Kandinsky-3是基于潜在扩散模型的文本到图像(T2I)生成框架,支持高质量和逼真度在图像合成。Kandinsky-3能适应多种图像生成任务,包括文本引导的修复/扩展、图像融合、文本-图像融合及视频生成等。研究者们推出一个简化版本的T2I模型版本,该版本在保持图像质量的同时,将推理速度提高3倍,仅需4步逆向过程即可完成。Kandinsky-3的显著特点在于架构的简洁性和高效性,能适应多种图像生成任务。

(图片来源网络,侵删)

(图片来源网络,侵删)


Kandinsky-3是基于潜在扩散模型的文本到图像(T2I)生成框架,支持高质量和逼真度在图像合成。Kandinsky-3能适应多种图像生成任务,包括文本引导的修复/扩展、图像融合、文本-图像融合及视频生成等。研究者们推出一个简化版本的T2I模型版本,该版本在保持图像质量的同时,将推理速度提高3倍,仅需4步逆向过程即可完成。Kandinsky-3的显著特点在于架构的简洁性和高效性,能适应多种图像生成任务。

图像生成推理大模型,港中文北大等联手破解画质提升难题 图像生成模型,也用上思维链(CoT)了!来自港中文、北大和上海AI Lab的研究团队,将CoT与生成模型结合到了一起。实验结果表明,他们的这种方法能有效提高自回归图...






