AI工具
发布文章-
发布了文章 2个月前
Veo 3 – 谷歌推出的新一代视频生成模型
Veo 3是谷歌I/O开发者大会上发布的新一代视频生成模型。Veo 3是谷歌首个可生成视频背景音效的模型,能合成画面,能为鸟鸣、街头交通等场景配上相应的音效,可生成人物对话。模型在物理模拟与口型同步方面表现出色,视频中的人物...
-
发布了文章 2个月前
Veo 2 – 谷歌 DeepMind 推出的 AI 视频生成模型,支持高达 4K 分辨率
Veo 2 是 Google DeepMind 推出的 AI 视频生成模型,能根据文本或图像提示生成高质量视频内容。Veo 2支持高达 4K 分辨率的视频制作,理解镜头控制指令,能模拟现实世界的物理现象及人类表情。Veo 2...
-
发布了文章 2个月前
VectorVein – 开源的无代码AI工作流工具,简单拖拽定制AI应用
VectorVein 是一款开源的无代码AI工作流工具,通过简化的拖拽操作,让用户无需编程知识即可构建智能工作流,实现日常任务的自动化。它支持数据处理、分析和知识管理等多种应用场景,具备无代码、AI驱动、可定制化等特点。...
-
发布了文章 2个月前
VeOmni – 字节跳动开源的全模态PyTorch原生训练框架
VeOmni 是字节跳动 Seed 团队开源的全模态分布式训练框架,基于 PyTorch 设计。VeOmni 以模型为中心,将分布式并行逻辑与模型计算解耦,支持灵活组合多种并行策略(如 FSDP、SP、EP),能高效扩展至超...
-
发布了文章 2个月前
Vary-baidu09toy:开源的小型视觉多模态模型
Vary-toy是一个小型的视觉语言模型(LVLM),由来自旷视、国科大、华中大的研究人员共同提出,旨在解决大型视觉语言模型(LVLMs)在训练和部署上的挑战。对于资源有限的研究者来说,大型模型通常拥有数十亿参数,难以在消费...
-
发布了文章 2个月前
Vanna – 开源AI检索生成框架,自动生成精确的SQL查询
Vanna是开源的Python RAG(Retrieval-Augmented Generation)框架,能帮助用户基于大型语言模型(LLMs)为其数据库生成精确的SQL查询。Vanna用两步简单流程操作:首先在用户数据上...
-
发布了文章 2个月前
Valley – 字节跳动推出的多模态大模型
Valley是字节跳动推出的多模态大模型,用于处理涉及文本、图像和视频数据的多样化任务。Valley在内部电子商务和短视频基准测试中取得了最佳成绩,并在OpenCompass测试中展现出色性能,尤其是在小于10B参数规模的模...
-
发布了文章 2个月前
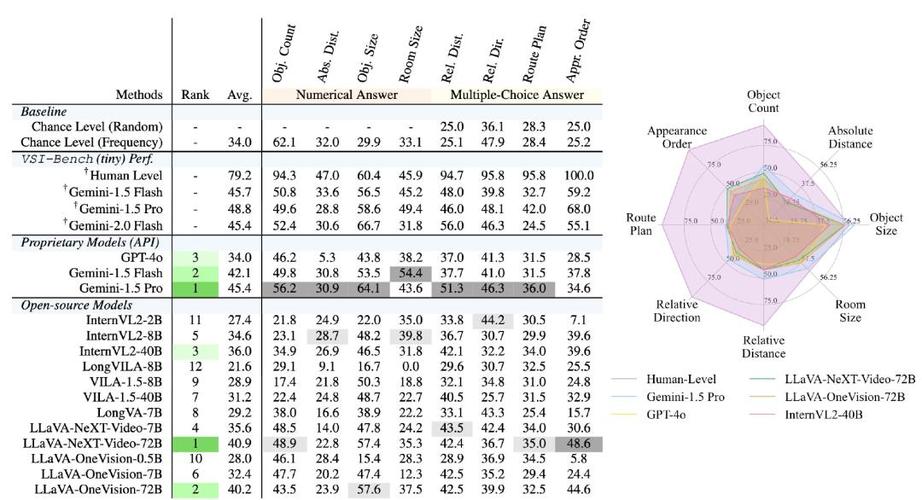
VSI-baidu09Bench – 李飞飞谢赛宁团队推出的视觉空间智能基准测试集
VSI-Bench(Visual-Spatial Intelligence Benchmark)是李飞飞、谢赛宁及他们的研究团队推出的视觉空间智能基准测试集,研究者构建用在评估多模态大型语言模型(MLLMs)在空间认知和理解...
-
发布了文章 2个月前
VRAG-baidu09RL – 阿里通义推出的多模态RAG推理框架
VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,专注于提升视觉语言模型(VLMs)在处理视觉丰富信息时的检索、推理和理解能力。基于定义视觉感知动作空间,让模型能从粗粒度到细粒度逐步获取信息,更...
