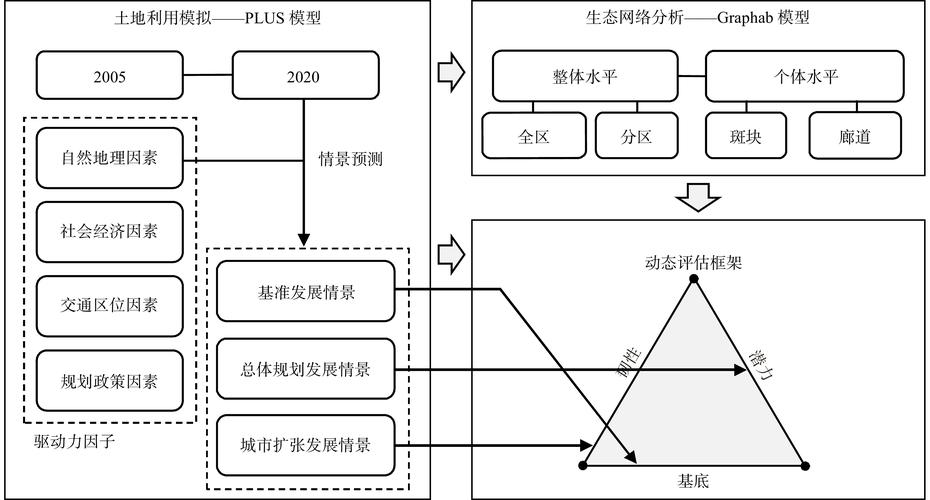
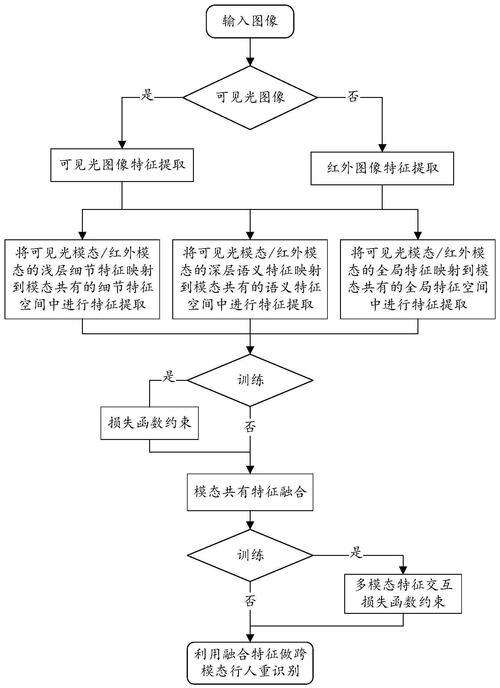
VLM-R1 是 Om AI Lab 推出的基于强化学习技术的视觉语言模型,通过自然语言指令精确定位图像中的目标物体,如根据描述“图中红色的杯子”找到对应的图像区域。模型基于 架构,结合 DeepSeek 的 R1 方法,通过强化学习优化和监督微调(SFT)提升模型的稳定性和泛化能力。VLM-R1 在复杂场景和跨域数据上表现出色,能更好地理解视觉内容生成准确的指代表达。

(图片来源网络,侵删)

(图片来源网络,侵删)


VLM-R1 是 Om AI Lab 推出的基于强化学习技术的视觉语言模型,通过自然语言指令精确定位图像中的目标物体,如根据描述“图中红色的杯子”找到对应的图像区域。模型基于 架构,结合 DeepSeek 的 R1 方法,通过强化学习优化和监督微调(SFT)提升模型的稳定性和泛化能力。VLM-R1 在复杂场景和跨域数据上表现出色,能更好地理解视觉内容生成准确的指代表达。

