

ViLAMP(VIdeo-LAnguage Model with Mixed Precision)是蚂蚁集团和中国人民大学联合推出的视觉语言模型,专门用在高效处理长视频内容。基于混合精度策略,对视频中的关键帧保持高精度分析,显著降低计算成本提高处理效率。ViLAMP在多个视频理解基准测试中表现出色,在长视频理解任务中,展现出显著优势。ViLAMP能在单张A100 GPU上处理长达1万帧(约3小时)的视频,同时保持稳定的理解准确率,为长视频分析提供新的解决方案。

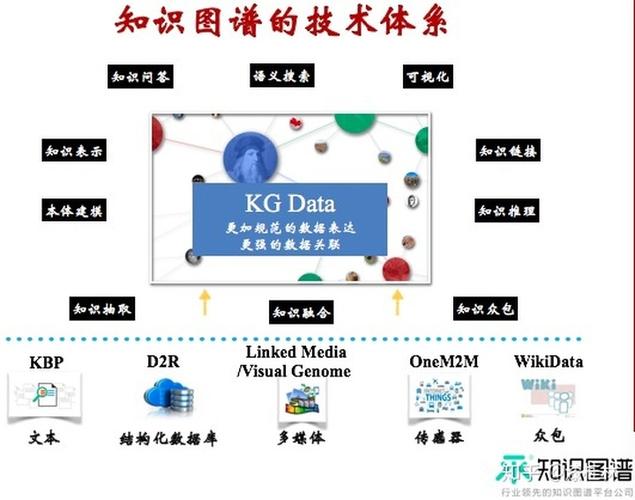
(图片来源网络,侵删)

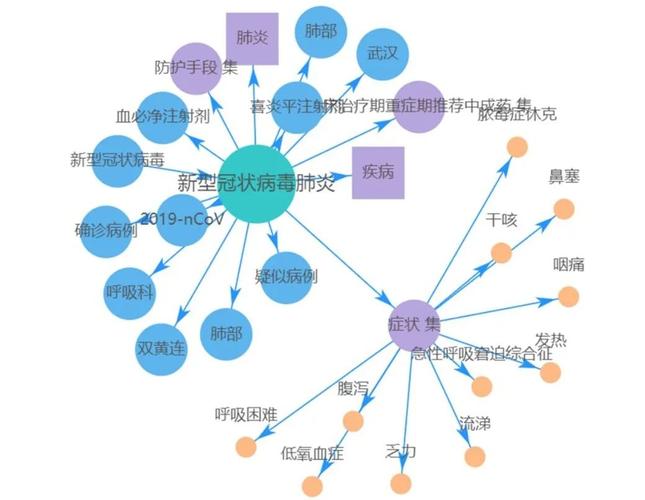
(图片来源网络,侵删)



全部评论
留言在赶来的路上...
发表评论