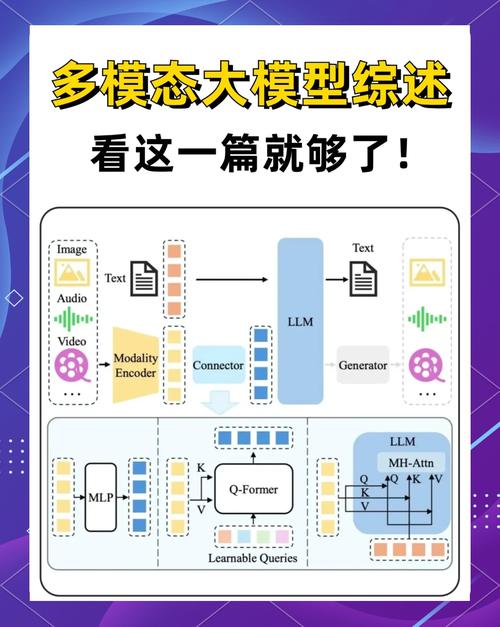
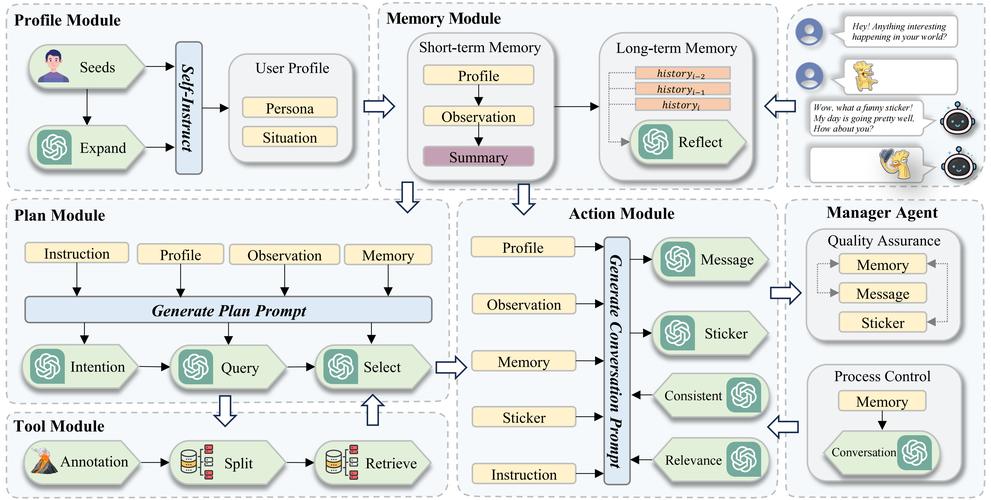
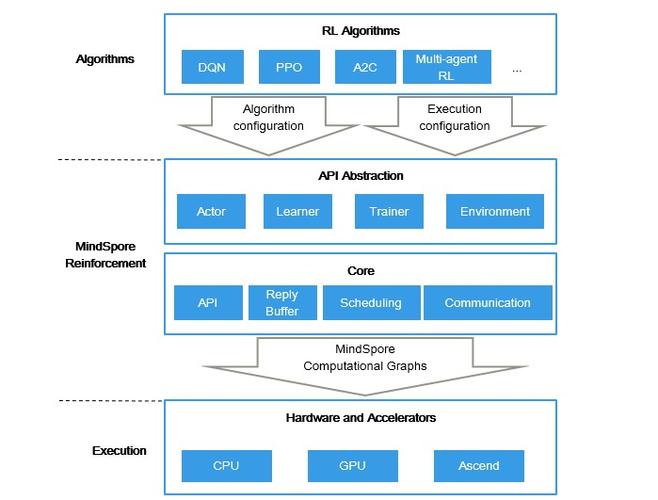
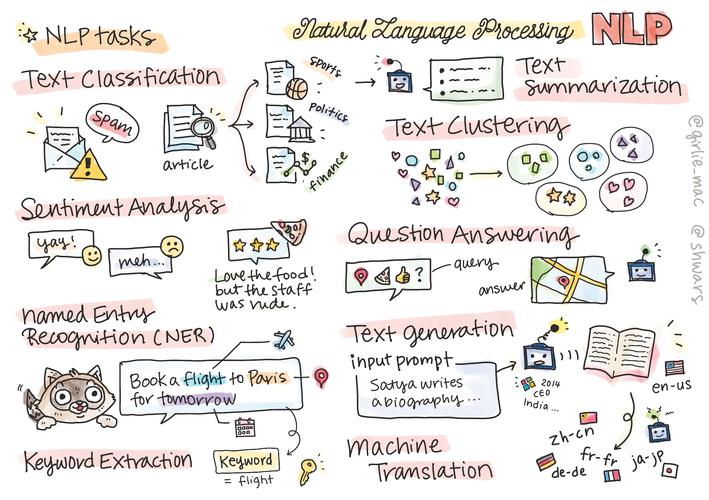
AI工具
发布文章-
发布了文章 2个月前
LaTRO – 基于自我奖励提升LLMs复杂推理能力的框架
LaTRO(Latent Reasoning Optimization)是先进的框架,提升大型语言模型(LLMs)在复杂推理任务中的表现。基于将推理过程类比为从潜在分布中采样,用变分推断方法进行优化,LaTRO让模型自我改进...
-
发布了文章 2个月前
LaDeCo – 西安交大联合微软推出的自动图形设计构图方法
LaDeCo是西安交通大学和微软研究院联合推出的自动图形设计构图方法,基于将设计任务分解为层次化的步骤来实现。LaDeCo对输入的设计元素进行层规划,将它们分配到不同的语义层,比如背景、底层、图像/标志、文本和装饰。...
-
发布了文章 2个月前