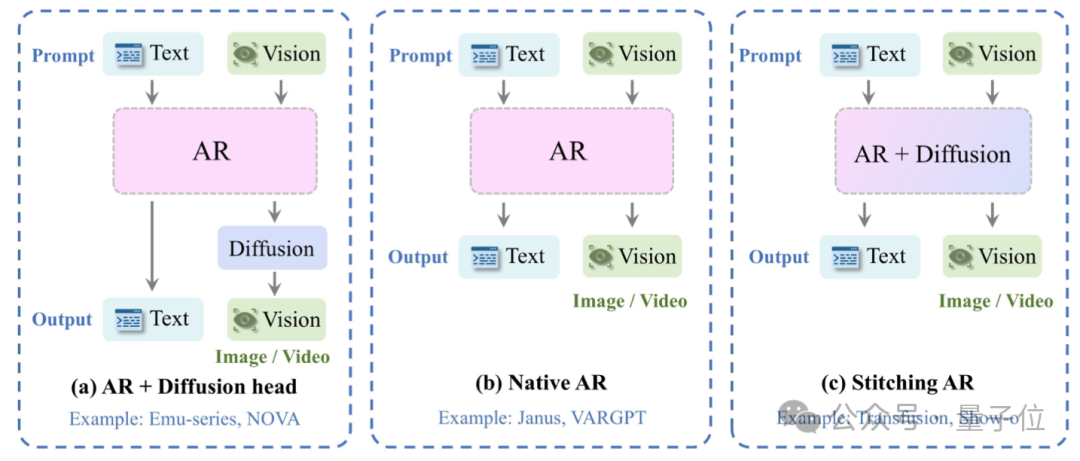
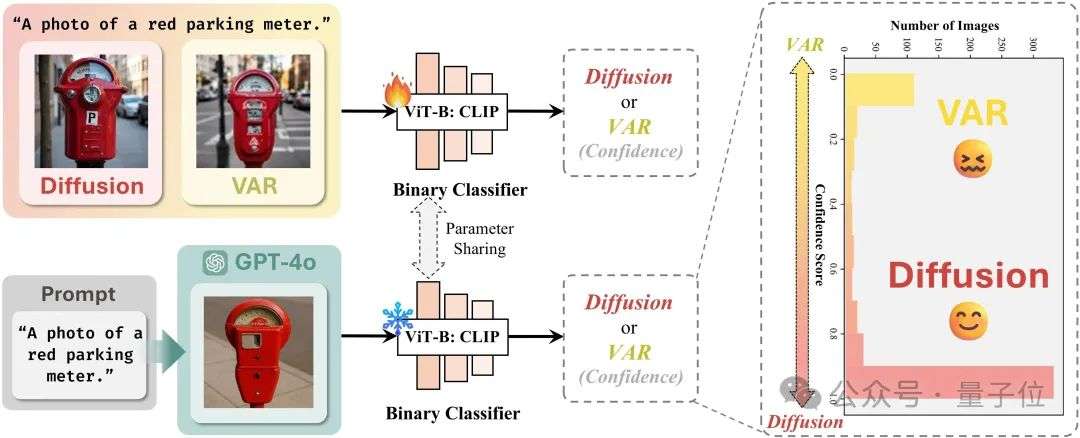
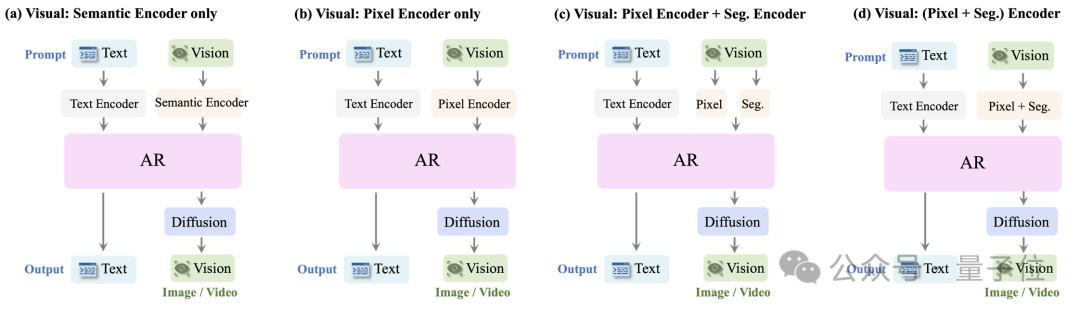
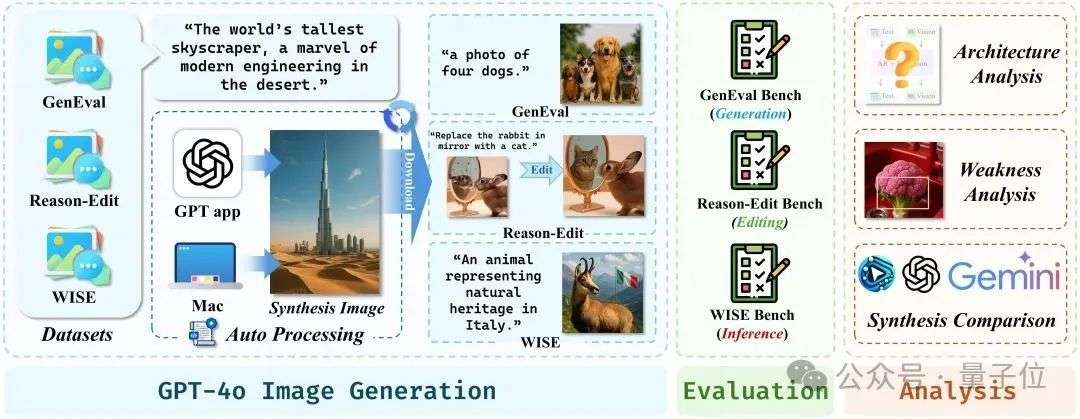
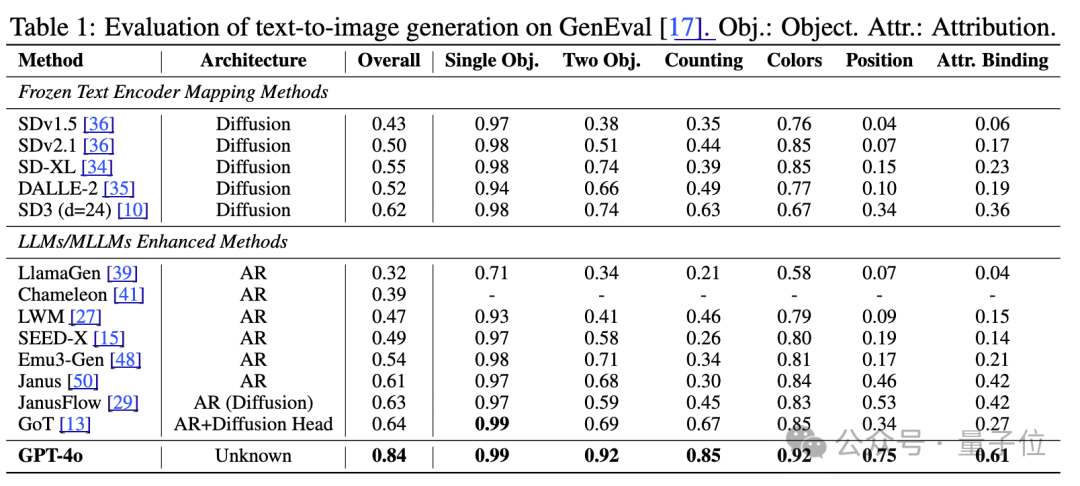
GPT-4o图像生成架构被“破解”了?自回归主干+扩散解码器,还有4o图像生成全面测评基准 GPT-4o图像生成架构被“破解”了!最近一阵,...

