LLaVA-OneVision是字节跳动推出开源的多模态AI模型,LLaVA-OneVision通过整合数据、模型和视觉表示的见解,能同时处理单图像、多图像和视频场景下的计算机视觉任务。LLaVA-OneVision支持跨模态/场景的迁移学习,特别在图像到视频的任务转移中表现出色,具有强大的视频理解和跨场景能力。

(图片来源网络,侵删)

(图片来源网络,侵删)


LLaVA-OneVision是字节跳动推出开源的多模态AI模型,LLaVA-OneVision通过整合数据、模型和视觉表示的见解,能同时处理单图像、多图像和视频场景下的计算机视觉任务。LLaVA-OneVision支持跨模态/场景的迁移学习,特别在图像到视频的任务转移中表现出色,具有强大的视频理解和跨场景能力。

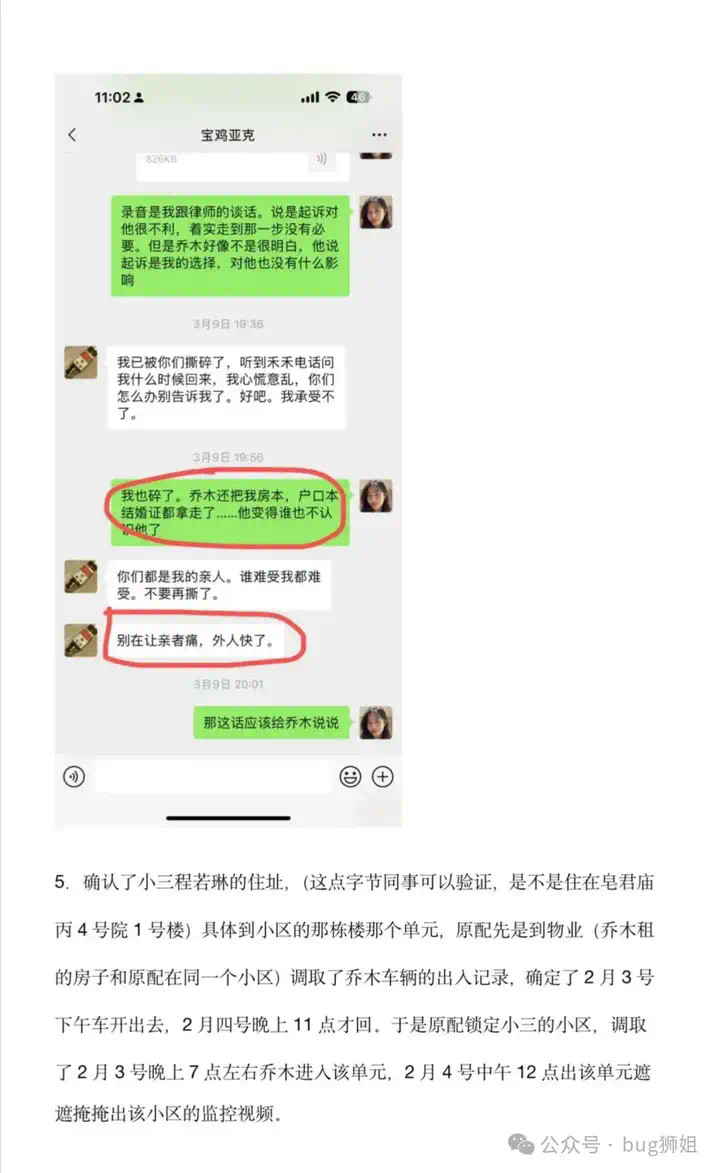
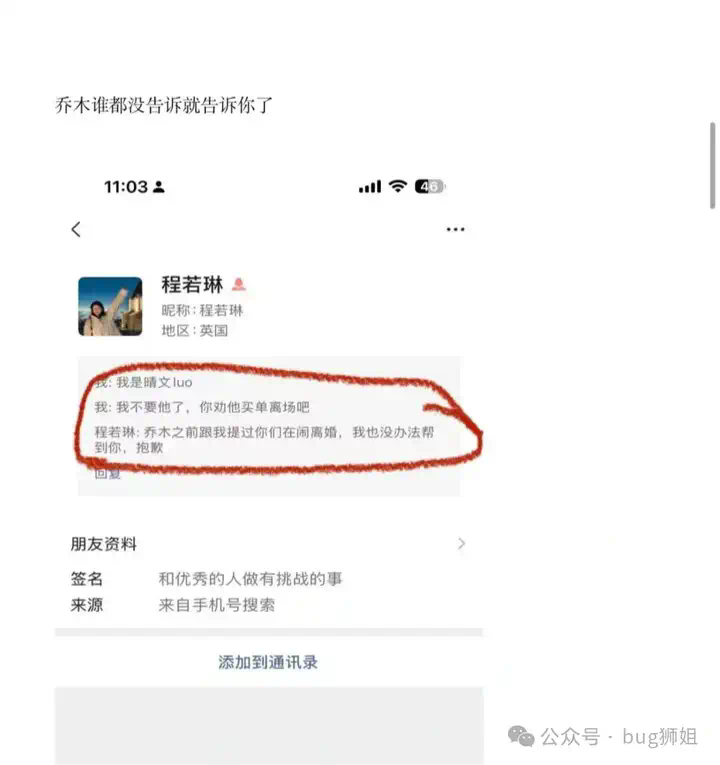
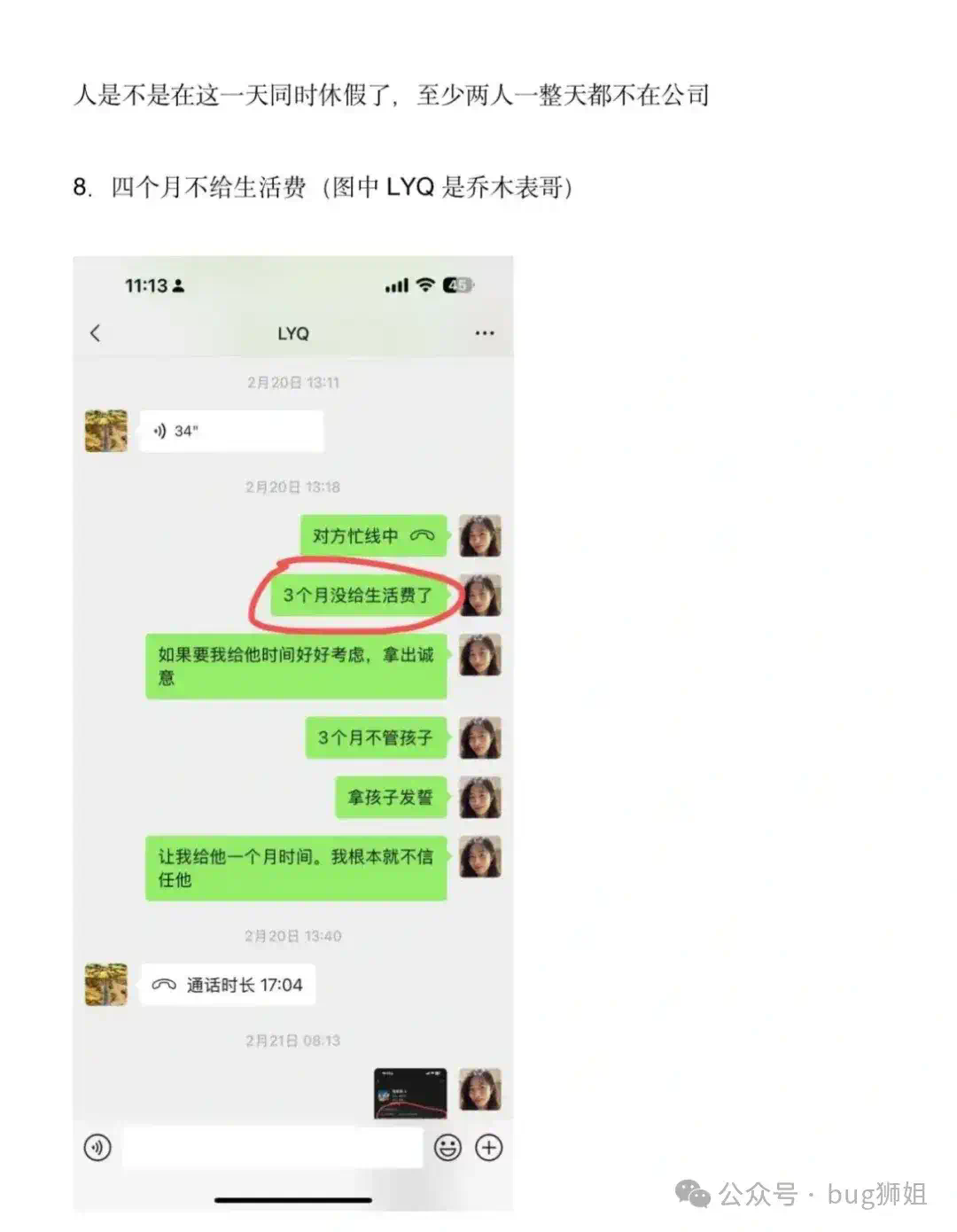
AI大瓜!字节豆包LLM负责人婚内出轨同组HRBP 今天字节暴了一个八卦,豆包LLM技术负责人乔某婚内出轨HRBP程某某,还不给原配自己亲女儿抚养费。据说乔某已经结婚11年了,2014年进入字节,有两个女儿,而程之前还...



