

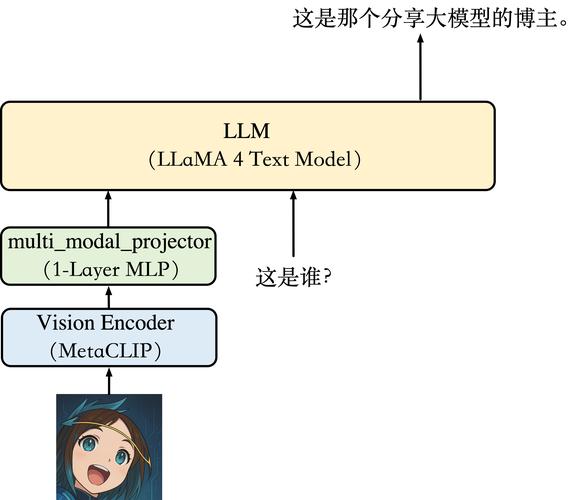
Stream-Omni是中国科学院计算技术研究所智能信息处理重点实验室、中国科学院人工智能安全重点实验室及中国科学院大学联合推出的类似的大型语言视觉语音模型,能同时支持多种模态组合的交互。模型支持大型语言模型为骨干,基于序列维度拼接实现视觉文本对齐,基于CTC的层维度映射实现语音文本对齐,高效地将文本能力迁移到语音模态。Stream-Omni在视觉理解、语音交互及视觉引导的语音交互任务上表现出色,基于少量的全模态数据(如23000小时语音数据)训练。模型能在语音交互过程中同时提供中间文本输出,如自动语音识别(ASR)转录和模型响应,为用户提供更丰富的多模态交互体验。

(图片来源网络,侵删)

(图片来源网络,侵删)

全部评论
留言在赶来的路上...
发表评论