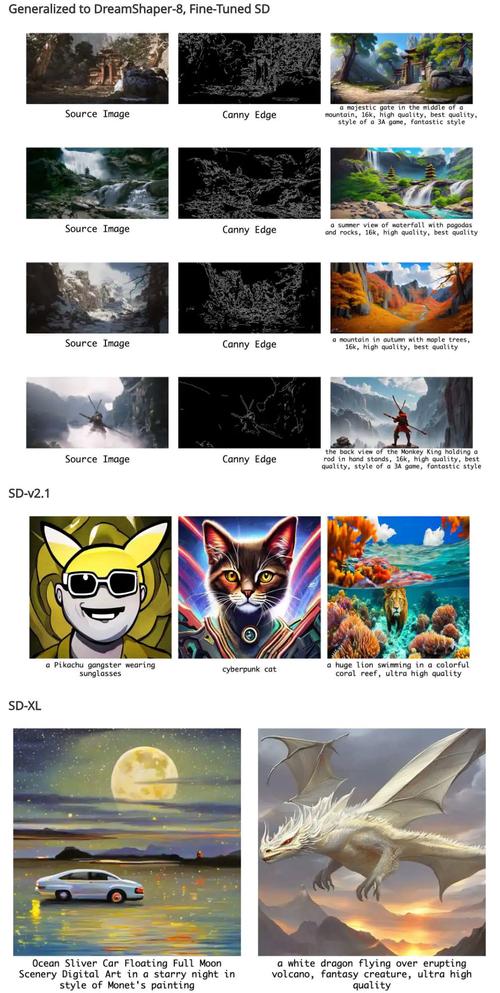
StochSync(Stochastic Diffusion Synchronization)是创新的图像生成技术,专门用于在复杂空间(如360°全景图或3D表面纹理)中生成高质量图像。结合了扩散同步(DS)和分数蒸馏采样(...

LinFusion 是新加坡国立大学研究团队开发的一种创新图像生成模型,基于线性注意力机制来处理高分辨率图像生成任务。使模型在处理大量像素时的计算复杂度保持线性,显著提高生成效率。...
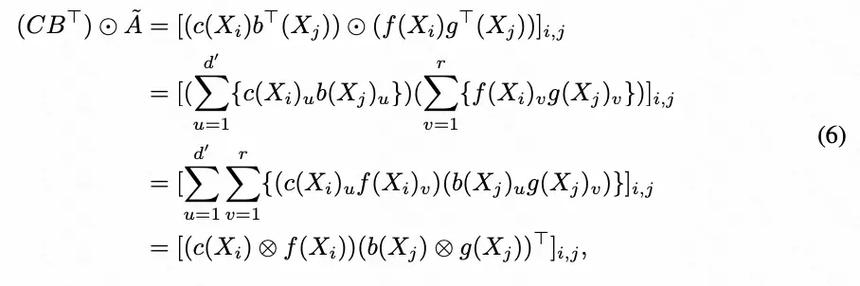
Illustrious是开源的文本到图像动漫图像生成模型,是Onoma AI Research推出的。基于优化批量大小、dropout控制、训练图像分辨率和多级标题等关键方法,实现高分辨率、动态色域和高还原能力的图像生成。模...


EveryoneNobel是一个开源AI工具,为每个人生成个性化的诺贝尔奖风格图像。EveryoneNobel基于ComfyUI框架,结合HTML模板和图像生成技术,用户只需上传肖像照片、提供基本信息,如姓名和获奖主题,系统...


全部评论
留言在赶来的路上...
发表评论