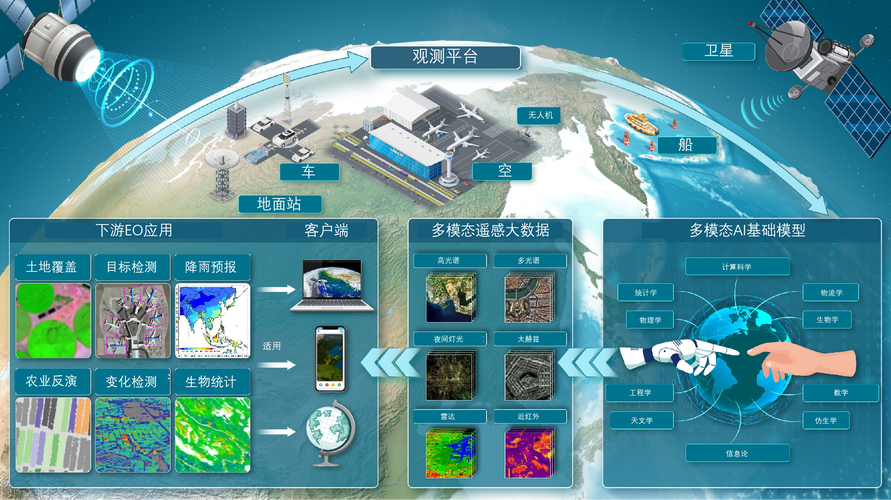
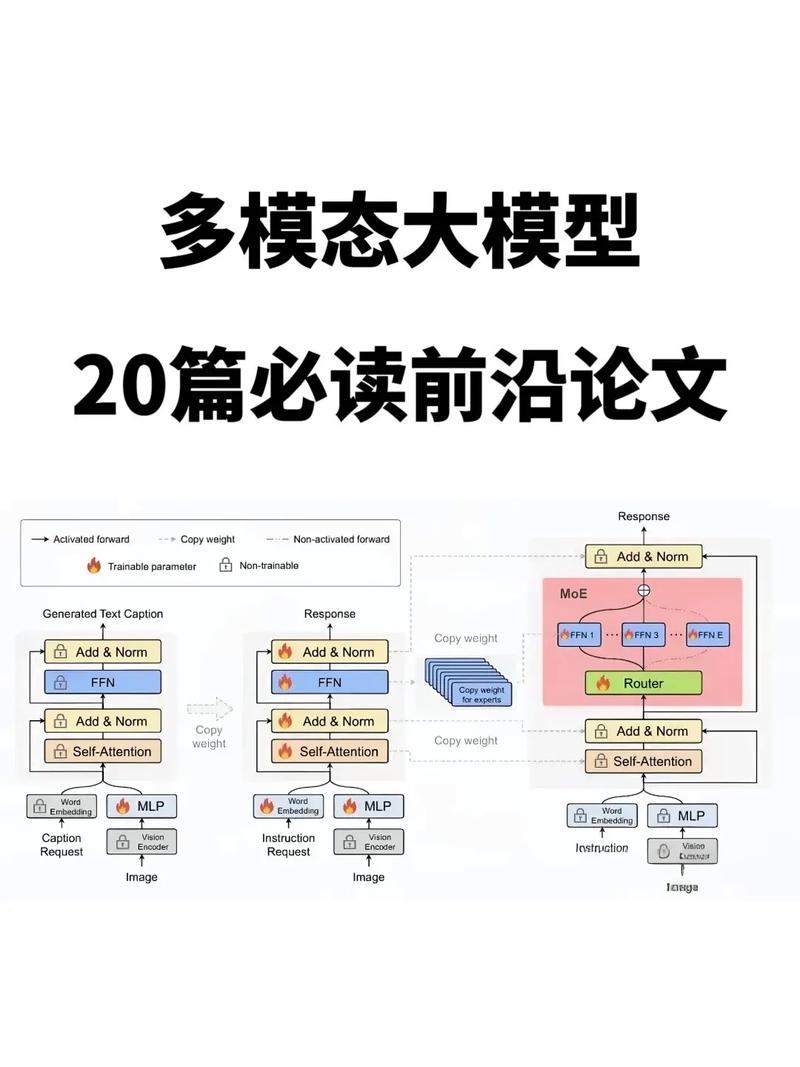
AI工具
发布文章-
发布了文章 2个月前
VideoLingo – 全自动AI视频翻译工具,一键搞定双语字幕和配音
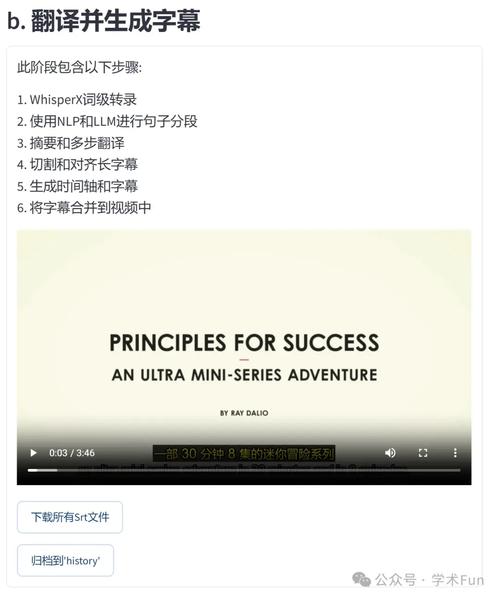
VideoLingo 是一款一键全自动视频翻译工具,能将视频进行字幕切割、翻译、对齐和配音,最终生成 Netflix 级别的字幕和配音。VideoLingo 基于自然语言处理(NLP)和大型语言模型(LLM)技术,提供智能术...
