JoyHallo 是京东开源的模型,专为普通话设计,能根据音频生成逼真的说话视频。特别适合处理普通话的复杂口型和语调,具有跨语言生成视频的能力。JoyHallo 提供了一个开源的数据集和模型训练方法,使用户可以生成普通话和英语的说话人视频。项目基于中文wav2vec2模型进行音频特征嵌入,采用半解耦结构来提升推理速度,提高了14.3%。

(图片来源网络,侵删)

(图片来源网络,侵删)


JoyHallo 是京东开源的模型,专为普通话设计,能根据音频生成逼真的说话视频。特别适合处理普通话的复杂口型和语调,具有跨语言生成视频的能力。JoyHallo 提供了一个开源的数据集和模型训练方法,使用户可以生成普通话和英语的说话人视频。项目基于中文wav2vec2模型进行音频特征嵌入,采用半解耦结构来提升推理速度,提高了14.3%。

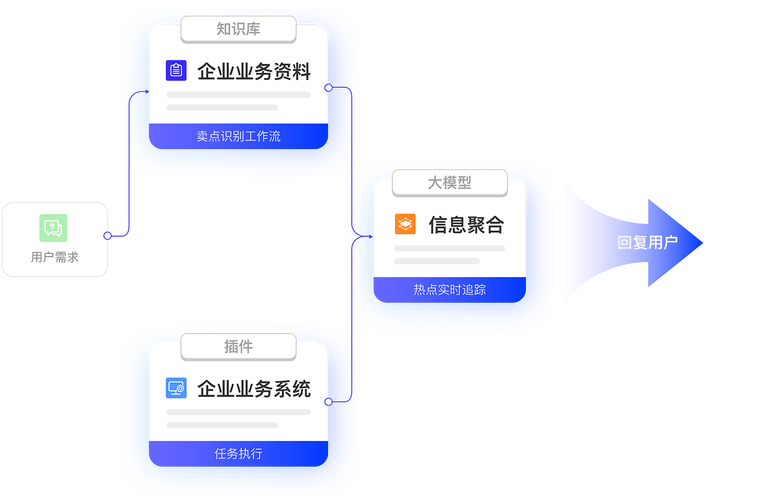
JoyAgent-JDGenie是京东开源的首个高完成度轻量化通用多智能体产品,作为完整的端到端智能体系统,无需二次开发能直接使用,支持多种任务处理,如生成报告、分析数据等。...

全部评论
留言在赶来的路上...
发表评论