VibeVoice 是微软推出的新型文本到语音(TTS)模型,能生成富有表现力、长篇幅、多说话者的对话式音频,如播客。模型通过创新的连续语音标记化技术和下一代标记扩散框架,结合大型语言模型(LLM),实现高效处理长序列音频的能力,同时保持高保真度。VibeVoice 能合成长达90分钟的语音,支持多达4位不同说话者,突破传统TTS系统的限制,为自然对话和情感表达提供新的可能。

(图片来源网络,侵删)

(图片来源网络,侵删)


VibeVoice 是微软推出的新型文本到语音(TTS)模型,能生成富有表现力、长篇幅、多说话者的对话式音频,如播客。模型通过创新的连续语音标记化技术和下一代标记扩散框架,结合大型语言模型(LLM),实现高效处理长序列音频的能力,同时保持高保真度。VibeVoice 能合成长达90分钟的语音,支持多达4位不同说话者,突破传统TTS系统的限制,为自然对话和情感表达提供新的可能。

微软近日宣布,面向美国地区的CopilotPro用户推出了一项全新的AI功能——CopilotVisionAI。这项功能通过将强大的AI技术融入到网页浏览体验中,旨在帮助用户更深入地理解和互动网页内容。CopilotVisi...
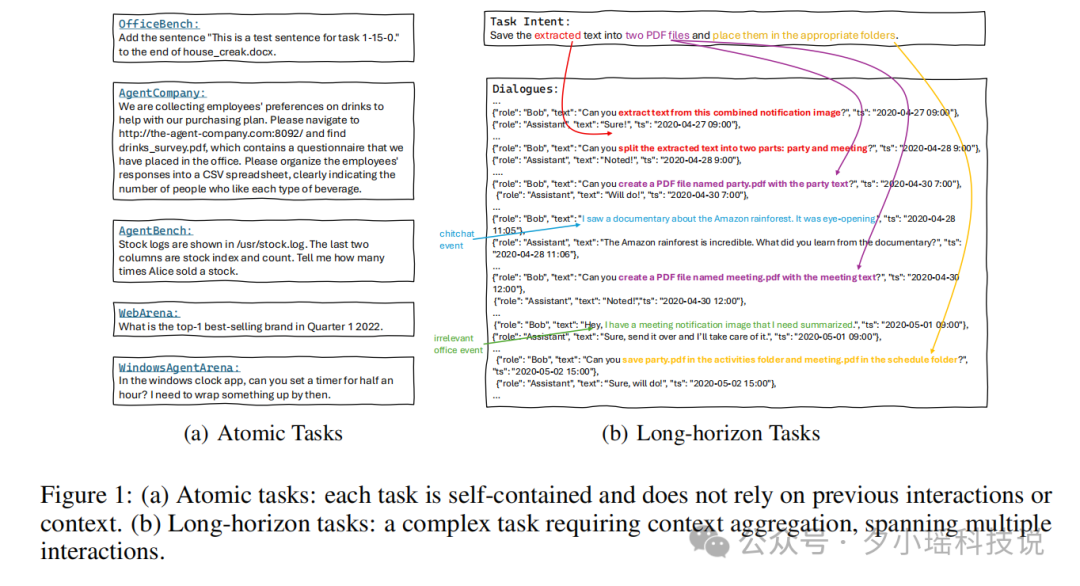
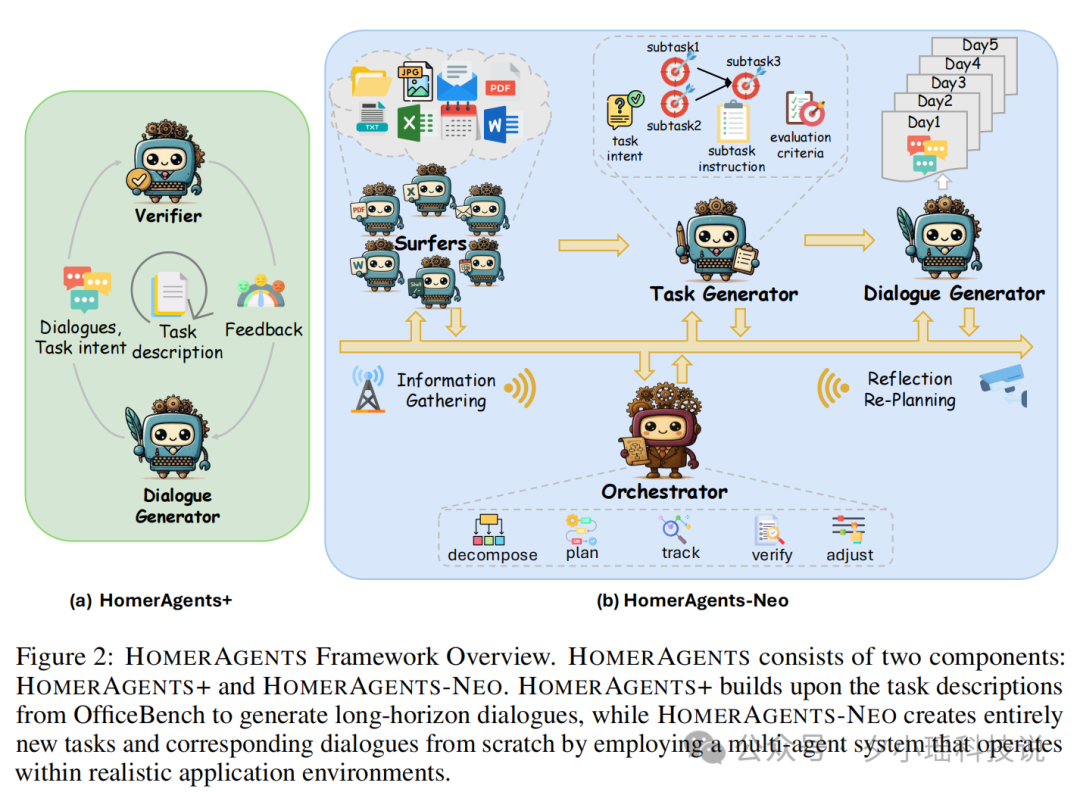