-
发布了文章 2个月前
VideoLLaMB – 开源的多模态长视频理解框架
VideoLLaMB 是一种创新的长视频理解框架,通过引入记忆桥接层和递归记忆令牌来处理视频数据,确保在分析时不丢失关键视觉信息。模型特别设计用于理解长时间视频内容,保持语义连续性,并在多种任务中表现出色,如视频问答、自我中...
-
发布了文章 2个月前
VideoLLaMA3 – 阿里达摩院推出的多模态基础模型
VideoLLaMA3 是阿里巴巴开源的前沿多模态基础模型,专注于图像和视频理解。基于 Qwen 2.5 架构,结合了先进的视觉编码器(如 SigLip)和强大的语言生成能力,能高效处理长视频序列,支持多语言的视频内容分析和...
-
发布了文章 2个月前
VideoJAM – Meta 推出增强视频生成模型运动连贯性的框架
VideoJAM是Meta推出的,用在增强视频生成模型运动连贯性的框架。基于引入联合外观-运动表示,让模型在训练阶段同时学习预测视频的像素和运动信息,在推理阶段基于模型自身的运动预测作为动态引导信号,生成更连贯的运动。...
-
发布了文章 2个月前
VideoGrain – 悉尼科技大学和浙大推出的视频编辑框架
VideoGrain 是悉尼科技大学和浙江大学推出的零样本多粒度视频编辑框架,能实现类别级、实例级和部件级的精细视频修改。VideoGrain基于调节时空交叉注意力和自注意力机制,增强文本提示对目标区域的控制能力,且保持区域...
-
发布了文章 2个月前
VideoGigaGAN – Adobe推出的AI视频分辨率提升模型
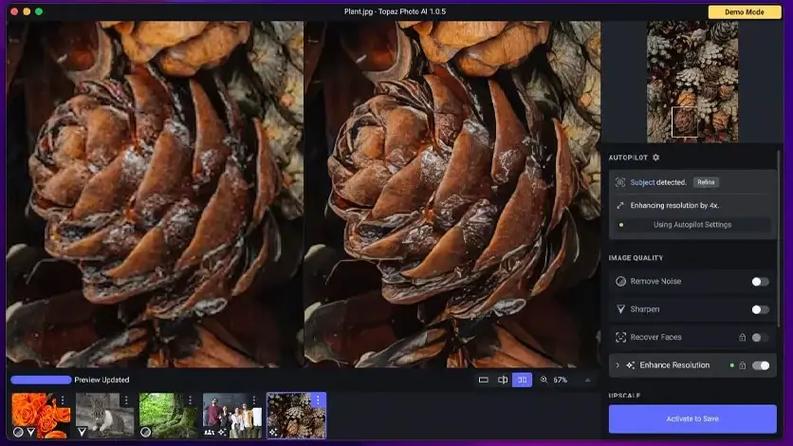
VideoGigaGAN是由Adobe和马里兰大学的研究人员提出的一种新型的生成式视频超分辨率(VSR)模型,最高可将视频分辨率提升8倍,将模糊的视频放大为具有丰富细节和时间连贯性的高清视频。...
-
发布了文章 2个月前
VideoGameBunny – 专为视频游戏设计的开源多模态大模型
VideoGameBunny(VGB)是一个专为视频游戏设计的开源大型多模态模型,由加拿大阿尔伯塔大学研究团队开发。它能理解和生成多种语言的游戏相关内容,支持高度定制化,具备强大的文本生成能力。...
-
发布了文章 2个月前
VideoFusion – AI视频剪辑工具,自动去除视频黑边、水印和字幕
VideoFusion 是开源的短视频拼接与处理软件,专为高效视频编辑设计。支持自动去除视频中的黑边、水印和字幕,能将视频自动旋转为横屏或竖屏,适配不同播放场景。软件具备降噪、去抖动、音量平衡等功能,能提升视频画质。...
-
发布了文章 2个月前
VideoDoodles – Adobe推出的AI视频编辑框架
VideoDoodles是Adobe公司联合多所大学推出的AI视频编辑框架。支持用户在视频中轻松插入手绘动画,实现与视频内容的无缝融合。通过预处理视频帧,系统提供平面画布,用户可以视频上绘制动画,系统自动处理透视和遮挡效果。...
