

字节联动
-
发布了文章 2个月前
xAR – 字节联合霍普金斯大学推出的自回归视觉生成框架
xAR 是字节跳动和约翰·霍普金斯大学联合提出的新型自回归视觉生成框架。框架通过“下一个X预测”(Next-X Prediction)和“噪声上下文学习”(Noisy Context Learning)技术,解决了传统自回归...
-
发布了文章 2个月前
X-baidu09Dyna – 字节联合斯坦福等高校推出的动画生成框架
X-Dyna 是基于扩散模型的动画生成框架,基于驱动视频中的面部表情和身体动作,将单张人类图像动画化,生成具有真实感和环境感知能力的动态效果。核心是 Dynamics-Adapter 模块,能将参考图像的外观信息有效地整合到...
-
发布了文章 2个月前
UniTok – 字节联合港大、华中科技推出的统一视觉分词器
UniTok 是字节跳动联合香港大学和华中科技大学推出的统一视觉分词器,能同时支持视觉生成和理解任务。基于多码本量化技术,将视觉特征分割成多个小块,每块用独立的子码本进行量化,极大地扩展离散分词的表示能力,解决传统分词器在细...
-
发布了文章 2个月前
TextHarmony – 字节联合华东师范推出的多模态生成模型
TextHarmony是华东师范大学和字节跳动共同推出的多模态生成模型,擅长理解和生成视觉文本。模型基于Slide-LoRA技术,动态聚合特定于模态和模态无关的LoRA专家,部分解耦多模态生成空间,在单一模型实例中协调视觉和...
-
发布了文章 2个月前
PhotoDoodle – 字节联合新加坡国立大学等推出的艺术化图像编辑框架
PhotoDoodle是新加坡国立大学、上海交通大学、北京邮电大学、字节跳动和Tiamat团队联合推出的艺术化图像编辑框架,基于少量样本学习艺术家的独特风格,实现照片涂鸦(photo doodling)。PhotoDoodl...

-
发布了文章 2个月前
MimicTalk – 字节联合浙大推出的开源3D数字人头项目
MimicTalk是浙江大学和字节跳动共同研发推出的,基于NeRF(神经辐射场)技术,能在极短的时间内,仅需15分钟训练出个性化和富有表现力的3D说话人脸模型。MimicTalk提高了训练效率,基于高效的微调策略和具有上下文...
-
发布了文章 2个月前
MMaDA – 字节联合普林斯顿大学等推出的多模态扩散模型
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越...
-
发布了文章 2个月前
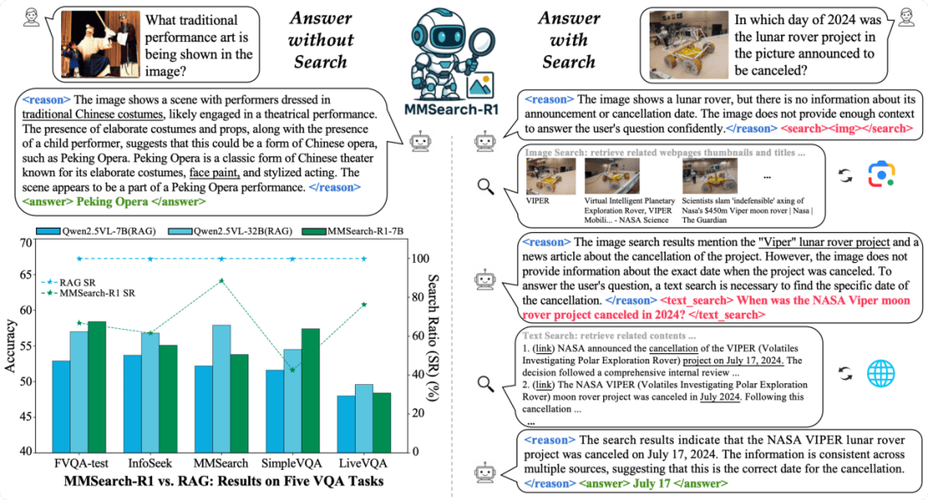
LiveCC – 字节联合新加坡国立大学开源的实时视频解说模型
LiveCC 是新加坡国立大学Show Lab 团队联合字节跳动推出的实时视频解说模型,基于自动语音识别(ASR)字幕进行大规模训练。LiveCC像专业解说员一样快速分析视频内容,同步生成自然流畅的语音或文字解说。...