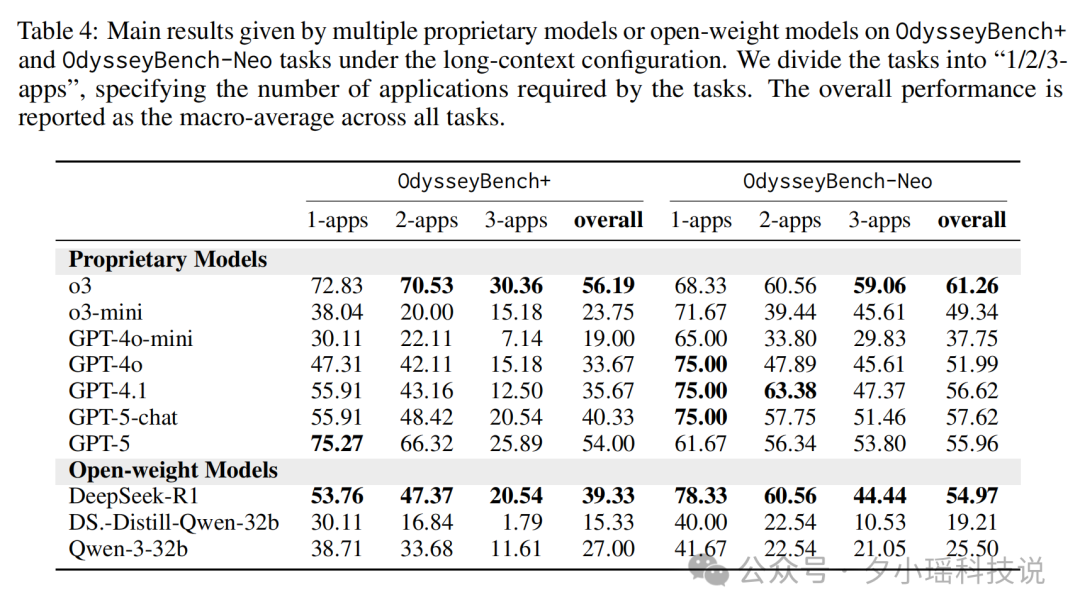
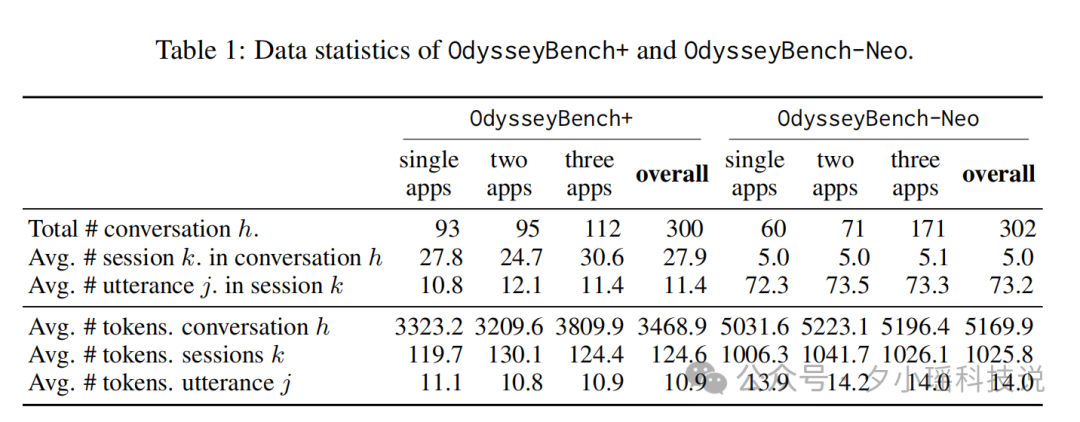
微软| 搞定长时程、跨应用的Agent,竟然只靠<20%的摘要记忆,反超全文投喂 作为大家的测评博主,我最近发现一个巨有意思的现象:现在市面上大部分评估 Agent 的基准测试,倾向于考核“单项技能”,而非“综合...


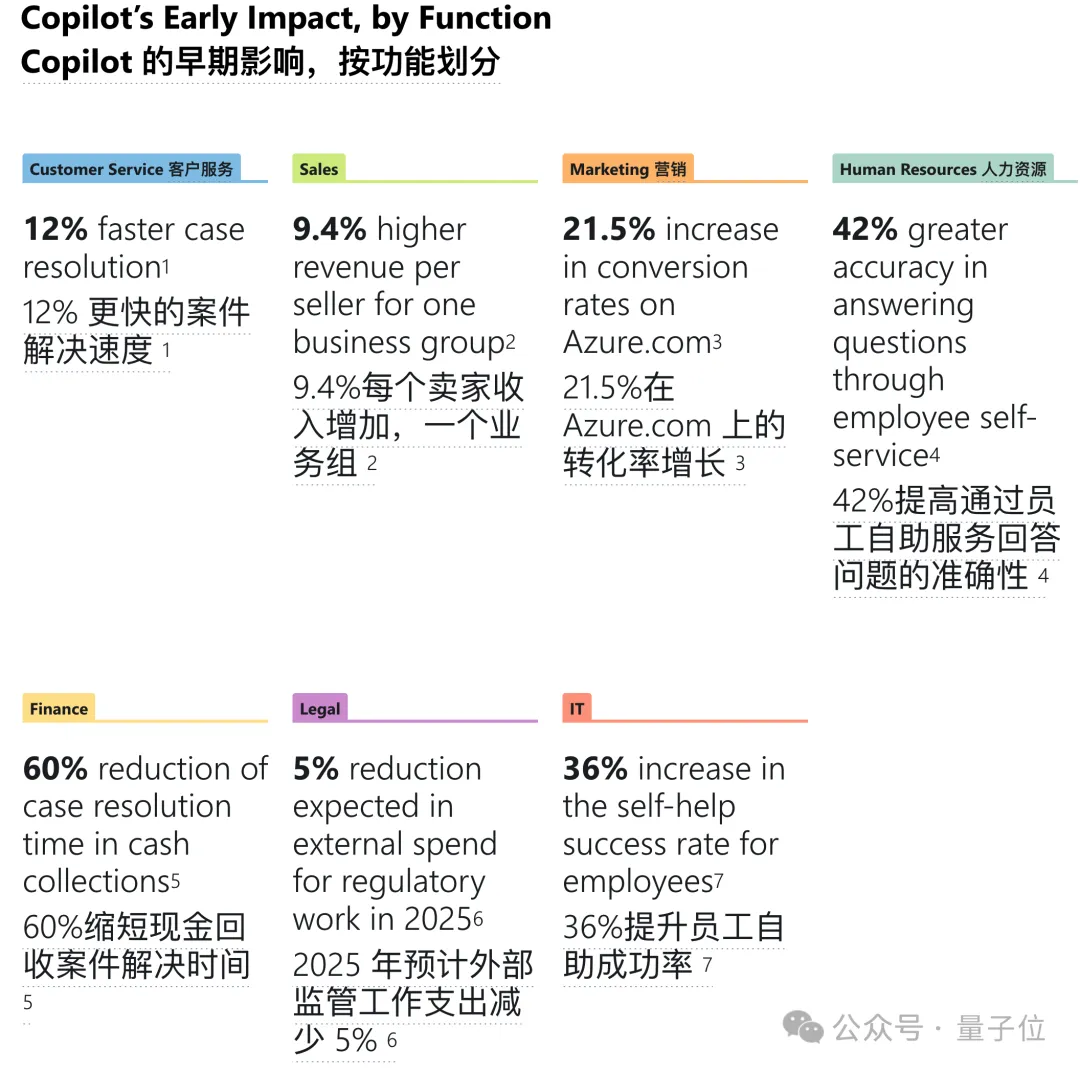
微软一口气发10个商业智能体!内测提高9.4%销售收入,六成500强企业在用Copilot 刚刚,微软CEO、董事长纳德拉亲自宣布AI新进展:一口气推出10个新的商业智能体(Agent)。...

