AI工具
发布文章-
发布了文章 2个月前
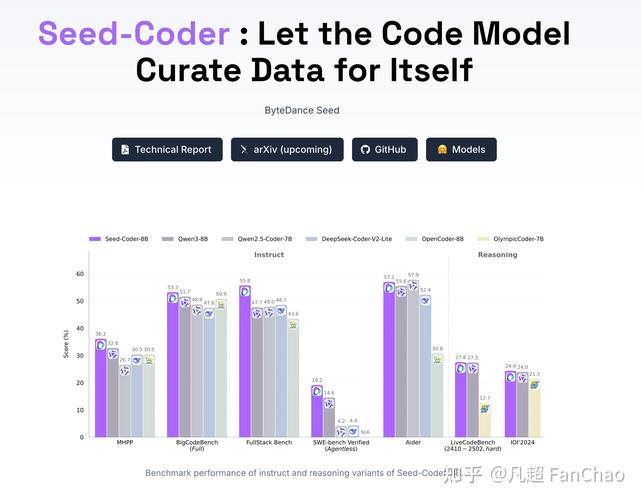
Seed-baidu09Coder – 字节跳动开源的代码模型系列
Seed-Coder是字节跳动开源的8B规模代码模型系列,提升代码生成与理解能力。包含Base、Instruct和Reasoning三个版本,分别适用于代码补全、指令遵循和复杂推理任务。...
-
发布了文章 2个月前
Seed-baidu09ASR – 字节跳动推出的AI语音识别模型
Seed-ASR是字节跳动开发的一款基于大型语言模型(LLM)的语音识别(ASR)模型。在超过2000万小时的语音数据和近90万小时的配对ASR数据上训练,支持普通话和13种中国方言的转录,能识别英语和其他7种外语的语音。...
-
发布了文章 2个月前
Seed LiveInterpret 2.0 – 字节跳动Seed推出的同声传译模型
Seed LiveInterpret 2.0 是字节跳动Seed团队推出的端到端同声传译模型,支持中英双向翻译。具备接近真人水平的翻译准确率和极低的延迟,能实现“边听边说”的实时翻译。模型基于全双工语音生成理解框架,支持多人...
-
发布了文章 2个月前
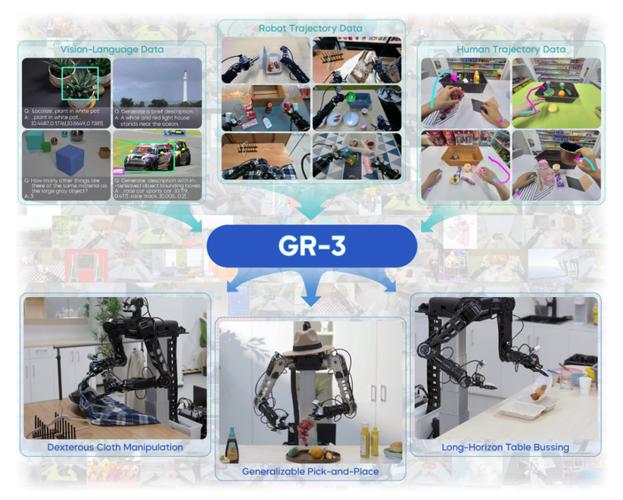
Seed GR-baidu093 – 字节跳动推出通用机器人模型
Seed GR-3 是字节跳动 Seed 团队推出的通用机器人模型,具备高泛化能力、长程任务处理能力和柔性物体操作能力。...
-
发布了文章 2个月前
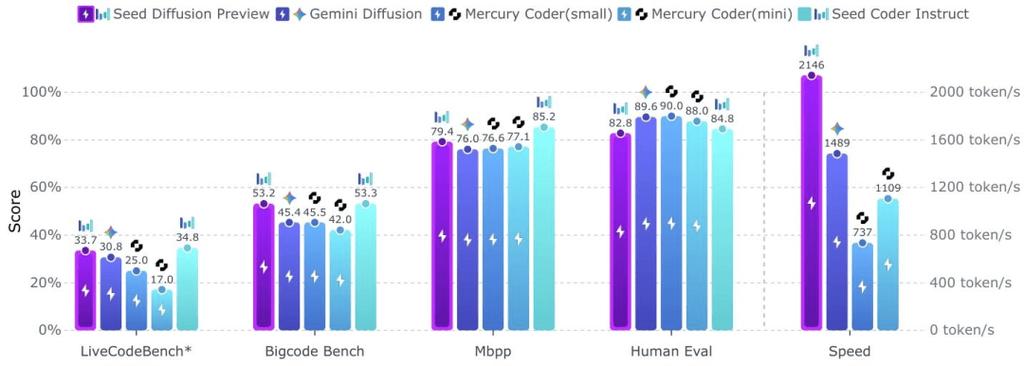
Seed Diffusion – 字节跳动推出的扩散语言模型
Seed Diffusion是字节跳动Seed团队推出的实验性扩散语言模型,专注于代码生成任务。模型通过两阶段扩散训练、约束顺序学习和强化高效并行解码等关键技术,实现显著的推理加速。...