字节按下 AI Agent 加速键 经历了 2025 年初 DeepSeek、Manus 们的冲击,大厂正在重新明确自己下一步的战略。...

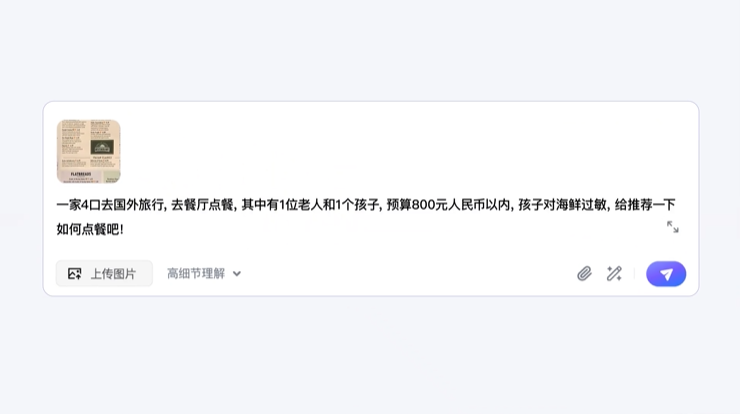

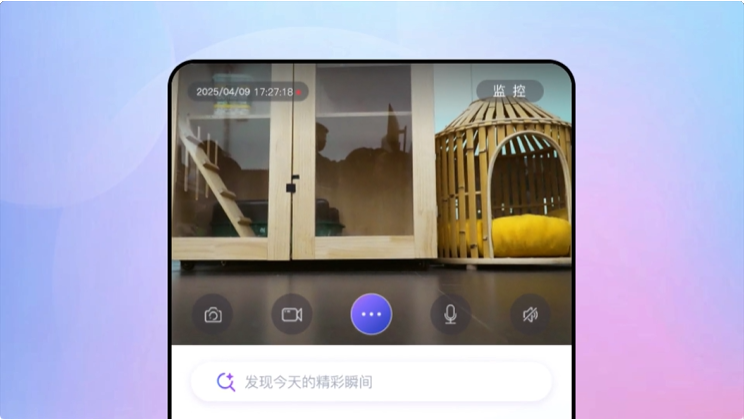
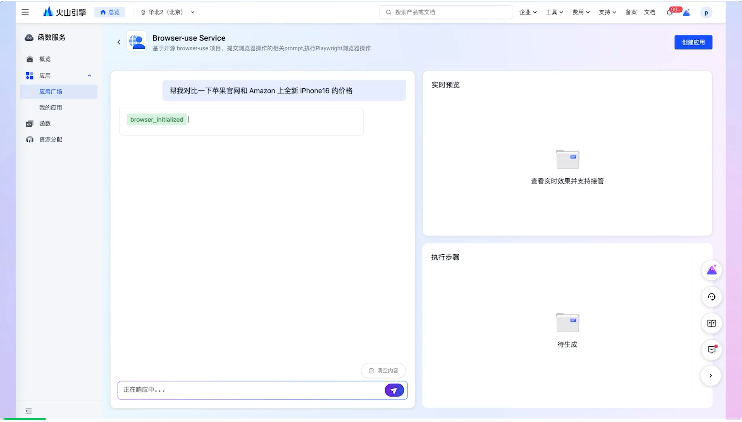
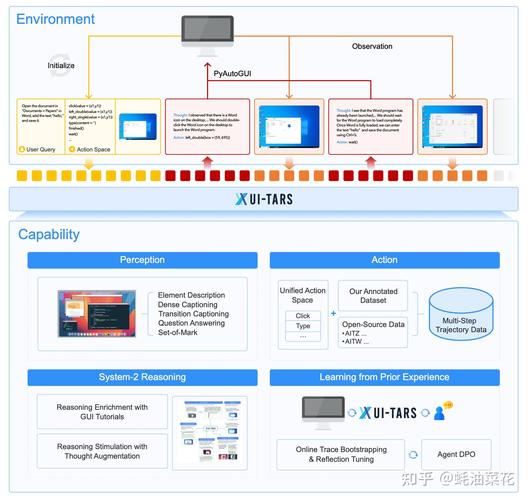
UI-TARS 是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,通过自然语言实现对桌面、移动设备和网页界面的自动化交互。具备强大的感知、推理、行动和记忆能力,能实时理解动态界面,通过多模态输入(如文本、图像)执行复...
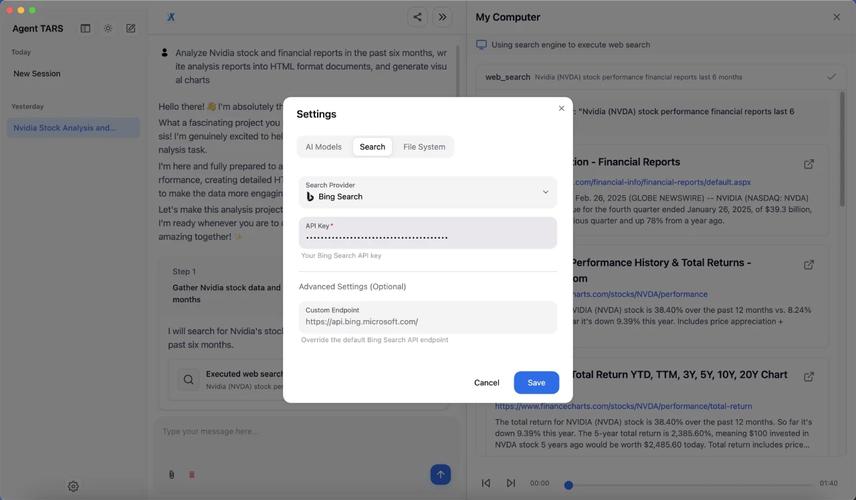
Seed-X是字节跳动Seed团队推出的开源多语言翻译模型,拥有70亿参数,支持28种语言的双向翻译。Seed-X通过高质量的多语言数据预训练、指令微调和强化学习相结合的方式,显著提升翻译能力,在处理复杂语言模式和生硬翻译时...