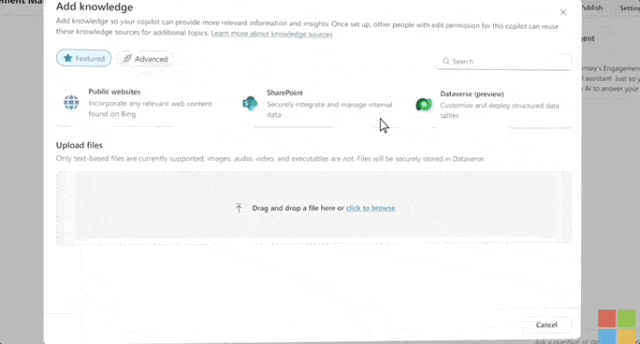
微软正式推出AI助手—Microsoft Copilot 我们正在进入一个全新的人工智能时代,这个时代从根本上改变了我们与技术的关系以及从技术中受益的方式。随着聊天界面和大型语言模型的融合,您现在可以用自然语言提出请求...


UFO² 是微软推出的面向 Windows 桌面的多Agent操作系统(AgentOS),基于深度系统集成和自然语言交互实现复杂桌面任务的自动化。UFO²基于中央 HostAgent 分解任务协调多个应用专用的 AppAge...
TinyTroupe是microsoft推出的实验性Python库,用在模拟具有特定个性、兴趣和目标的人工代理(TinyPersons),在模拟环境(TinyWorld)中进行互动。TinyTroupe基于大型语言模型(如G...


Text-Diffuser 2是由来自微软研究院、香港科技大学和中山大学的研究人员最新推出的一个基于扩散模型的文本渲染方法,旨在解决图像扩散模型生成文字时在灵活性、自动化、布局预测能力和风格多样性方面的局限性,以提高生成图像...
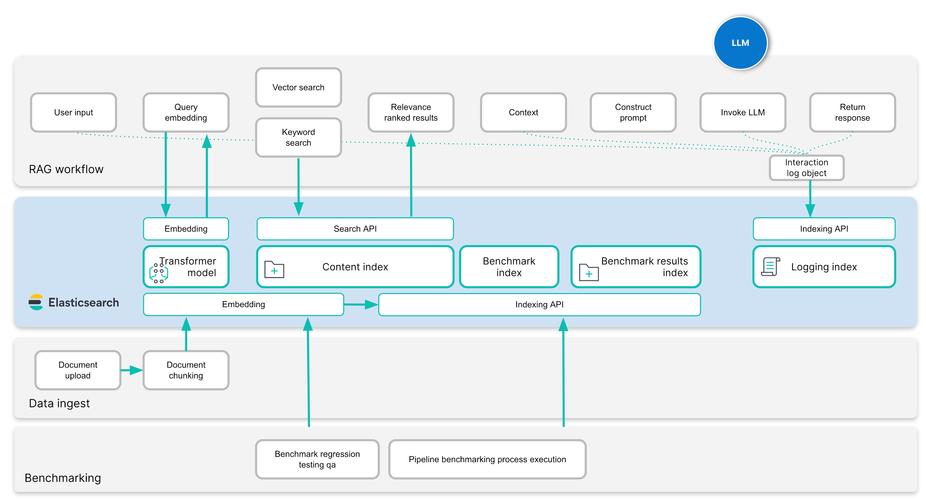
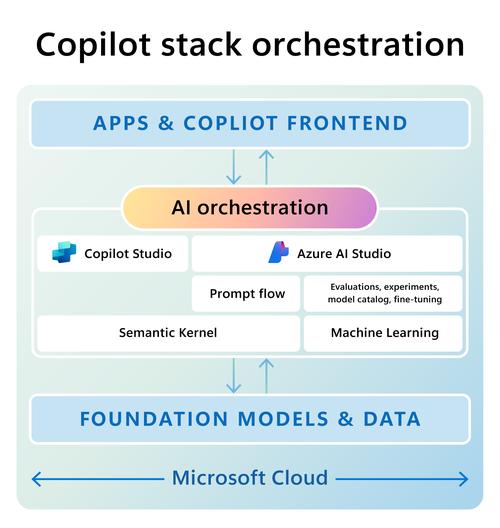
TaskWeaver是由微软推出的一个代码优先的AI智能体框架,专注于无缝规划和执行数据分析任务。基于代码片段解释用户请求,高效协调各种插件(以函数形式)执行数据分析任务,支持状态化的执行方式。TaskWeaver支持丰富的...
