AI工具
发布文章-
发布了文章 2个月前
VLM-baidu09R1 – 浙大 Om AI Lab 推出的视觉语言模型
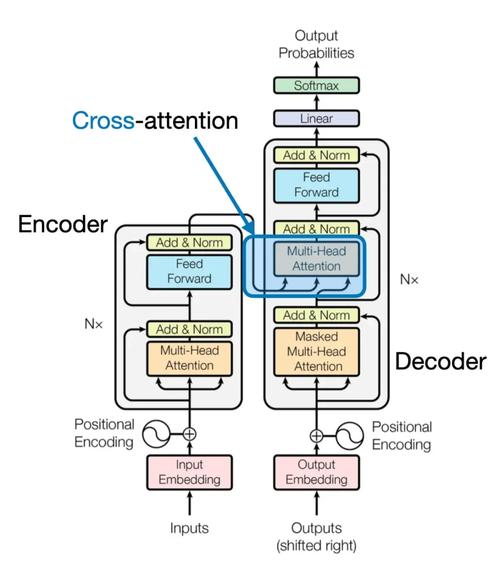
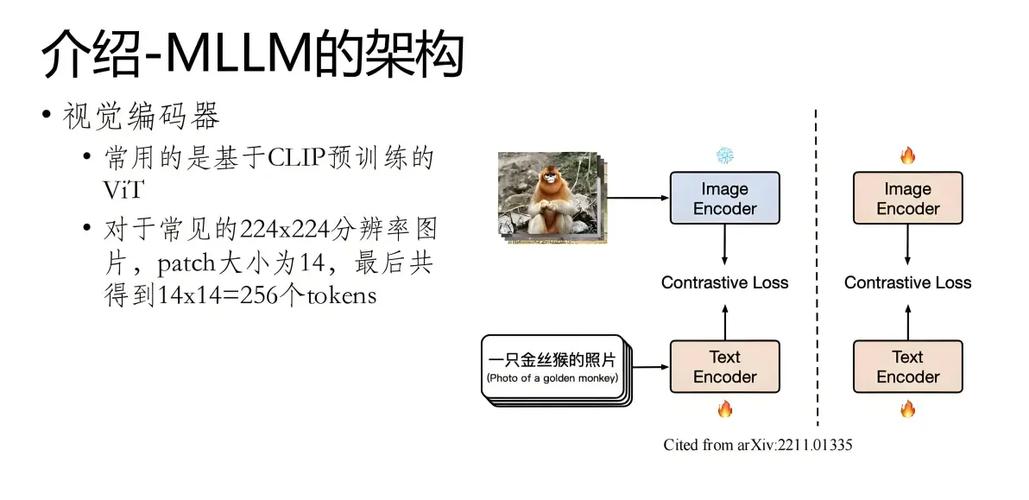
VLM-R1 是 Om AI Lab 推出的基于强化学习技术的视觉语言模型,通过自然语言指令精确定位图像中的目标物体,如根据描述“图中红色的杯子”找到对应的图像区域。模型基于 Qwen2.5-VL 架构,结合 DeepSee...
-
发布了文章 2个月前
VITRON – Skywork AI 联合新加坡国立、南洋理工推出的像素级视觉大型语言模型
VITRON是Skywork AI、新加坡国立大学和南洋理工大学联合推出的像素级视觉大型语言模型(LLM),能全面理解和处理静态图像与动态视频,对图像和视频进行理解、生成、分割和编辑。VITRON结合前端的视觉编码器和后端的...
-
发布了文章 2个月前
VITA-baidu09Audio – 开源的端到端多模态语音大模型,低延迟、推理快
VITA-Audio 是开源的端到端多模态语音大模型,具有低延迟、推理速度快的特点。通过轻量级的多模态交叉标记预测(MCTP)模块,可在首次前向传播中生成音频输出,将生成首个音频标记块的时间大幅缩短,显著降低流式场景下的延迟...
-
发布了文章 2个月前
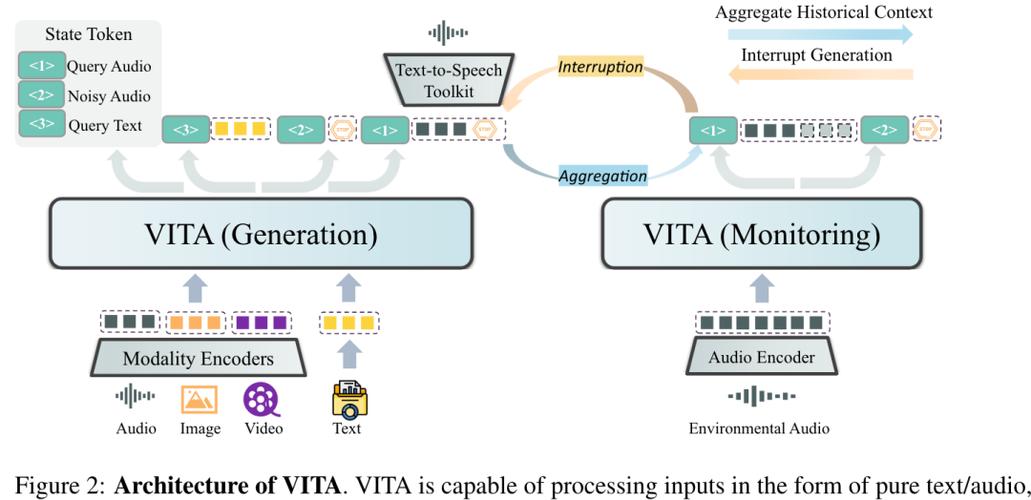
VITA – 腾讯推出的开源多模态AI模型
VITA是腾讯优图实验室推出的全球首个开源多模态大语言模型(MLLM),能理解和处理视频、图像、文本和音频。基于Mixtral 8×7B模型,扩展了中文词汇量,进行了双语指令微调,支持自然人机交互,无需唤醒词即可响应。...
