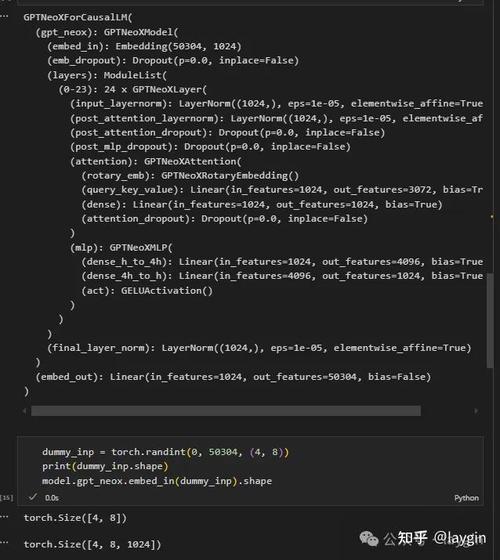
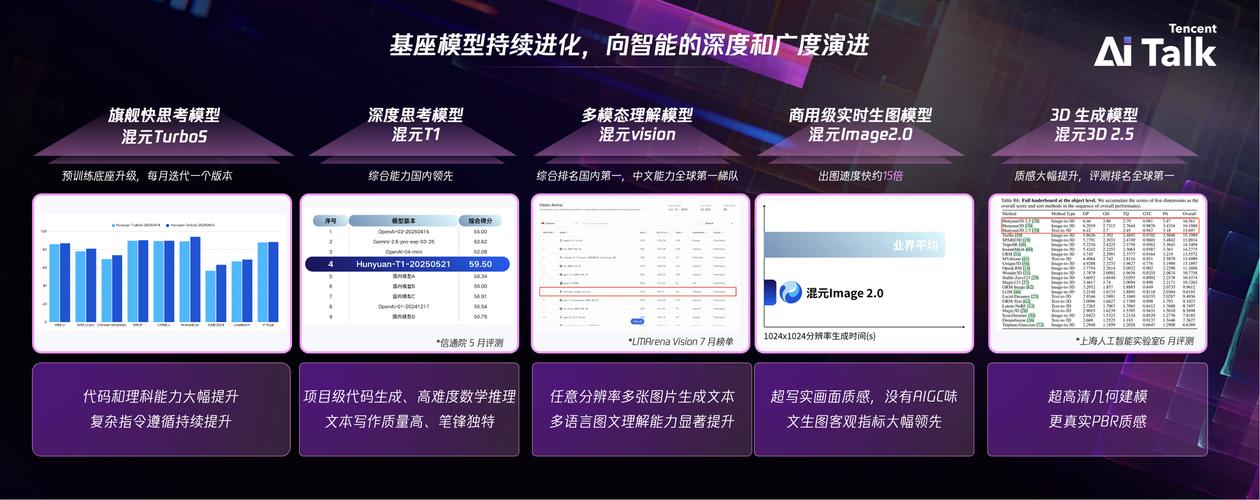
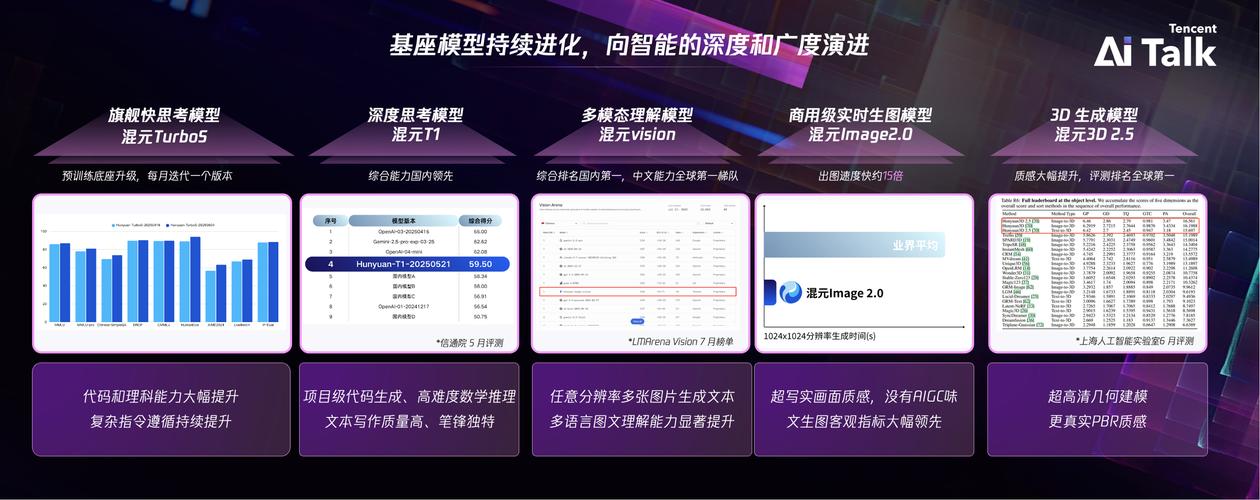
AI工具
发布文章-
发布了文章 2个月前
InvSR – 开源图像超分辨率模型,高清修复老旧照片
InvSR是创新的图像超分辨率模型,基于扩散模型的逆过程恢复高分辨率图像。用大型预训练扩散模型中丰富的图像先验,改善超分辨率的效果。InvSR的核心在于深度噪声预测器,预测器能估计出在正向扩散过程中所需的最优噪声图。...