-
发布了文章 2个月前
See3D – 智源研究院开源的无标注视频学习3D生成模型
See3D(See Video, Get 3D)是北京智源人工智能研究院推出的3D生成模型,能基于大规模无标注的互联网视频进行学习,实现从视频中生成3D内容。与传统依赖相机参数的3D生成模型不同,See3D采用视觉条件技术,...
-
发布了文章 2个月前
Second Me – 心识宇宙开源的 AI 身份模型
Second Me 是心识宇宙(Mindverse)推出的开源AI身份模型,支持创建完全私有且深度个性化的AI代理,代表用户的“真实自我”。Second Me 提供 Chat Mode 和 Bridge Mode 两种互动模...

-
发布了文章 2个月前
Seaweed-baidu097B – 字节推出的视频生成模型
Seaweed-7B 是字节跳动团队推出的视频生成模型,拥有约 70 亿参数。Seaweed-7B具备强大的视频生成能力。模型支持从文本描述、图像或音频生成高质量的视频内容,支持多种分辨率和时长,广泛应用于视频创作、动画生成...
-
发布了文章 2个月前
Seaweed APT2 – 字节跳动推出的AI视频生成模型
Seaweed APT2是字节跳动推出的创新的AI视频生成模型,通过自回归对抗后训练(AAPT)技术,将双向扩散模型转化为单向自回归生成器,实现高效、高质量的视频生成。...
-
发布了文章 2个月前
Seaweed APT – 字节跳动推出的单步图像和视频生成项目
Seaweed APT是字节跳动推出的对抗性后训练(Adversarial Post-Training)模型,能实现图像和视频的一站式生成。Seaweed APT基于预训练的扩散模型,直接对真实数据进行对抗性训练,而非用预训...
-
发布了文章 2个月前
SearchAgent-baidu09X – 南开等机构推出的高效推理框架
SearchAgent-X 是南开大学和伊利诺伊大学厄巴纳香槟分校(UIUC)研究人员推出的高效推理框架,能提升基于大型语言模型(LLM)的搜索Agent的效率。...
-
发布了文章 2个月前
Search-baidu09o1 – 人大联合清华推出自主知识检索增强的推理框架
Search-o1是中国人民大学和清华大学推出的创新框架,能提升大型推理模型(LRMs)在面对复杂问题时的推理能力。基于整合代理检索增强生成(RAG)机制和Reason-in-Documents模块,让LRMs在推理过程中动...
-
发布了文章 2个月前
ScriptViz – 斯坦福大学推出的剧本可视化AI辅助工具
ScriptViz是由斯坦福大学研究人员推出的一款剧本可视化辅助工具,基于大型电影数据库MovieNet,根据剧本文本和对话检索出相匹配的电影画面,将编剧的文字描述转换成具体的视觉图像。工具提供对视觉元素的精确控制,支持编剧...
-
发布了文章 2个月前
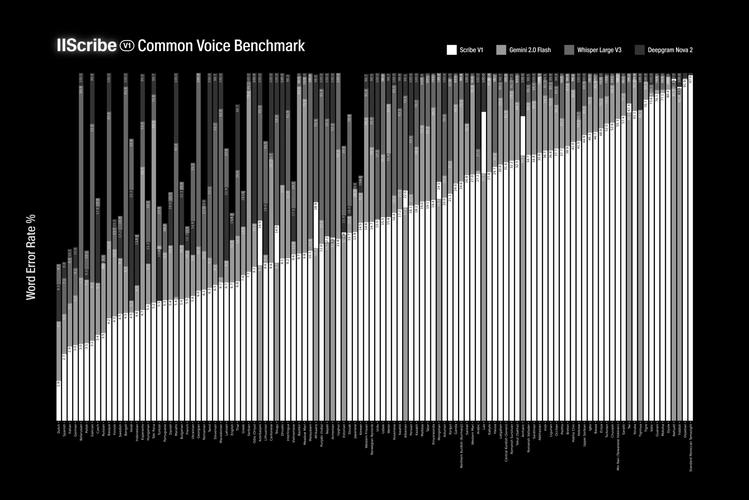
Scribe – ElevenLabs 推出的高精度语音转文本模型
Scribe 是 ElevenLabs 推出的高精度语音转文本模型,专为多语言和复杂音频环境设计。支持99种语言,英语和意大利语的转录准确率分别达到96.7%和98.7%,在小语种上也有出色表现。...
-
发布了文章 2个月前
ScribbleDiff – 开源的涂鸦内容转换成图像的生成技术
ScribbleDiff是一种先进的文本到图像生成技术,基于用户简单涂鸦的视觉提示指导图像的生成过程。通过分析涂鸦确保生成的图像中的对象方向与用户涂鸦的方向一致,并将涂鸦扩展生成更完整和细致的图像。...