

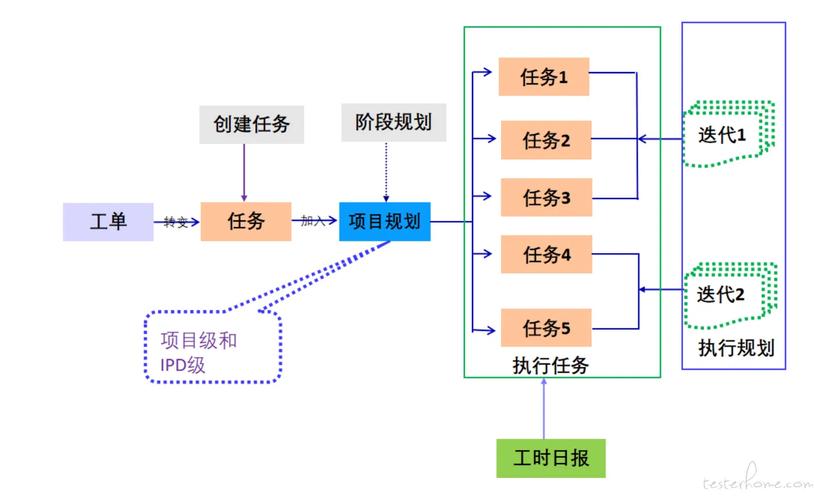
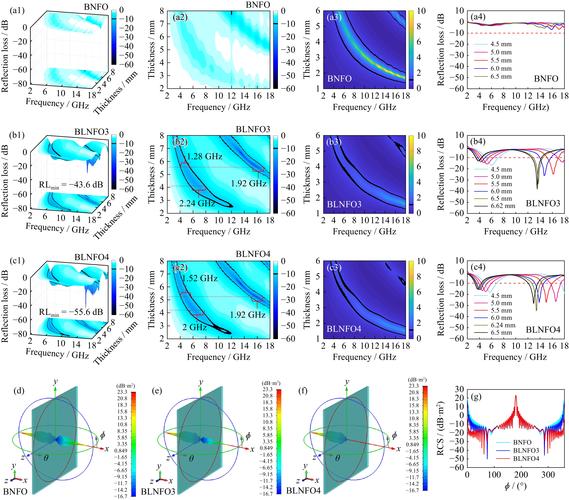
Jodi是中国科学院计算技术研究所和中国科学院大学推出的扩散模型框架,基于联合建模图像域和多个标签域,将视觉生成与理解统一起来。Jodi基于线性扩散Transformer和角色切换机制,执行联合生成(同时生成图像和多个标签)、可控生成(基于标签组合生成图像)及图像感知(从图像预测多个标签)三种任务。Jodi用包含20万张高质量图像和7个视觉域标签的Joint-1.6M数据集进行训练。Jodi在生成和理解任务中均表现出色,展现强大的可扩展性和跨领域一致性。

(图片来源网络,侵删)

(图片来源网络,侵删)

全部评论
留言在赶来的路上...
发表评论