La Plateforme – Mistral AI公司推出的AI开发工具
La Plateforme是Mistral AI公司推出AI开发工具,支持用户通过微调来优化AI模型,更好地适应特定的应用场景和数据集。在La Plateforme上用户能够用自己的数据来训练和调整模型,提升模型的性能和准确...
-
发布了文章 2个月前
LVCD – 腾讯联合香港城市大学推出为动漫视频线稿上色的AI框架
LVCD(Large Video Color Diffusion)是一个专为动画视频线稿上色设计的视频扩散框架,能将黑白线稿自动转化为彩色动画视频。LVCD使用了一种先进的扩散模型,可以同时处理整个视频序列,保证每一帧的颜色...
-
发布了文章 2个月前
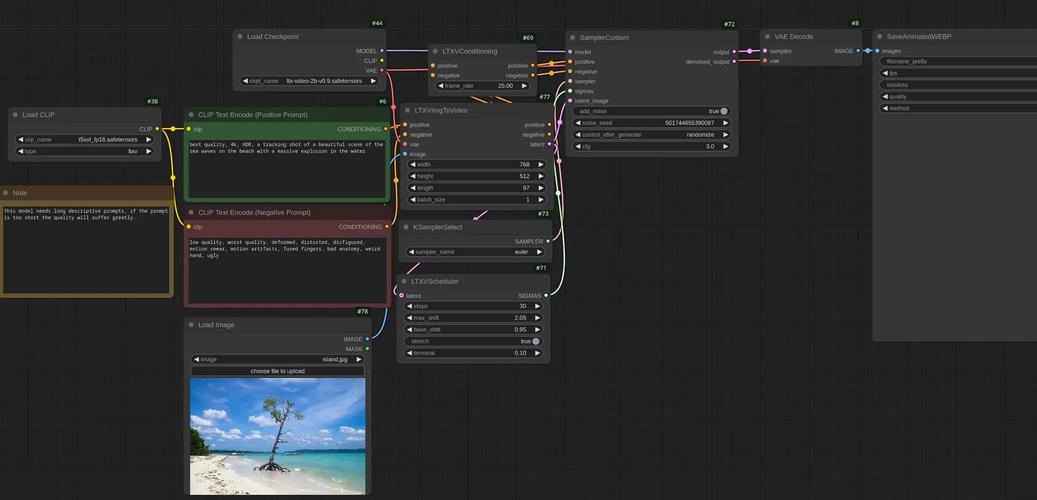
LTXV-baidu0913B – Lightricks开源的最新视频生成模型
LTXV-13B 是Lightricks推出的开源 AI 视频生成模型,拥有 130 亿参数。具备极高的生成速度,比同类产品快 30 倍,能在普通消费级显卡(如 4090/5090)上运行,推理速度快且成本低。...