-
发布了文章 2个月前
VQAScore – CMU联合Meta推出的文本到视觉图像生成评估方法
VQAScore是CMU和Meta联合推出的评估方法,基于视觉问答(VQA)模型衡量由文本提示生成的图像质量。VQAScore用计算模型对“Does this figure show {text}?”这一问题回答“是”的概率...
-
发布了文章 2个月前
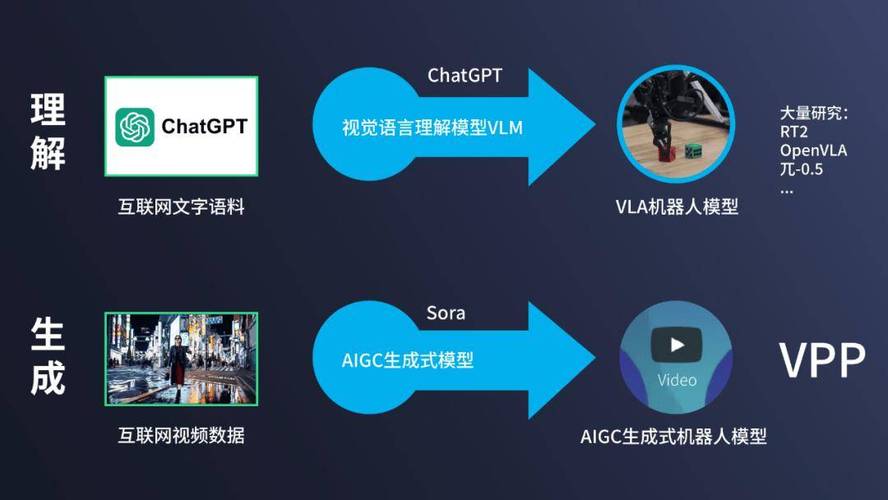
VPP – 清华和星动纪元推出的首个AIGC机器人大模型
VPP(Video Prediction Policy)是清华大学和星动纪元推出的首个AIGC机器人大模型。基于预训练的视频扩散模型,学习互联网上的大量视频数据,直接预测未来场景生成机器人动作。VPP能提前预知未来,实现高频...
-
发布了文章 2个月前
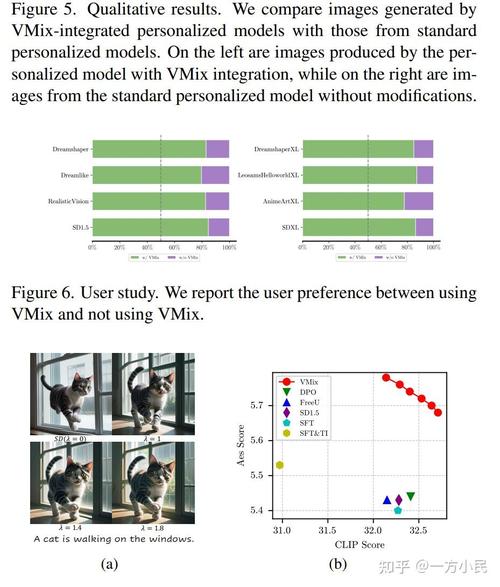
VMix – 字节联合中科大推出增强模型生成美学质量的适配器
VMix是创新的即插即用美学适配器,提升文本到图像扩散模型生成图像的美学质量。通过解耦输入文本提示中的内容描述和美学描述,将细粒度的美学标签(如色彩、光线、构图等)作为额外条件引入生成过程。...
-
发布了文章 2个月前
VMB – 中科院联合多所高校机构推出增强多模态音乐生成的框架
VMB(Visuals Music Bridge)是中国科学院信息工程研究所、中国科学院大学网络空间安全学院、上海人工智能实验室、上海交通大学等机构推出的多模态音乐生成框架,能从文本、图像和视频等多种输入模态生成音乐。...
-
发布了文章 2个月前
VLOGGER – 谷歌推出的图像到合成人物动态视频的模型
VLOGGER AI是谷歌的研究团队开发的一个多模态扩散模型,专门用于从单一输入图像和音频样本生成逼真的、连贯的人像动态视频。该模型的主要功能在于使用人工智能模型,将一张静态图片转换成一个动态的视频角色,同时保持照片中人物的...
-
发布了文章 2个月前
VLN-baidu09R1 – 港大联合上海AI lab推出的具身智能框架
VLN-R1是香港大学和上海人工智能实验室联合推出的全新具身智能框架,基于大型视觉语言模型(LVLM)直接将第一人称视频流转换为连续的导航动作。框架基于Habitat 3D模拟器构建VLN-Ego数据集,用长短期记忆采样策略...