AI工具
发布文章-
发布了文章 2个月前
Video-baidu09T1 – 清华联合腾讯推出的视频生成技术
Video-T1 是清华大学和腾讯的研究人员共同推出的视频生成技术,基于测试时扩展(Test-Time Scaling,TTS)提升视频生成的质量和一致性。传统视频生成模型在训练后直接生成视频,Video-T1 在测试阶段引...
-
发布了文章 2个月前
Video-baidu09LLaVA2 – ChatLaw推出的开源多模态智能理解系统
Video-LLaVA2是由北京大学ChatLaw课题组研发的开源多模态智能理解系统,通过创新的时空卷积(STC)连接器和音频分支,提升了视频和音频理解能力。模型在视频问答和字幕生成等多个基准测试中表现出色,与一些专有模型相...
-
发布了文章 2个月前
Video Alchemist – AI视频生成模型,具备多主体开放集合个性化能力
Video Alchemist是Snap公司等推出的新型视频生成模型,具备多主体、开放集合个性化能力,能根据文本提示和参考图像生成视频,无需在测试时进行优化。模型基于Diffusion Transformer模块,通过双重交...
-
发布了文章 2个月前
VidTok – 微软开源的视频分词器,支持连续和离散分词化
VidTok(Video Tokenizer)是微软开源的先进的视频分词器,通过高效的算法将视频内容转换成一系列“视频词”。支持连续和离散分词化,具有灵活的压缩率和多样化的隐空间,适用于不同的应用场景。...
-
发布了文章 2个月前
VidSketch – 浙江大学推出的视频动画生成框架
VidSketch 是浙江大学 CAD&CG 国家重点实验室和软件学院推出的创新视频生成框架,根据手绘草图和简单文本提示生成高质量的视频动画。VidSketch基于“层级草图控制策略”动态调整草图的引导强度,适应不同绘画技能...
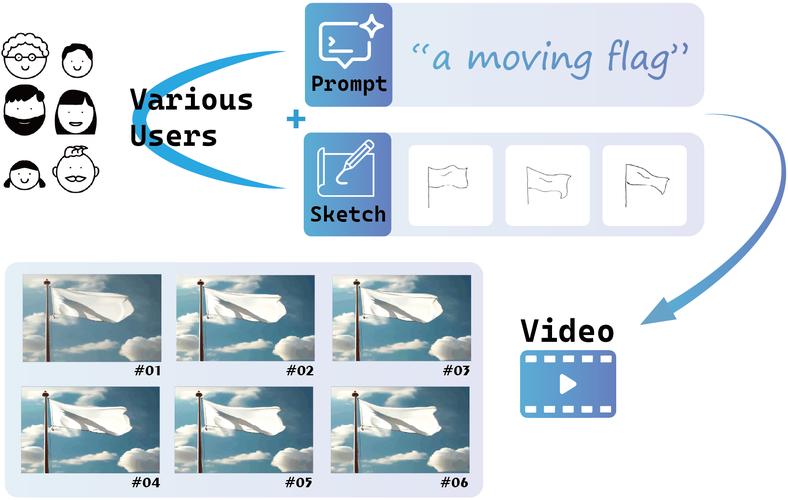
-
发布了文章 2个月前
Vid2World – 清华联合重庆大学推出视频模型转为世界模型的框架
Vid2World是清华大学联合重庆大学推出的创新框架,支持将全序列、非因果的被动视频扩散模型(VDM)转换为自回归、交互式、动作条件化的世界模型。模型基于视频扩散因果化和因果动作引导两大核心技术,解决传统VDM在因果生成和...
-
发布了文章 2个月前
VibeVoice – 微软推出的开源文本转语音模型
VibeVoice 是微软推出的新型文本到语音(TTS)模型,能生成富有表现力、长篇幅、多说话者的对话式音频,如播客。...