-
发布了文章 2个月前
InternVideo2.5 – 上海 AI Lab 联合南大、中科院开源的视频多模态大模型
InternVideo2.5是上海人工智能实验室联合南京大学、中科院深圳先进技术研究院共同开源的视频多模态大模型。在视频理解领域取得了显著进展,特别是在长视频处理和细粒度时空感知方面表现出色。模型能处理长达万帧的视频,视频处...
-
发布了文章 2个月前
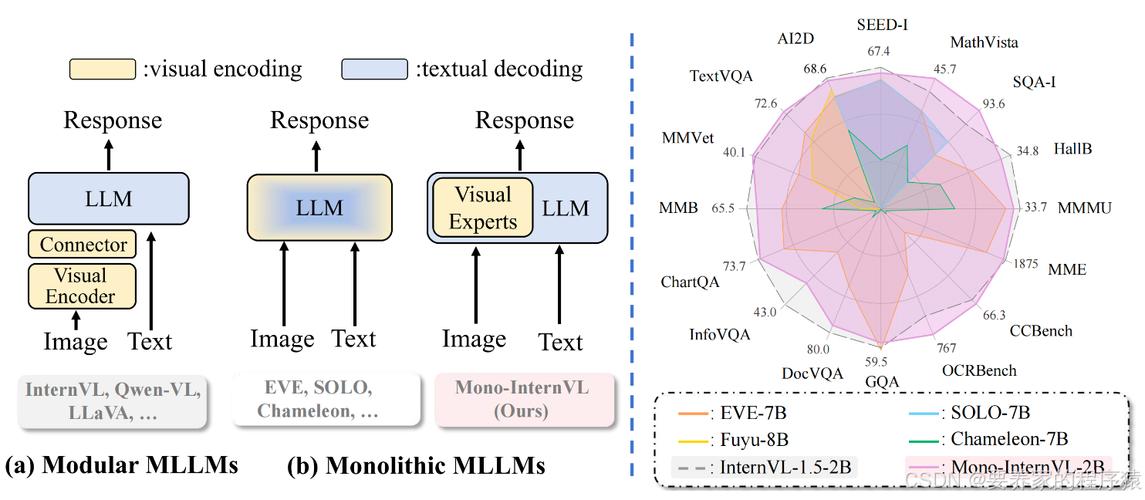
InternVL3 – 上海 AI Lab 开源的多模态大语言模型
InternVL3是上海人工智能实验室开源的多模态大型语言模型(MLLM),具有卓越的多模态感知和推理能力。模型系列包括1B到78B共7个不同尺寸的版本,能同时处理文字、图片、视频等多种信息。...
-
发布了文章 2个月前
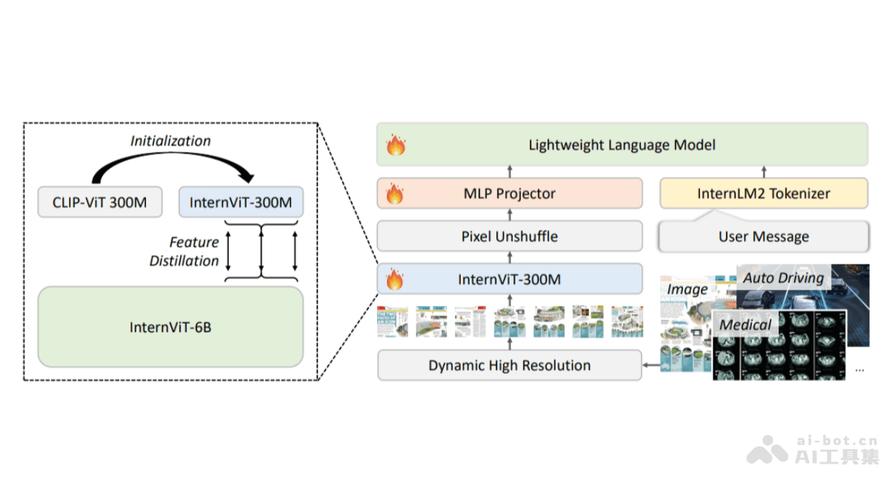
InternVL – OpenGVLab 推出的多模态大模型
InternVL 是上海人工智能实验室 OpenGVLab 推出的多模态大模型,专注于视觉与语言任务。采用 ViT-MLP-LLM 架构,通过视觉模块(如 InternViT)和语言模块(如 InternLM)的融合,实现视...
-
发布了文章 2个月前
Intern-baidu09S1-baidu09mini – 上海AI Lab开源的轻量级科学多模态推理模型
Intern-S1-mini是上海人工智能实验室推出的轻量级开源多模态推理模型。基于与 Intern-S1 相同的技术构建。模型融合 8B 密集语言模型(Qwen3)和 0.3B 视觉编码器(InternViT),在包含 2...