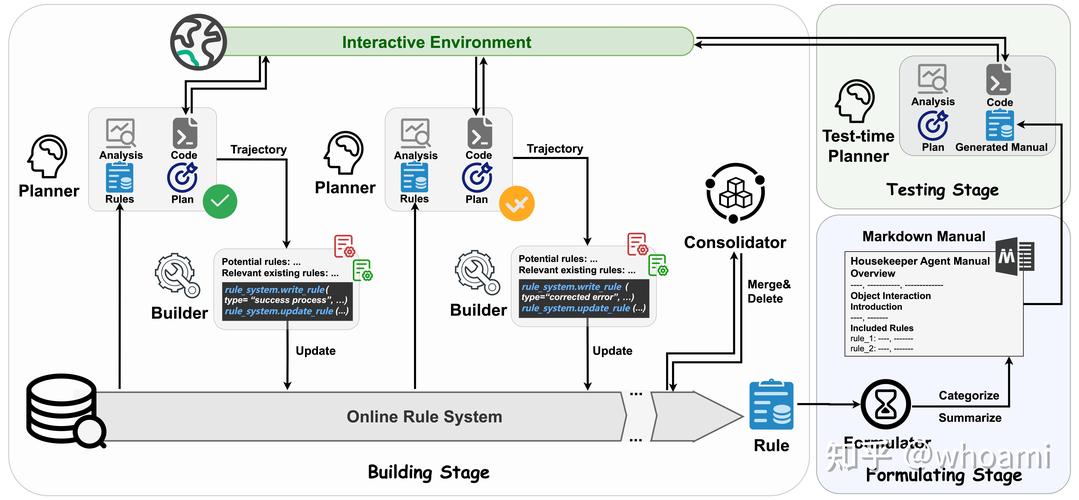
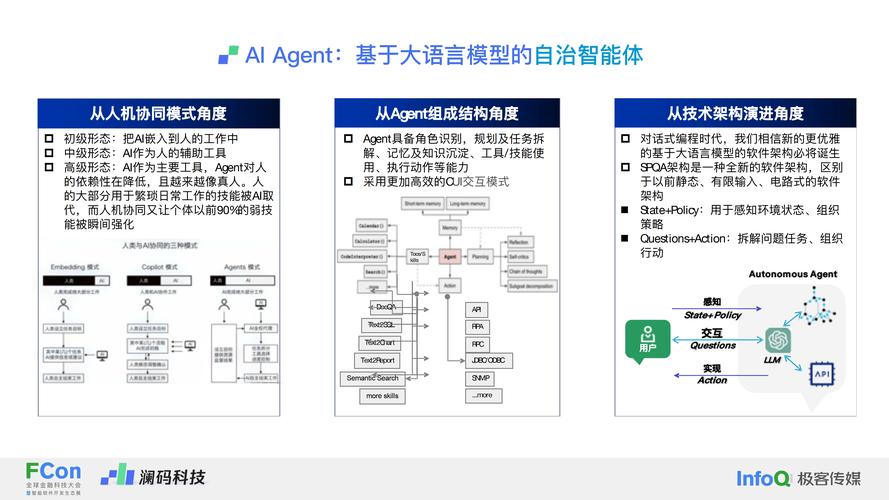
全部评论
留言在赶来的路上...
发表评论