Seed-OSS 是字节跳动 Seed 团队开源的系列大型语言模型,专注于长文本处理、推理和智能代理能力。模型包含多个版本,如 Seed-OSS-36B-Base 和 Seed-OSS-36B-Instruct,分别在通用能...
Seed-ASR是字节跳动开发的一款基于大型语言模型(LLM)的语音识别(ASR)模型。在超过2000万小时的语音数据和近90万小时的配对ASR数据上训练,支持普通话和13种中国方言的转录,能识别英语和其他7种外语的语音。...

Seaweed-7B 是字节跳动团队推出的视频生成模型,拥有约 70 亿参数。Seaweed-7B具备强大的视频生成能力。模型支持从文本描述、图像或音频生成高质量的视频内容,支持多种分辨率和时长,广泛应用于视频创作、动画生成...
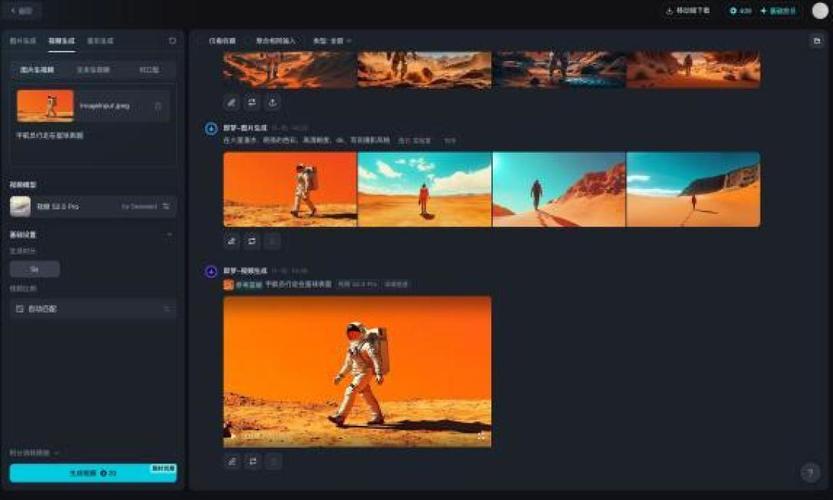

EX-4D是字节跳动(ByteDance)旗下Pico团队推出的新型4D视频生成框架,能从单目视频输入生成极端视角下的高质量4D视频。框架基于独特的深度防水网格(DW-Mesh)表示,显式建模可见和被遮挡区域,确保在极端相机...

全部评论
留言在赶来的路上...
发表评论