-
发布了文章 2个月前
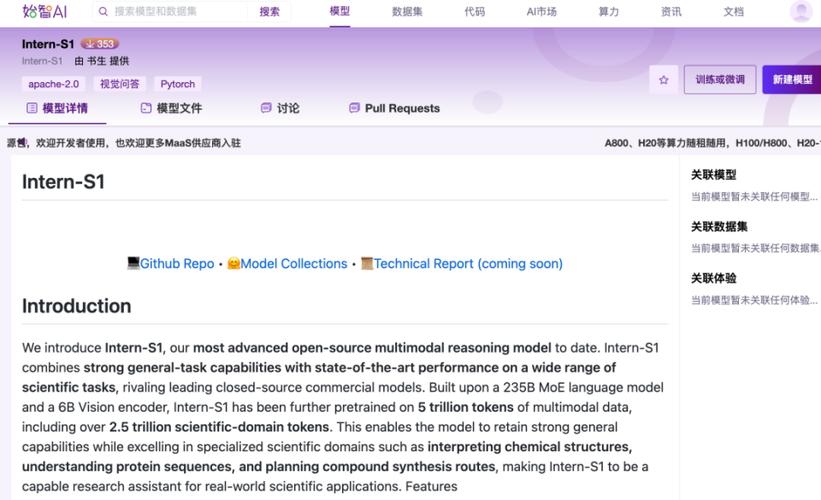
Intern-baidu09S1 – 上海AI Lab推出的科学多模态大模型
Intern-S1是上海人工智能实验室在世界人工智能大会上正式开源发布的科学多模态大模型,融合了语言和多模态性能,具备高水平的均衡发展能力,并富集多学科专业知识,在科学领域表现出色。Intern-S1首创“跨模态科学解析引擎...
-
发布了文章 2个月前
InteriorGS – 群核科技推出的高质量3D高斯语义数据集
InteriorGS 是群核科技推出的高质量的3D高斯语义数据集,包含1000个3D高斯语义场景,涵盖80多种室内环境,如家庭、便利店、婚宴厅和博物馆。数据集包含755个类别的554,000多个对象实例,每个对象都有3D框和...
-
发布了文章 2个月前
InstructMove – 东京大学联合 Adobe 推出基于指令的图像编辑模型
InstructMove是东京大学和Adobe公司联合推出的基于指令的图像编辑模型,通过观察视频中的帧对变化学习如何根据指令进行图像操作。模型基于多模态大型语言模型(MLLMs)生成描述帧对之间变化的编辑指令,训练出能在保持...
-
发布了文章 2个月前
Instella – AMD开源的30亿参数系列语言模型
Instella是AMD推出的系列30亿参数的开源语言模型。模型完全从零开始在AMD Instinct™ MI300X GPU上训练而成,基于自回归Transformer架构,包含36个解码器层和32个注意力头,支持最长40...
-
发布了文章 2个月前
InstantStyle – 开源的个性化文本到图像生成框架,保留风格一致性
InstantStyle是小红书的InstantX团队开源的保留风格一致性的个性化文本到图像生成框架,旨在解决文本到图像生成中的一个关键问题:如何在保持风格一致性的同时生成图像。...
-
发布了文章 2个月前
InstantCharacter – 腾讯混元开源的定制化图像生成插件
InstantCharacter 是腾讯混元开源的定制化图像生成插件。基于扩散 Transformer(DiT)框架,引入可扩展的适配器(包含多个 Transformer encoder)和千万级样本的大规模角色数据集,实现...
-
发布了文章 2个月前
InspireMusic – 阿里通义实验室开源的音乐生成技术
InspireMusic 是阿里巴巴通义实验室开源的音乐生成技术,通过人工智能为用户生成高质量的音乐作品。基于多模态大模型技术,支持通过简单的文字描述或音频提示快速生成多种风格的音乐。...
-
发布了文章 2个月前
Insight-baidu09V – 提升长链视觉推理能力的多模态模型
Insight-V是南洋理工大学、腾讯公司和清华大学的研究者们共同推出的多模态模型,能提升多模态大型语言模型在长链视觉推理方面的能力。基于可扩展的数据生成流程生产高质量的推理数据,采用多智能体系统将视觉推理任务分解为推理和总...
-
发布了文章 2个月前
Insert Anything – 浙大联合哈佛大学和南洋理工推出的图像插入框架
Insert Anything是浙江大学、哈佛大学和南洋理工大学的研究人员联合推出的基于上下文编辑的图像插入框架。框架基于将参考图像中的对象无缝插入到目标场景中,支持多种实际应用场景,如艺术创作、真实人脸替换、电影场景合成、...
-
发布了文章 2个月前
Ingredients – 多ID照片定制视频生成框架,基于多ID照片与视频扩散相结合
Ingredients是强大的框架,基于将多个特定身份(ID)照片与视频扩散Transformer相结合,用在定制视频创作。Ingredients基于三个核心模块实现高度定制化的视频生成:面部提取器、多尺度投影器和ID路由器...