-
发布了文章 2个月前
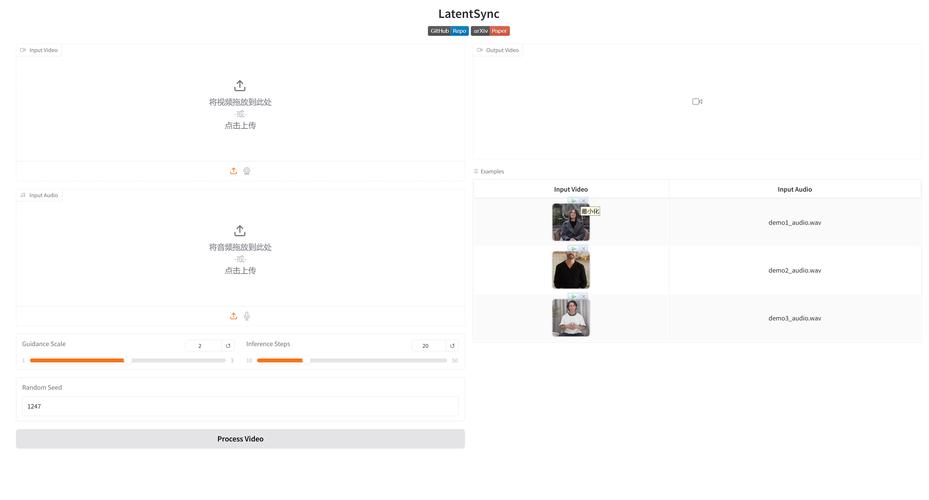
LatentSync – 字节联合北交大开源的端到端唇形同步框架
LatentSync是字节跳动、北京交通大学联合推出的端到端唇形同步框架,基于音频条件的潜在扩散模型,无需任何中间的3D表示或2D特征点。LatentSync用Stable Diffusion的强大生成能力,捕捉复杂的视听关...
-
发布了文章 2个月前
FutureX – 字节联合复旦等高校推出的动态实时评估基准
FutureX是字节跳动、复旦大学、斯坦福大学和普林斯顿大学的研究团队联合发布的,专为LLM智能体未来预测任务设计的动态实时评估基准。通过半自动化管道从195个高质量网站实时收集未来事件问题,在事件解决后自动获取真实结果进行...

-
发布了文章 2个月前
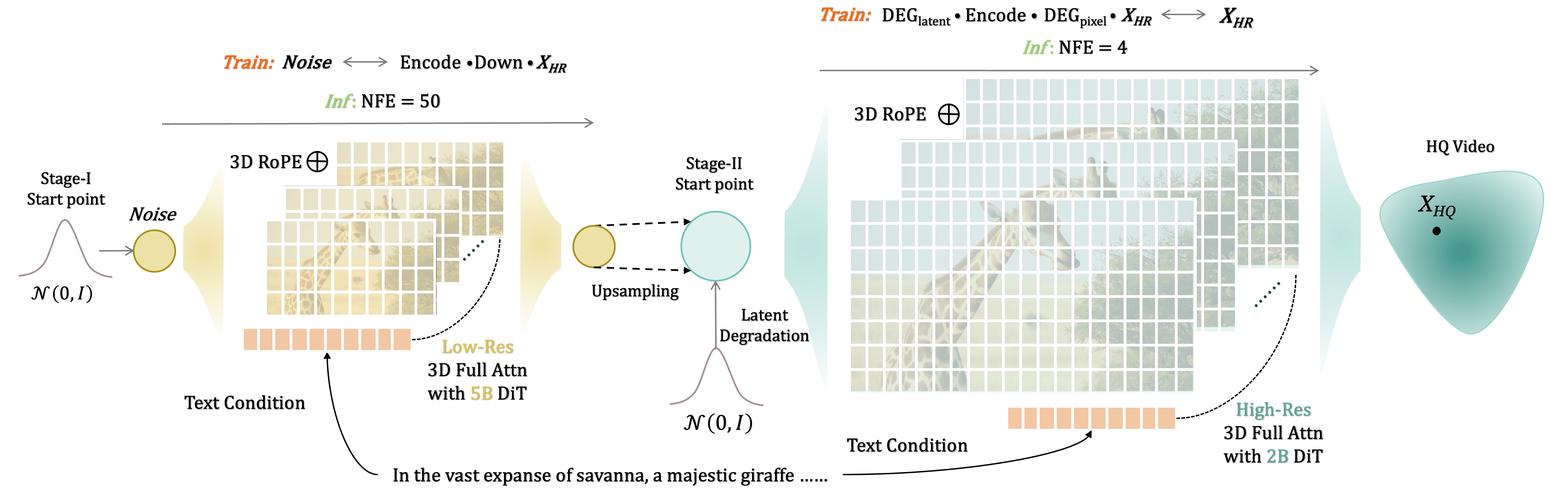
FlashVideo – 字节联合港大推出的高分辨率视频生成框架
FlashVideo是字节跳动团队提出的高效的高分辨率视频生成框架,通过两阶段方法解决了传统单阶段扩散模型在高分辨率视频生成中面临的巨大计算成本问题。在第一阶段,FlashVideo 使用 50 亿参数的大型模型在低分辨率(...
