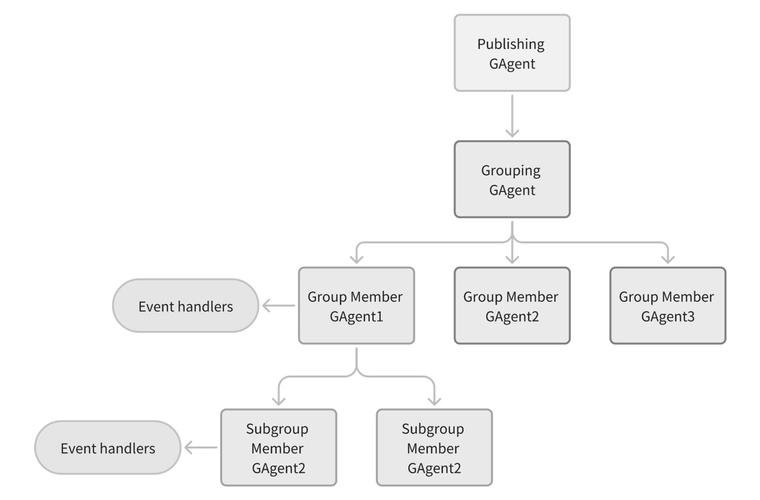
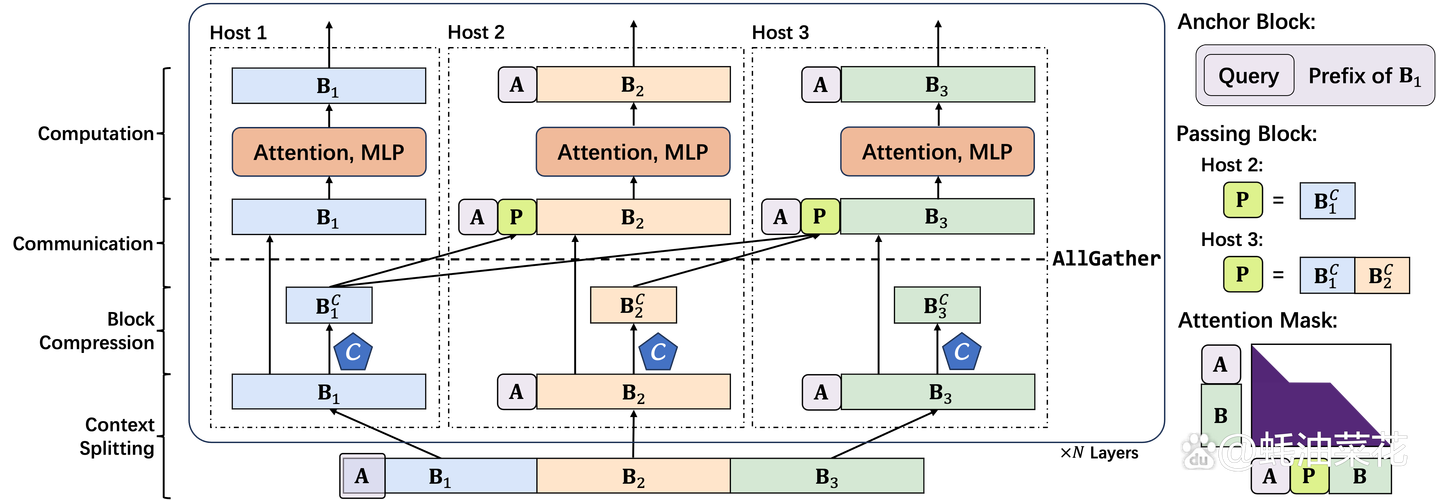
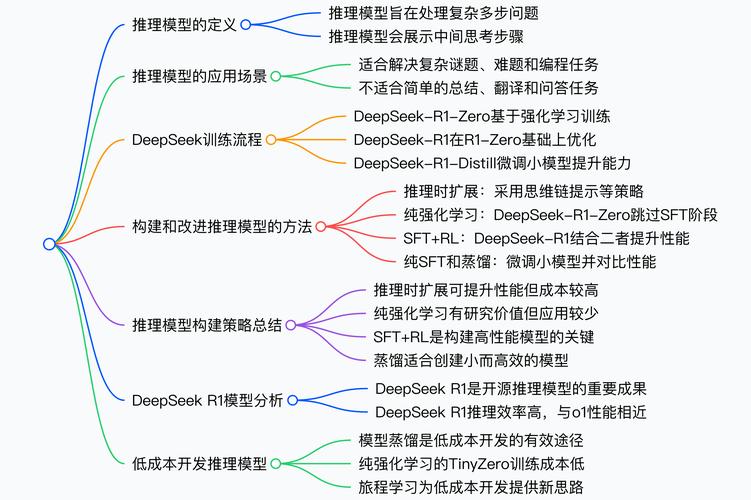
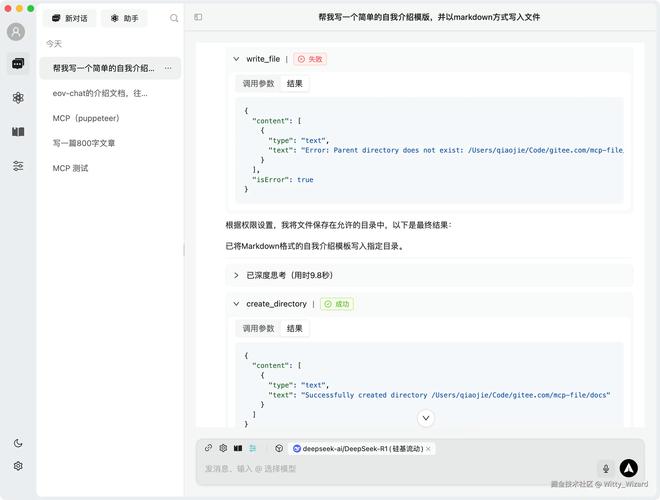
AI工具
发布文章-
发布了文章 2个月前
Kimi-baidu09Researcher – Kimi推出的深度研究Agent模型
Kimi-Researcher 是月之暗面旗下的 Kimi 推出的基于端到端自主强化学习(end-to-end agentic RL)技术训练的新一代 Agent 模型,专为深度研究任务而设计。能自主规划任务执行流程,通过澄...
-
发布了文章 2个月前
Kimi-baidu09Dev – 月之暗面推出的开源代码模型
Kimi-Dev是Moonshot AI推出的开源代码模型,专为软件工程任务设计。模型拥有 72B 参数量,编程水平比最新的DeepSeek-R1还强,和闭源模型比较也表现优异。在 SWE-bench Verified数据集...
-
发布了文章 2个月前
Kimi-baidu09Audio – Moonshot AI 开源的音频基础模型
