

Vary-toy是一个小型的视觉语言模型(LVLM),由来自旷视、国科大、华中大的研究人员共同提出,旨在解决大型视觉语言模型(LVLMs)在训练和部署上的挑战。对于资源有限的研究者来说,大型模型通常拥有数十亿参数,难以在消费级GPU上(如GTX 1080Ti)进行训练和部署。Vary-toy的核心目标便是让研究人员能够在有限的硬件资源下,体验到当前LVLMs的所有功能(文档OCR、视觉定位、图像描述、视觉文答等)。
Vary-toy的工作原理基于几个关键的技术和设计决策,这些决策共同作用于提高模型在视觉语言任务上的性能,同时保持模型的小型化。以下是Vary-toy工作原理的主要组成部分:
通过这些工作机制,Vary-toy能够在保持模型小型化的同时,实现对复杂视觉语言任务的有效处理。这种设计使得Vary-toy成为一个在资源受限环境中进行视觉语言研究的有力工具。

(图片来源网络,侵删)

(图片来源网络,侵删)

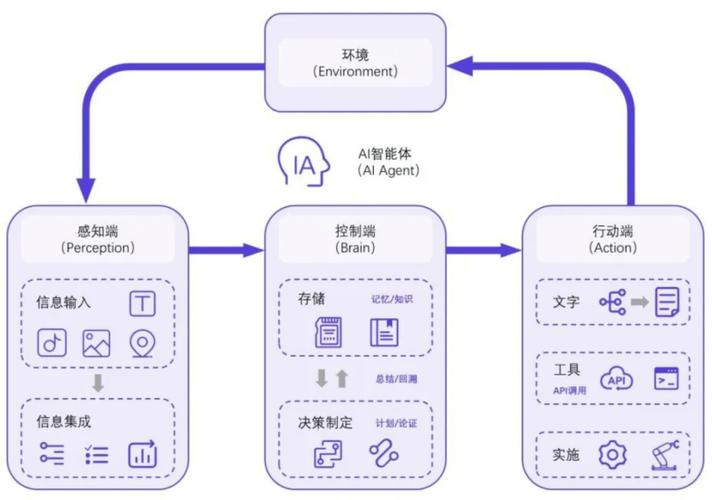
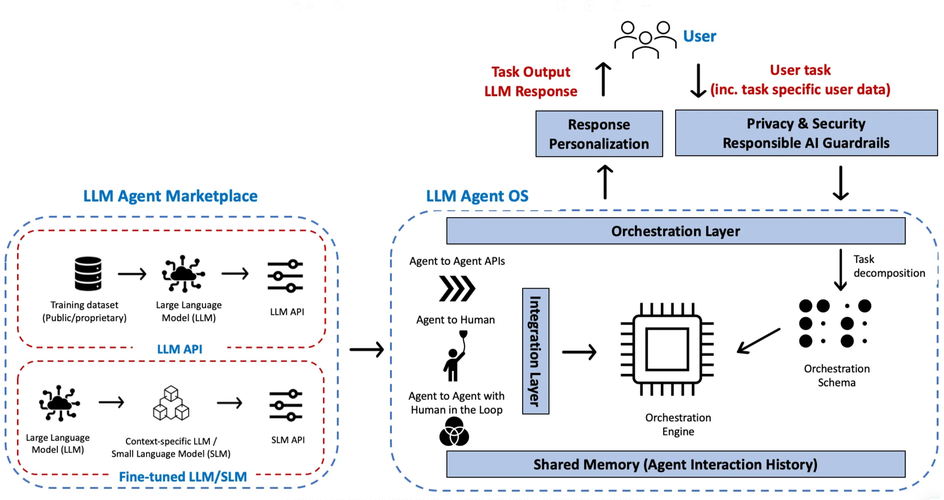


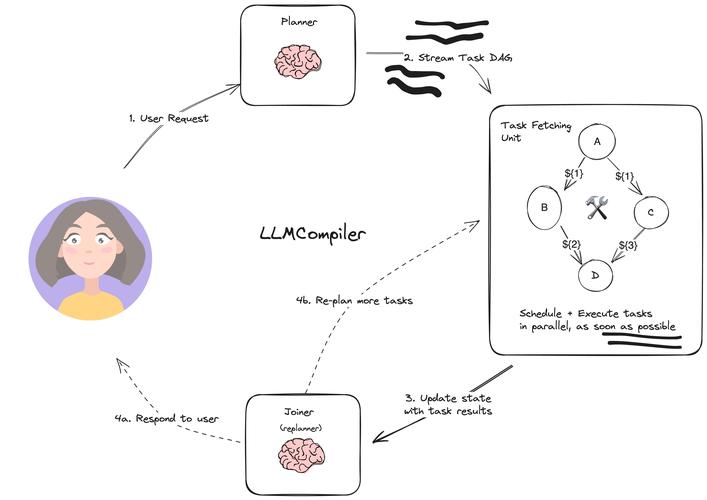
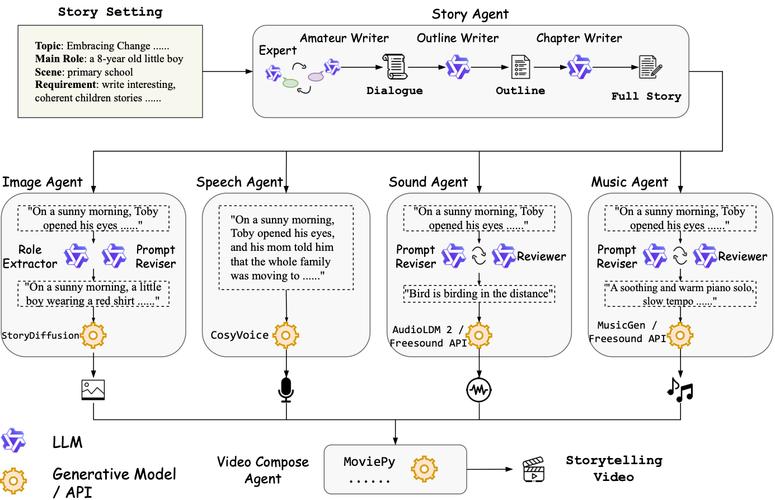

全部评论
留言在赶来的路上...
发表评论