提升,优化复杂文本排版和小字体高...
-
发布了文章 2个月前
Seedream 2.0 – 字节豆包推出的原生中英双语图像生成模型
Seedream 2.0 是字节跳动豆包大模型团队推出的原生中英双语图像生成模型,解决现有模型在文本渲染、文化理解等方面的不足。模型通过自研的双语大语言模型(LLM)作为文本编码器,能直接从海量数据中学习本土知识,生成具有准...
-
发布了文章 2个月前
Seedance 1.0 – 字节跳动推出的视频生成模型
Seedance 1.0 是字节跳动Seed团队推出的视频生成基础模型。模型支持文字与图片输入,能生成多镜头无缝切换的1080p高品质视频,具备原生多镜头叙事能力,能进行远中近景画面切换,主体运动稳定,画面自然。...