AI工具
发布文章-
发布了文章 2个月前
Screenshot to Code – AI将截图转换为网页代码的开源项目
Sscreenshot to Code是一个开源的项目,利用人工智能技术(GPT-4V 和 DALL·E 3)将用户的屏幕截图转换为前端网页代码。项目的核心功能是自动化网页设计的编码过程,使得开发者能够通过提供网页的截图,快...
-
发布了文章 2个月前
ScreenCoder – 开源的智能UI截图生成前端代码工具
ScreenCoder 是开源的智能 UI 截图转代码系统,支持将任何设计截图快速转换为整洁、可编辑的 HTML/CSS 代码。ScreenCoder用模块化多智能体架构,结合视觉理解、布局规划和代码合成技术,生成高精度、语...
-
发布了文章 2个月前
ScreenAgent – 基于视觉语言模型的计算机控制智能体
ScreenAgent是一个由吉林大学人工智能学院的研究团队开发的计算机控制智能体,该智能体是基于视觉语言模型(VLM)构建的,能够与真实计算机屏幕进行交互。ScreenAgent的核心功能是通过观察屏幕截图,并输出相应的鼠...
-
发布了文章 2个月前
ScreenAI – 谷歌推出的可读屏AI视觉模型,可理解UI和信息图表
ScreenAI是一个由谷歌的研究团队推出的可读屏AI视觉语言模型,专门设计用于理解和处理用户界面(UI)和信息图表。该模型基于PaLI架构结合了视觉和语言处理的能力,并借鉴了Pix2Struct的灵活拼贴策略,使其能够理解...
-
发布了文章 2个月前
ScrapeGraphAI – AI网络爬虫工具,自动分析目标网页结构提取关键数据
ScrapeGraphAI 是基于大型语言模型(LLM)驱动的智能网络爬虫工具包,专注于从各类网站和HTML内容中高效提取结构化数据。具备三大核心功能:SmartScraper可根据用户提示精准抓取网页中的结构化信息;Sea...
-
发布了文章 2个月前
ScholarCopilot – 滑铁卢与卡内基梅隆大学联合推出的AI学术写作助手
ScholarCopilot 是加拿大滑铁卢大学与卡内基梅隆大学的研究团队开发的专为学术写作设计的人工智能工具,基于 Qwen-2.5-7B 模型,通过动态检索引用和联合优化生成与引用的方式,能精准地生成带有准确引用的学术文...
-
发布了文章 2个月前
Scenethesis – 英伟达推出的交互式3D场景生成框架
Scenethesis 是 NVIDIA 推出的创新框架,用在从文本生成交互式 3D 场景。框架结合大型语言模型(LLM)和视觉感知技术,基于多阶段流程实现高效生成,用 LLM 进行粗略布局规划,基于视觉模块细化布局生成图像...
-
发布了文章 2个月前
ScaleMCP – 普华永道推出的动态MCP工具检索器
ScaleMCP是普华永道推出的工具选择方法,动态的为大型语言模型(LLM)Agents 配备Model Context Protocol(MCP)工具。基于自动同步工具存储系统与MCP服务器,解决现有框架依赖手动更新本地工...
-
发布了文章 2个月前
Satori – 开源的大语言推理模型,具备自回归搜索和自我纠错能力
Satori 是 MIT、哈佛大学等机构研究者推出的 7B 参数的大型语言模型,专注于提升推理能力。基于Qwen-2.5-Math-7B,Satori通过小规模的格式微调和大规模的增强学习实现了最先进的推理性能。采用行动思维...
-
发布了文章 2个月前
Sapiens – Meta推出的AI视觉模型,能理解图片和视频中的人类动作
Sapiens是Meta实验室推出的AI视觉模型,专为理解图片和视频中的人类动作设计。支持二维姿势预估、身体部位分割、深度估计和表面法线预测等任务,采用视觉转换器架构。...
-
发布了文章 2个月前
Sana – 英伟达、麻省和清华联合推出的文本到图像生成框架
SANA是由NVIDIA、麻省理工学院和清华大学共同推出的文本到图像生成框架,能高效地生成高达4096×4096分辨率的高清晰度图像。SANA基于深度压缩自编码器、线性扩散变换器(Linear DiT)、仅解码器的小型语言模...
-
发布了文章 2个月前
Samsung Gauss2 – 三星推出的第二代多模态生成式AI模型
Samsung Gauss2是三星公司推出的第二代多模态生成式AI模型,能提升Galaxy AI功能的性能和效率。Samsung Gauss2能同时处理文本、代码和图像等多种数据类型。Samsung Gauss2分为三个版本...
-
发布了文章 2个月前
SafeEar – 浙大和清华联合开源的AI音频伪造检测框架
SafeEar是由浙江大学和清华大学联合开发的AI音频伪造检测框架,保护用户隐私的同时检测音频伪造。采用基于神经音频编解码器的解耦模型,分离语音的声学信息和语义信息,用声学信息进行检测,有效防止隐私泄露。...
-
发布了文章 2个月前
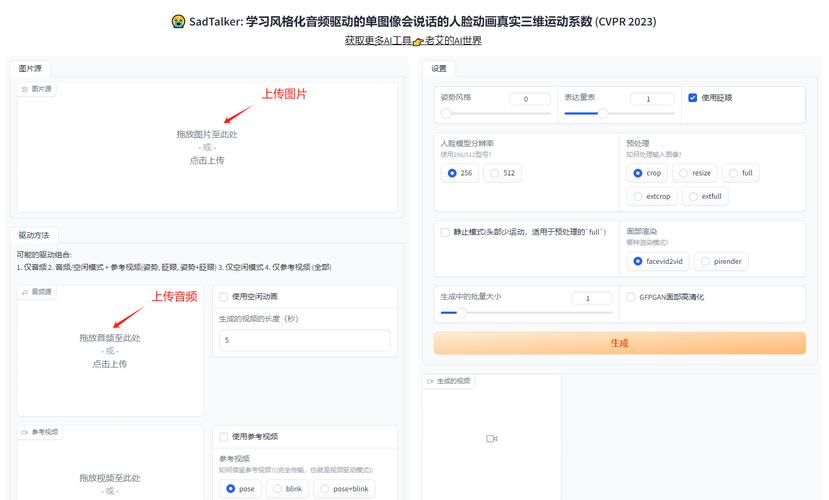
SadTalker – 开源AI数字人项目,一键让照片说话
SadTalker是西安交通大学、腾讯AI实验室和蚂蚁集团联合推出的开源AI数字人项目。SadTalker专注于通过单张人脸图像和语音音频,利用3D运动系数生成逼真的说话人脸动画。...
-
发布了文章 2个月前
SaRA – 上海交大联合腾讯推出的预训练扩散模型微调方法
SaRA是一种新型的预训练扩散模型微调方法,由上海交通大学和腾讯优图实验室共同推出。基于重新激活预训练过程中看似无效的参数,让模型能适应新任务。SaRA基于核范数低秩稀疏训练方案避免过拟合,引入渐进式参数调整策略,优化模型性...