-
发布了文章 2个月前
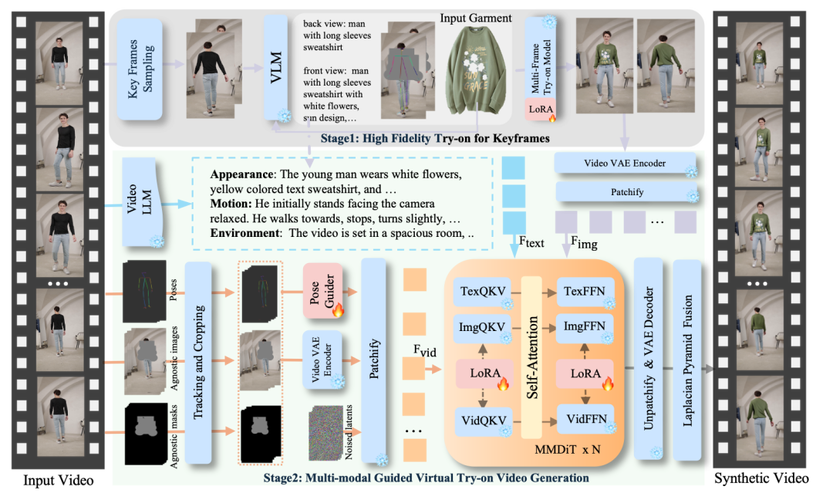
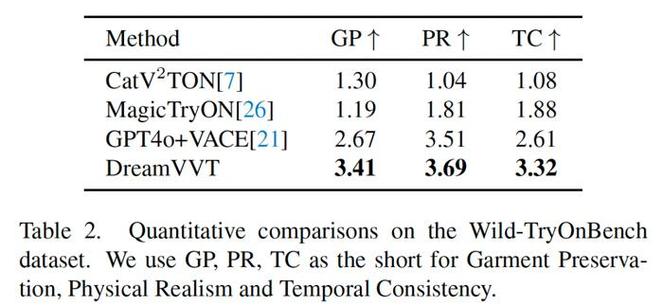
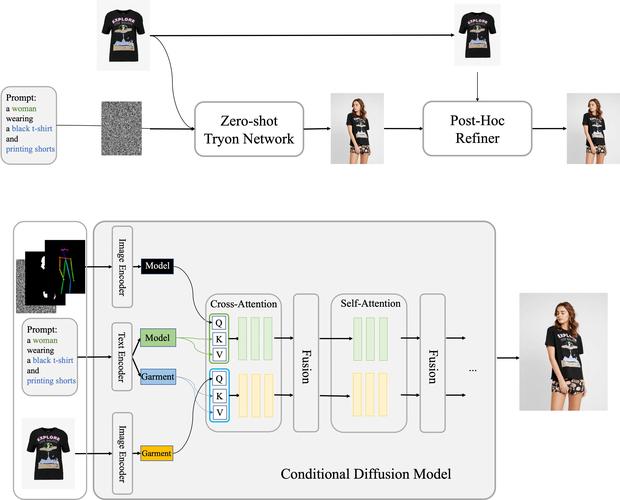
DreamVVT – 字节联合清华推出的视频虚拟试穿技术
DreamVVT 是字节跳动和清华大学(深圳)联合推出的视频虚拟试穿(Video Virtual Try-On, VVT)技术,基于扩散 Transformer(DiTs)框架,通过两阶段方法实现高保真且时间连贯的虚拟试穿效...
-
发布了文章 2个月前
DreamO – 字节联合北大推出的图像定制生成框架
DreamO 是字节跳动创作团队联合北京大学深圳研究生院电子与计算机工程学院联合推出的用在图像定制生成的统一框架,基于预训练的扩散变换器(DiT)模型实现多种图像生成任务的灵活定制。...
-
发布了文章 2个月前
DreamFit – 字节联合清华和中山大学推出的虚拟试衣框架
DreamFit是字节跳动团队联合清华大学深圳国际研究生院、中山大学深圳校区推出的虚拟试衣框架,专门用在轻量级服装为中心的人类图像生成。基于自适应注意力和LoRA模块,将模型复杂性降低至83.4M可训练参数,显著提高训练效率...








没有更多内容