-
发布了文章 2个月前
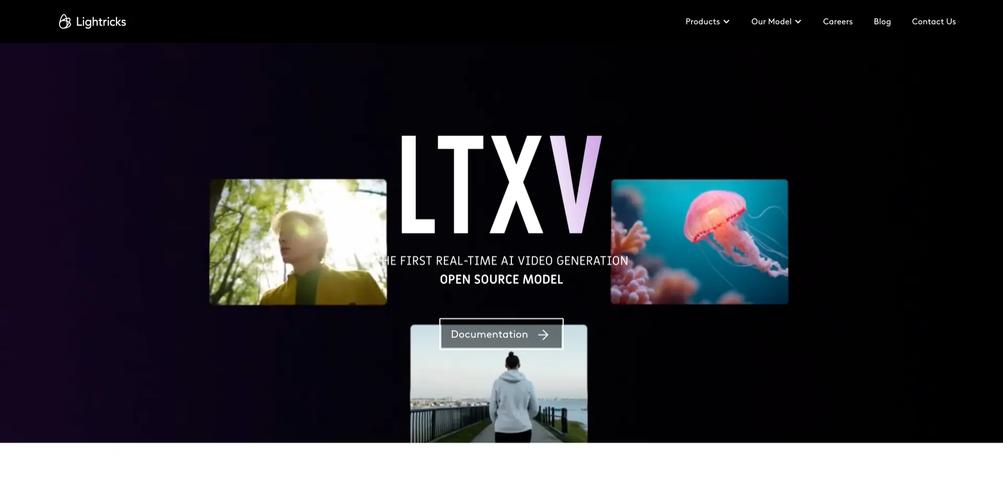
LTX Video – Lightricks推出的开源AI视频生成模型
LTX Video是Lightricks推出的开源AI视频生成模型,能在4秒内生成5秒的高质量视频,速度超过观看速度。基于2亿参数的DiT架构,确保帧间平滑运动和结构一致性,解决了早期视频生成模型的关键限制。LTX Vide...
-
发布了文章 2个月前
LTM-baidu092-baidu09mini – Magic公司推出的支持1亿token上下文AI模型
LTM-2-mini是Magic公司推出的支持1亿token上下文AI模型,能处理相当于1000万行代码或750本小说的内容。LTM-2-mini采用序列维度算法,计算效率比Llama 3.1 405B的注意力机制高出约10...
-
发布了文章 2个月前
LOKI – 中山大学联合上海AI Lab推出的合成数据检测基准
LOKI是由中山大学和上海AI Lab联合提出的合成数据检测基准,旨在全面评估大型多模态模型(LMMs)在识别视频、图像、3D、文本和音频等多种模态合成数据的能力。包含18,000多个问题,覆盖26个子类别,采用多层次标注,...
-
发布了文章 2个月前
LMMs-baidu09Eval – 专为多模态AI模型设计的统一评估框架
LMMs-Eval 是一个专为多模态AI模型设计的统一评估框架,提供标准化、广泛覆盖且成本效益高的模型性能评估解决方案。包含超过50个任务和10多个模型,通过透明和可复现的评估流程,帮助研究者和开发者全面理解模型能力。...