Kimi-Audio 是 Moonshot AI 推出的开源音频基础模型,专注于音频理解、生成和对话任务。在超过 1300 万小时的多样化音频数据上进行预训练,具备强大的音频推理和语言理解能力。...

-
发布了文章 2个月前
Kimi Latest – Kimi推出的实时更新AI模型,与Kimi智能助手同步
Kimi Latest是月之暗面Kimi推出的实时更新AI模型,为用户提供同步对标Kimi智能助手的模型体验。支持128k上下文长度,可根据输入自动选择8k、32k或128k模型进行计费,同时具备图片理解能力,能处理视觉任务...
-
发布了文章 2个月前
Kiln AI-baidu09 开源 AI 原型设计和数据集协作开发工具,微调专属模型
Kiln AI是开源的 AI 开发工具,能简化大型语言模型(LLM)的微调、合成数据生成和数据集协作。Kiln AI提供直观的桌面应用程序,支持 Windows、MacOS 和 Linux,用户基于零代码方式对多种模型(如...
-
发布了文章 2个月前
Kheish – 开源的多智能体协调平台,可灵活配置多个Agent解决复杂任务
Kheish是开源的、基于大型语言模型(LLM)的多智能体编排平台,用多个专门的角色(智能体)和灵活的工作流协调复杂任务的各个步骤,如提案生成、审核、验证和格式化,产生高质量结果。平台能无缝集成外部模块,例如文件系统访问、s...