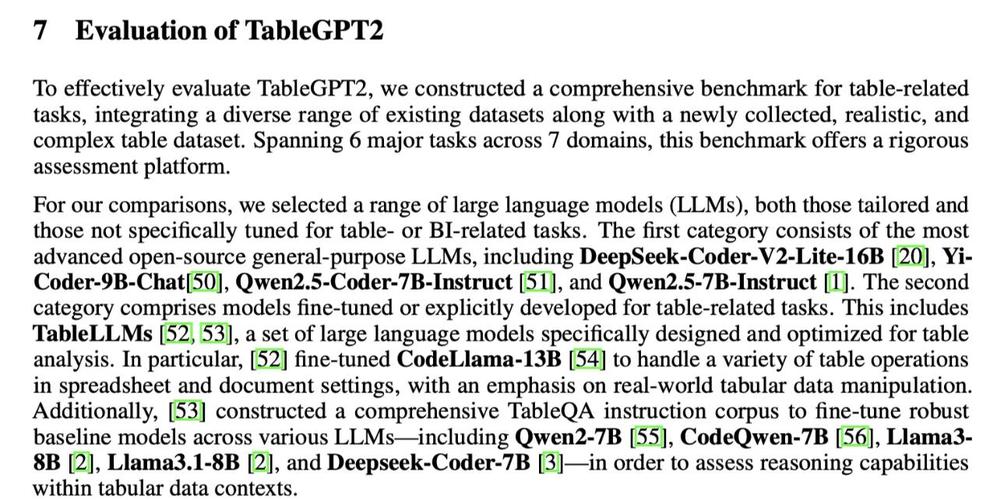
TableGPT2是浙江大学推出的新型大型多模态模型,针对表格数据的整合与处理。首次将结构化数据作为独立模态进行训练,直接理解并操作数据库、Excel等数据,执行SQL查询、数据分析等任务。模型包含创新的表格编码器,强化对不...
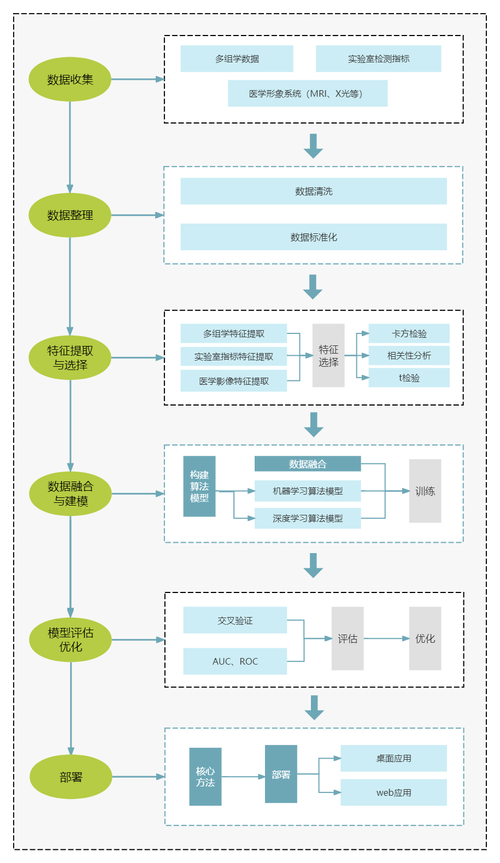
Embodied Reasoner是浙江大学、中国科学院软件研究所、阿里巴巴集团等机构推出的新型的具身交互推理模型,基于视觉搜索、推理和行动协同完成复杂任务。模型基于模仿学习、自我探索和自我修正的三阶段训练方法,生成多样化的...
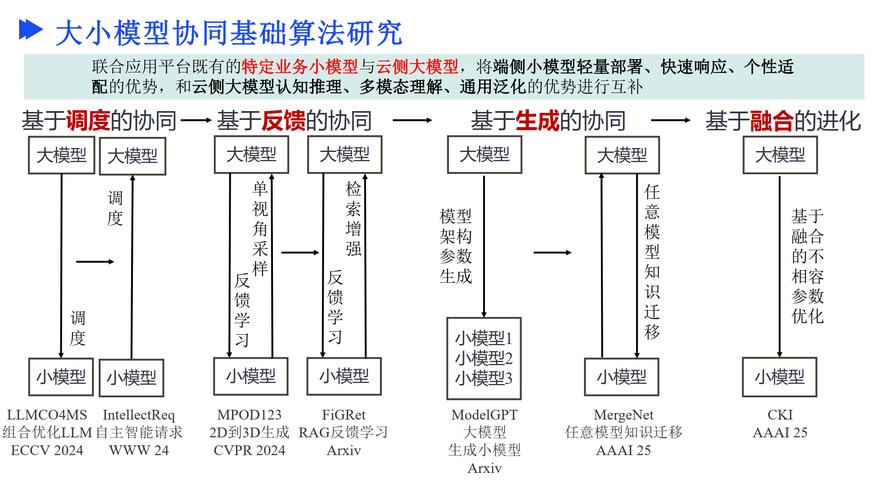
DRA-Ctrl(Dimension-Reduction Attack)是浙江大学联合蚂蚁集团等机构推出的创新跨模态图片编辑框架。框架借助视频生成模型的视觉、时间、空间和因果等多维度高维特征表示,实现对图片主体的状态预测与精...
全部评论
留言在赶来的路上...
发表评论