-
发布了文章 2个月前
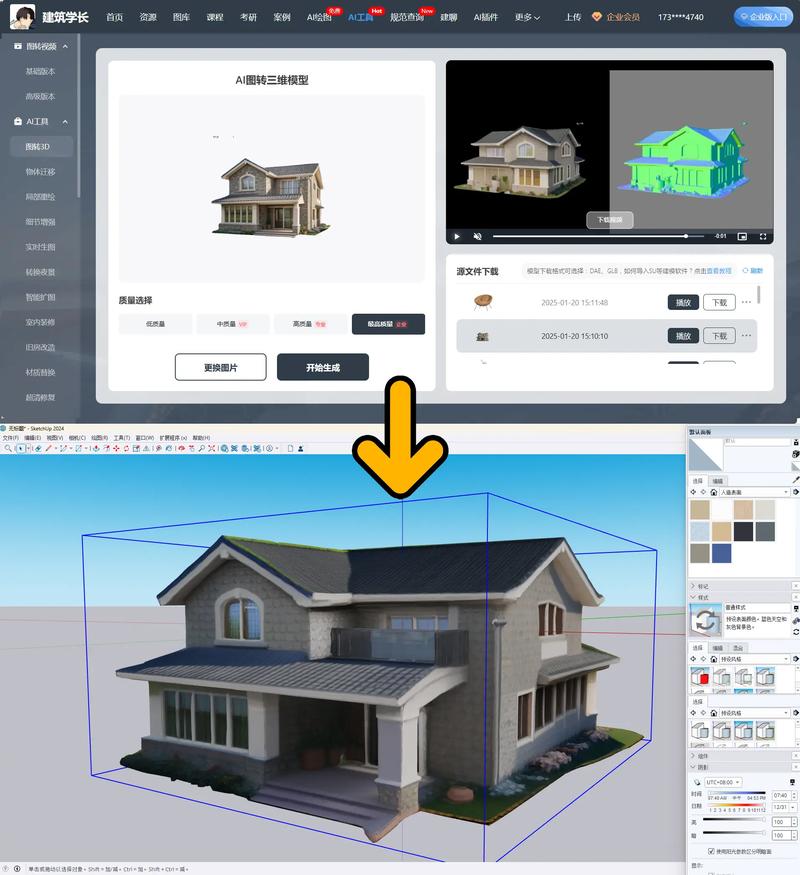
Vibe Draw – AI 3D建模工具,涂鸦草图一键转为3D模型
Vibe Draw是开源的 AI 3D建模工具,支持将用户在2D画布上绘制的涂鸦草图转化为精美的3D模型。用户能用文本提示或继续绘制迭代优化模型,一键导出为标准格式(.glTF)。Vibe Draw打破技术门槛,让任何人无需...
-
发布了文章 2个月前
ViTPose – 基于 Transformer 架构的人体姿态估计模型
ViTPose 是基于 Transformer 架构的人体姿态估计模型。以普通视觉 Transformer 作为骨干网络,通过将输入图像切块并送入 Transformer block 来提取特征,再经解码器将特征解码为热图,...
-
发布了文章 2个月前
ViLAMP – 蚂蚁联合人民大学推出的视觉语言模型
ViLAMP(VIdeo-LAnguage Model with Mixed Precision)是蚂蚁集团和中国人民大学联合推出的视觉语言模型,专门用在高效处理长视频内容。基于混合精度策略,对视频中的关键帧保持高精度分析,...
-
发布了文章 2个月前
ViDoRAG – 通义联合中科大、上交大推出的视觉文档检索增强生成框架
ViDoRAG是阿里巴巴通义实验室联合中国科学技术大学和上海交通大学推出的视觉文档检索增强生成框架。基于多智能体协作和动态迭代推理,解决传统方法在处理复杂视觉文档时的检索和推理局限性。ViDoRAG用高斯混合模型(GMM)的...
-
发布了文章 2个月前
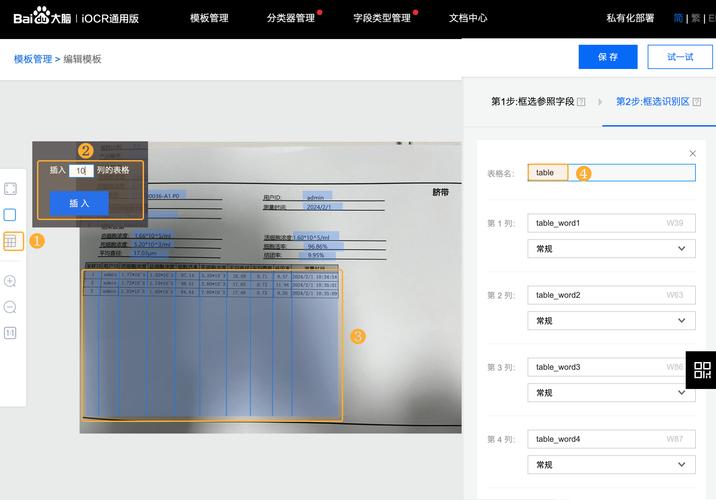
Versatile-baidu09OCR-baidu09Program – 开源多模态OCR工具,精准提取复杂结构化数据
Versatile-OCR-Program是为教育场景和机器学习训练定制的开源多模态OCR工具。结合DocLayout-YOLO、Google Vision和MathPix等技术,精准识别文本、数学公式、表格、图表等多模态内...
-
发布了文章 2个月前
VersaGen – 实现文本到图像合成中视觉控制能力的生成式 AI 代理
VersaGen是文本到图像合成的生成式AI代理,能实现灵活的视觉控制能力。VersaGen能处理包括单一视觉主体、多个视觉主体、场景背景,这些元素的任意组合在内的多种视觉控制类型。基于在已有的文本主导的扩散模型上训练适配器...
-
发布了文章 2个月前
Verifier Engineering – 中科院、阿里、小红书联合推出的新型后训练范式
Verifier Engineering(验证器工程)是中国科学院、阿里巴巴和小红书联合推出的新型后训练范式,为基础模型设计,解决提供有效监督信号的挑战。Verifier Engineering基于自动化验证器执行验证任务并...
-
发布了文章 2个月前
Veo – 谷歌推出的可生成1分钟1080P的视频模型
Veo是由Google DeepMind开发的一款视频生成模型,用户可以通过文本、图像或视频提示来指导其生成所需的视频内容,能够生成时长超过一分钟1080P分辨率的高质量视频。...