-
发布了文章 2个月前
KeySync – 帝国理工联合弗罗茨瓦夫大学推出的口型同步框架
KeySync 是帝国理工学院和弗罗茨瓦夫大学推出的用在高分辨率口型同步框架,支持将输入音频与视频中的口型动作对齐。KeySync 基于两阶段框架实现,首先生成关键帧捕捉音频的关键唇部动作,基于插值生成平滑的过渡帧。...
-
发布了文章 2个月前
Kandinsky-baidu093 – 开源的文本到图像生成框架,适应多种图像生成任务
Kandinsky-3是基于潜在扩散模型的文本到图像(T2I)生成框架,以高质量和逼真度在图像合成领域脱颖而出。Kandinsky-3能适应多种图像生成任务,包括文本引导的修复/扩展、图像融合、文本-图像融合及视频生成等。研...
-
发布了文章 2个月前
KTransformers – 清华开源的大语言模型推理优化框架
KTransformers是清华大学KVCache.AI团队联合趋境科技推出的开源项目,能优化大语言模型的推理性能,降低硬件门槛。KTransformers基于GPU/CPU异构计算策略,用MoE架构的稀疏性,支持在仅24G...
-
发布了文章 2个月前
KHOJ – 开源 AI 个人化助手,一站式知识管理工具
KHOJ是开源的个人化AI助手,帮助用户整合和检索知识。可连接用户的在线和本地文档,如PDF、Markdown、纯文本、GitHub和Notion文件等,通过语义搜索功能,快速找到所需信息。Khoj支持在线AI模型如GPT-...
-
发布了文章 2个月前
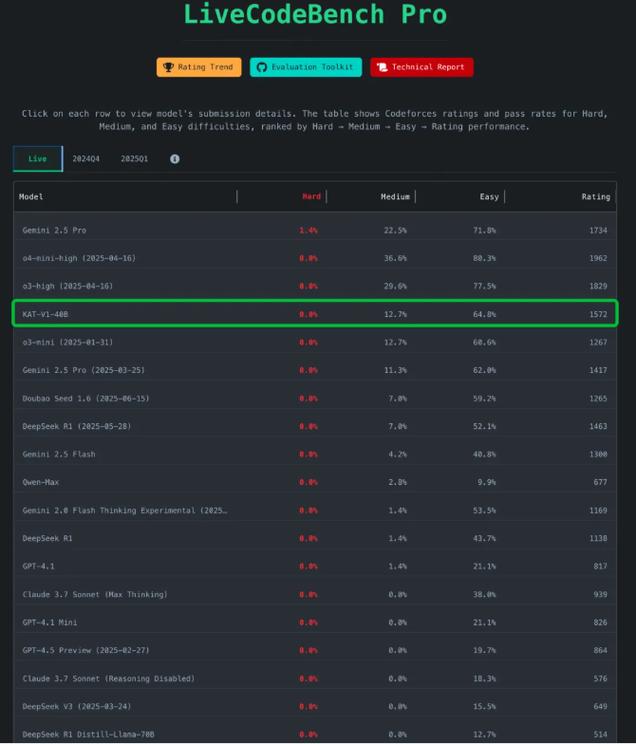
KAT-baidu09V1 – 快手开源的自动思考模型
KAT-V1是快手开源的自动思考(AutoThink)大模型,包含40B和200B两个版本。模型融合思考与非思考能力,能根据问题难度自动切换思考模式。40B版本性能逼近DeepSeek-R1(6850亿参数),200B版本在...
