

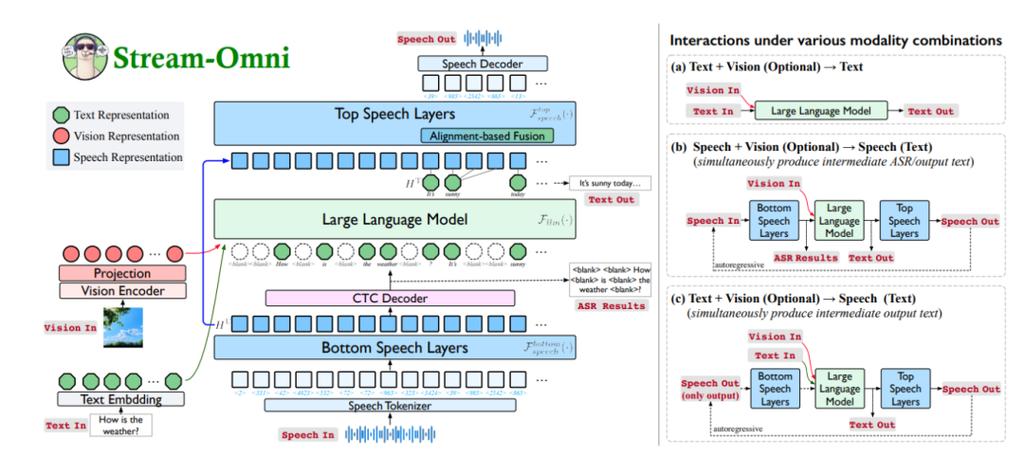
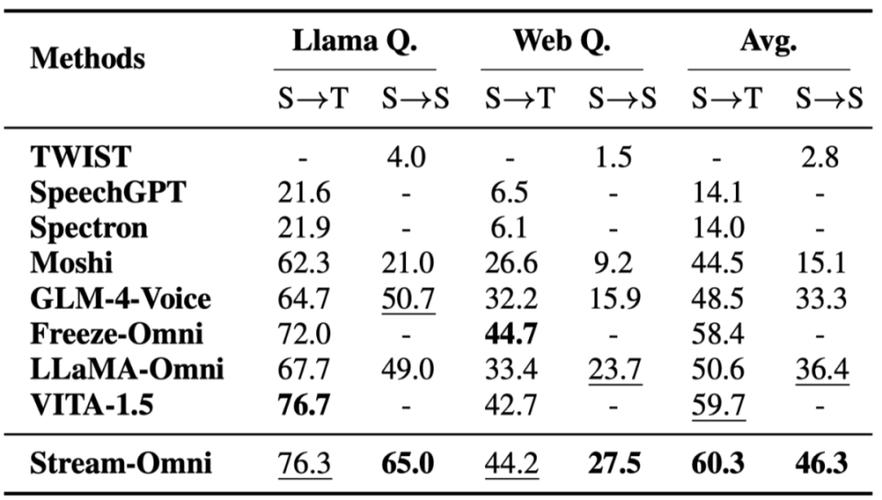
LLaMA-Omni 是中国科学院计算技术研究所和中国科学院大学研究者推出的新型模型架构,用于实现与大型语言模型(LLM)的低延迟、高质量语音交互。通过集成预训练的语音编码器、语音适配器、大型语言模型(LLM)和一个实时语音解码器,直接从语音指令中快速生成文本和语音响应,省略传统的必须先将语音转录为文本的步骤,提高了响应速度。模型基于最新的 LLaMA-3.1-8B-Instruct 模型构建,并使用自建的 InstructS2S-200K 数据集进行训练,快速生成响应,延迟低至 226 毫秒。此外,LLaMA-Omni 的训练效率高,4 个 GPU 训练不到 3 天即可完成,为未来基于最新 LLM 的语音交互模型的高效开发奠定基础。

(图片来源网络,侵删)

(图片来源网络,侵删)


全部评论
留言在赶来的路上...
发表评论