-
发布了文章 2个月前
LMEval – 谷歌开源的统一评估多模态AI模型框架
LMEval 是谷歌推出的开源框架,用在简化大型模型(LLMs)的跨提供商评估。框架支持多模态(文本、图像、代码)和多指标评估,兼容 Google、OpenAI、Anthropic 等主流模型提供商。LMEval 基于增量评...
-
发布了文章 2个月前
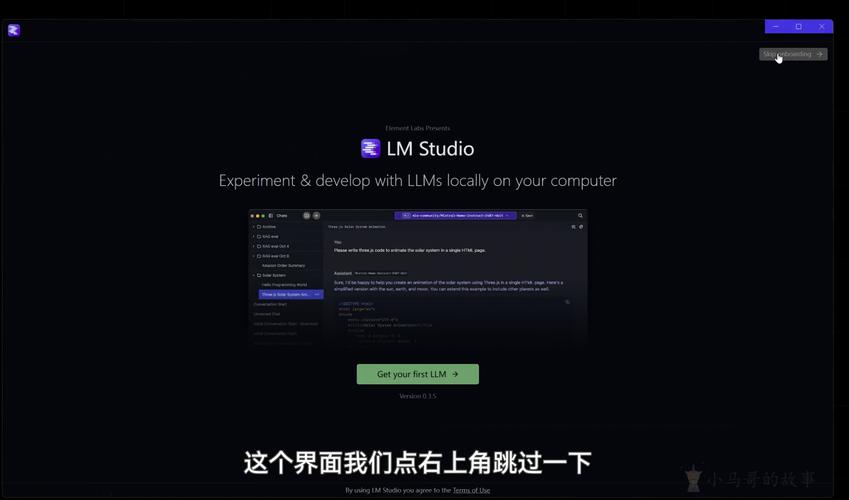
LM Studio – 开源、傻瓜、一站式部署本地大模型 (LLM) 的应用平台
LM Studio 是一个本地大语言模型 (LLM 应用平台,开源、傻瓜、一站式部署本地大模型。包括但不限于Llama、MPT、Gemma等,LM Studio 提供了一个图形用户界面(GUI),即使是非技术人员也能轻松地...
-
发布了文章 2个月前
LLaVA-baidu09o1 – 北大清华联合多所机构推出开源的视觉语言模型
LLaVA-o1是北京大学、清华大学、鹏城实验室、阿里巴巴达摩院以及理海大学(Lehigh University)组成的研究团队推出的开源视觉语言模型,基于Llama-3.2-Vision模型构建,能进行自主的多阶段“慢思考...
-
发布了文章 2个月前
LLaVA-baidu09Rad – 微软推出的小型多模态模型,专注于临床放射学报告生成
LLaVA-Rad是微软研究院推出的小型多模态模型,专注于临床放射学报告生成。是LLaVA-Med项目的分支,特别是胸部X光(CXR)成像。基于LLaVA-Med的基础架构和训练方法,针对放射学领域的特定需求进行了优化。...
-
发布了文章 2个月前
LLaVA-baidu09OneVision – 字节跳动推出的开源多模态AI模型
LLaVA-OneVision是字节跳动推出开源的多模态AI模型,LLaVA-OneVision通过整合数据、模型和视觉表示的见解,能同时处理单图像、多图像和视频场景下的计算机视觉任务。LLaVA-OneVision支持跨模...
-
发布了文章 2个月前
LLaMA-baidu09Omni – 中科院推出的低延迟高质量的语音交互模型
LLaMA-Omni 是中国科学院计算技术研究所和中国科学院大学研究者推出的新型模型架构,用于实现与大型语言模型(LLM)的低延迟、高质量语音交互。通过集成预训练的语音编码器、语音适配器、大型语言模型(LLM)和一个实时语音...