-
发布了文章 2个月前
VISION XL – AI视频修复处理工具,修复缺失、支持四倍超分辨率
VISION XL是高效的视频修复和超分辨率工具,基于潜在扩散模型技术,专注于解决高清视频的逆问题。工具能修复视频缺失部分、去除模糊,显著提升视频清晰度,最高可达四倍超分辨率。...
-
发布了文章 2个月前
VILA-baidu09U – 融合多模态理解和生成的统一基础模型
VILA-U是集成视频、图像、语言理解和生成的统一基础模型。基于单一的自回归下一个标记预测框架处理理解和生成任务,简化模型结构,在视觉语言理解和生成方面实现接近最先进水平的性能。VILA-U的成功归因于在预训练期间将离散视觉...
-
发布了文章 2个月前
VFusion3D – Meta联合牛津大学推出的AI生成3D模型项目
VFusion3D 是由 Meta 和牛津大学的研究人员共同推出的AI生成3D模型项目,能从单张图片或文本描述中生成高质量的3D对象。VFusion3D 通过微调预训练的视频 AI 模型来生成合成的3D数据,解决了3D训练数...
-
发布了文章 2个月前
VE-baidu09Bench – 北京大学开源首个针对视频编辑质量评估的新指标
VE-Bench 是北京大学的研究团队 MMCAL 最近发布首个专门针对视频编辑质量评估的指标。VE-Bench 的设计目标是与人类感知能力高度一致,更准确地评估视频编辑效果。VE-Bench QA 在评估编辑视频时,不仅考...
-
发布了文章 2个月前
VASA-baidu091 – 微软推出的静态照片对口型视频生成框架
VASA-1是由微软亚洲研究院提出的一个将静态照片转换为对口型动态视频的生成框架,能够根据单张静态人脸照片和一段语音音频,实时生成逼真的3D说话面部动画。...

-
发布了文章 2个月前
VARGPT – 北大推出的多模态理解生成统一模型
VARGPT是创新的多模态大语言模型,专注于视觉理解和生成任务。基于自回归框架,将视觉生成与理解统一在一个模型中,避免任务切换的复杂性。VARGPT在LLaVA架构基础上进行扩展,通过next-token预测实现视觉理解,通...
-
发布了文章 2个月前
VACE – 阿里通义推出的视频生成与编辑框架
VACE(Video Creation and Editing)是阿里巴巴通义实验室推出的一站式视频生成与编辑框架。基于整合多种视频任务(如参考视频生成、视频到视频编辑、遮罩编辑等)到一个统一模型中,实现高效的内容创作和编辑...
-
发布了文章 2个月前
V-baidu09JEPA:Meta推出的视觉模型,可以通过观看视频来学习理解物理世界
V-JEPA是由Meta的研究人员推出的一种新型的视频自监督学习方法,它专注于通过特征预测来学习视频的视觉表示。这种方法的核心思想是让模型能够预测视频中一个区域(称为目标区域y)的特征表示,这个预测基于另一个区域(称为源区域...
-
发布了文章 2个月前
V-baidu09JEPA 2 – Meta AI开源的世界大模型
V-JEPA 2 是Meta AI推出的世界大模型,基于视频数据实现对物理世界的理解、预测和规划。V-JEPA 2 用于 12 亿参数的联合嵌入预测架构(JEPA),基于自监督学习从超过 100 万小时的视频和 100 万张...
-
发布了文章 2个月前
Universal-baidu091 – AssemblyAI推出的多语种语音识别和转换模型
Universal-1是AI语音初创公司AssemblyAI推出的一款多语言语音识别和转录模型,经过超过1250万小时的多语种音频数据训练,支持英语、西班牙语、法语和德语等。...
-
发布了文章 2个月前
Univer – 开源 AI 办公工具,支持Word、Excel等文档处理全栈解决方案
Univer是开源的全栈框架,支持创建和编辑电子表格、文档及幻灯片,为用户提供统一且强大的办公解决方案。Univer能在浏览器和Node.js环境中运行,易于集成到各种应用中。Univer跨平台兼容性、强大的功能(包括公式计...