-
发布了文章 2个月前
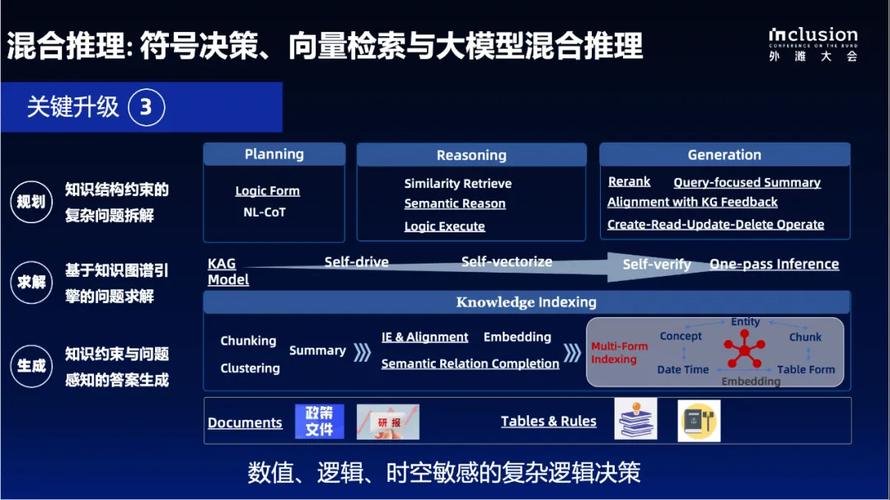
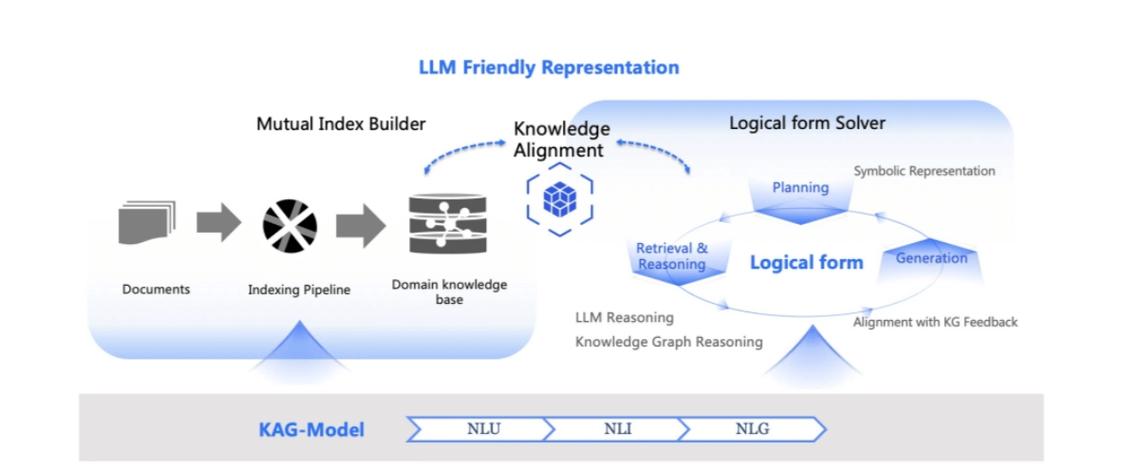
KAG – 蚂蚁集团推出的专业领域知识服务框架
KAG(Knowledge Augmented Generation)是蚂蚁集团推出的专业领域知识服务框架,基于知识增强提升大型语言模型(LLMs)在特定领域的问答性能,为垂直领域的知识库构建逻辑推理和问答解决方案。KAG基...
-
发布了文章 2个月前
JoyVASA – 京东健康开源的音频驱动的数字人头项目
JoyVASA是京东健康国际公司开源的音频驱动的数字人头项目,基于扩散模型技术,根据音频信号生成与音频同步的面部动态和头部运动。JoyVASA能实现人物的唇形同步和表情控制,还扩展到动物头像的动画生成,在多语种支持和跨物种动...
-
发布了文章 2个月前
JoyHallo – 京东推出的音频驱动视频生成AI数字人模型
JoyHallo 是京东开源的AI数字人模型,专为普通话设计,能根据音频生成逼真的说话视频。特别适合处理普通话的复杂口型和语调,具有跨语言生成视频的能力。...
-
发布了文章 2个月前
JoyGen – 京东和港大推出音频驱动的3D说话人脸视频生成框架
JoyGen是京东科技和香港大学推出的,音频驱动的3D说话人脸视频生成框架,专注于实现精确的唇部与音频同步及高质量的视觉效果。JoyGen结合音频特征和面部深度图,驱动唇部运动的生成,用单步UNet架构进行高效的视频编辑。J...