-
发布了文章 2个月前
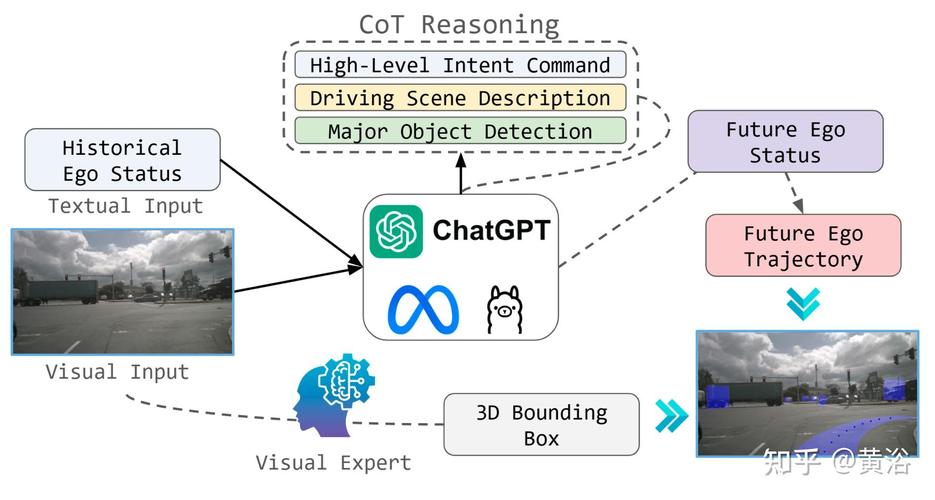
VideoChat-baidu09Flash – 上海 AI Lab 等机构推出针对长视频建模的多模态大模型
VideoChat-Flash 是上海人工智能实验室和南京大学等机构联合开发的针对长视频建模的多模态大语言模型(MLLM),模型通过分层压缩技术(HiCo)高效处理长视频,显著减少计算量,同时保留关键信息。...
-
发布了文章 2个月前
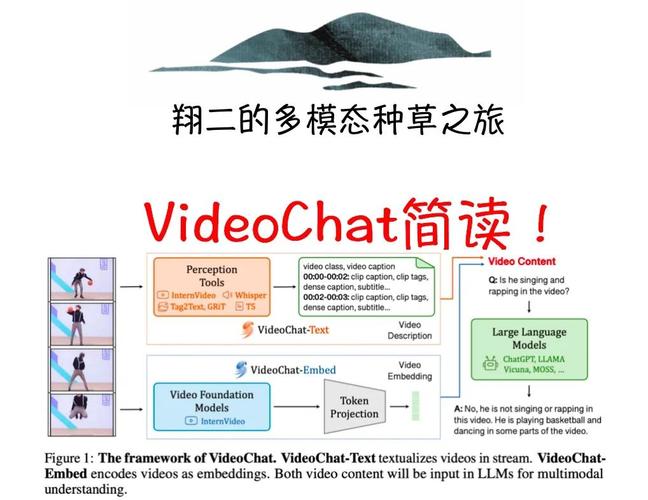
VideoChat – 开源的实时数字人对话系统,首包延迟低至3秒
VideoChat是开源的实时数字人对话系统,支持语音输入和实时对话功能。用户自定义数字人的形象和音色,无需训练即可进行音色克隆,首包延迟可低至3秒,适用于直播、新闻播报和聊天助手等多种实时语音交互场景。系统支持支持GLM-...
-
发布了文章 2个月前
VideoCaptioner – AI视频字幕处理工具,支持字幕样式调整和多格式导出
VideoCaptioner(中文名:卡卡字幕助手)是基于大语言模型(LLM)的智能字幕处理工具,能简化视频字幕的生成与优化流程。VideoCaptioner支持语音识别、字幕断句、校正、翻译及视频合成的全流程处理,无需GP...
-
发布了文章 2个月前
VideoAnydoor – 港大联合阿里达摩院等机构推出的零样本视频对象插入框架
VideoAnydoor是香港大学、阿里巴巴集团达摩院、湖畔实验室、华中科技大学联合推出的零样本的视频对象插入框架,能将特定对象以高保真度和精确运动控制的方式插入到视频中。VideoAnydoor基于文本到视频的扩散模型,用...
-
发布了文章 2个月前
VideoAgent – 斯坦福联合多所研究机构推出自改进的视频生成系统
VideoAgent是一种自改进的视频生成系统,由斯坦福大学、滑铁卢大学、DeepMind等机构的研究人员共同推出。根据图像观察和语言指令生成视频计划,转换为机器人控制动作。VideoAgent基于自我条件一致性方法细化视频...
-
发布了文章 2个月前
Video-baidu09XL – 智源联合多所高校推出的开源超长视觉理解模型
Video-XL是北京智源人工智能研究院联合上海交大、中国人民大学、中科院、北邮和北大的研究人员共同推出的专为小时级视频理解设计的超长视觉理解模型。基于视觉上下文潜在总结技术将视觉信息压缩成紧凑的形式,提高处理效率、减少信息...