阿里 tob
-
发布了文章 1个月前
阿里推最新通义千问QwQ-32B推理模型
2025年3月6日,阿里巴巴正式发布并开源全新推理模型——通义千问QwQ-32B。该模型拥有320亿参数,性能卓越,据称可与拥有6710亿参数的DeepSeek-R1相媲美。通义千问QwQ-32B基于Qwen2.5-MAX深...
-
发布了文章 2个月前
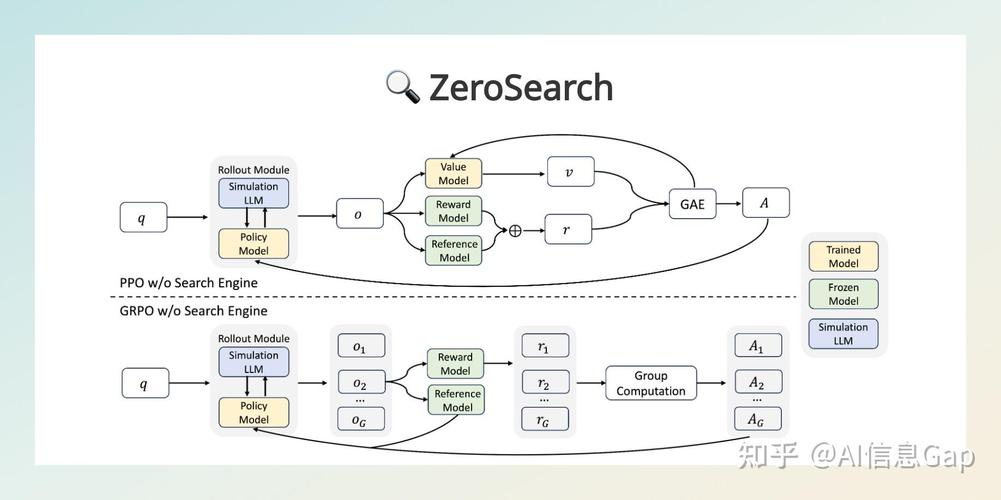
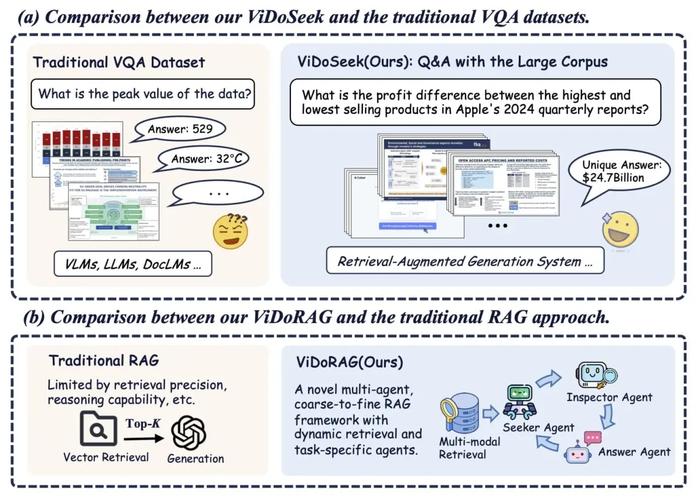
ZeroSearch – 阿里通义开源的大模型搜索引擎框架
ZeroSearch 是阿里巴巴通义实验室开源的创新大模型搜索引擎框架,基于强化学习激励大模型的搜索能力,无需与真实搜索引擎交互。框架爱基于大模型预训练知识,转化为检索模块,根据查询生成相关或噪声文档,动态控制生成质量。...
-
发布了文章 2个月前
WebShaper – 阿里通义推出的AI训练数据合成系统
WebShaper 是阿里巴巴通义实验室推出的创新的 AI 训练数据合成系统。通过形式化建模和智能体扩展机制,为 AI 智能体(Agent)的训练提供了高质量、可扩展的数据。WebShaper 首次引入了基于集合论的“知识投...
-
发布了文章 2个月前
VACE – 阿里通义推出的视频生成与编辑框架
VACE(Video Creation and Editing)是阿里巴巴通义实验室推出的一站式视频生成与编辑框架。基于整合多种视频任务(如参考视频生成、视频到视频编辑、遮罩编辑等)到一个统一模型中,实现高效的内容创作和编辑...
-
发布了文章 2个月前
Tora – 阿里推出的AI视频生成框架
Tora是阿里推出的AI视频生成框架,基于轨迹导向的扩散变换器(DiT)技术,将文本、视觉和轨迹条件融合,生成高质量且符合物理世界动态的视频内容。Tora由轨迹提取器、时空DiT和运动引导融合器组成,能够精确控制视频的动态表...
-
发布了文章 2个月前
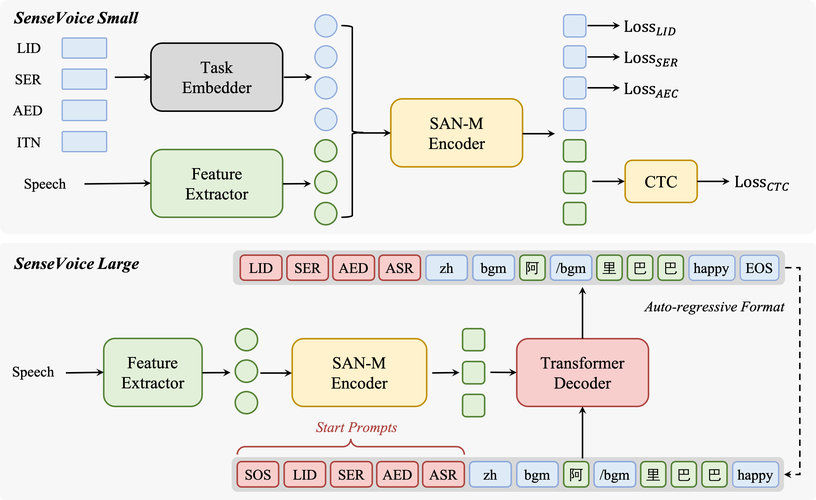
ThinkSound – 阿里通义推出的首个CoT音频生成模型
ThinkSound是阿里通义语音团队推出的首个CoT(链式思考)音频生成模型,用在视频配音,为每一帧画面生成专属匹配音效。模型引入CoT推理,解决传统技术难以捕捉画面动态细节和空间关系的问题,让AI像专业音效师一样逐步思考...
-
发布了文章 2个月前
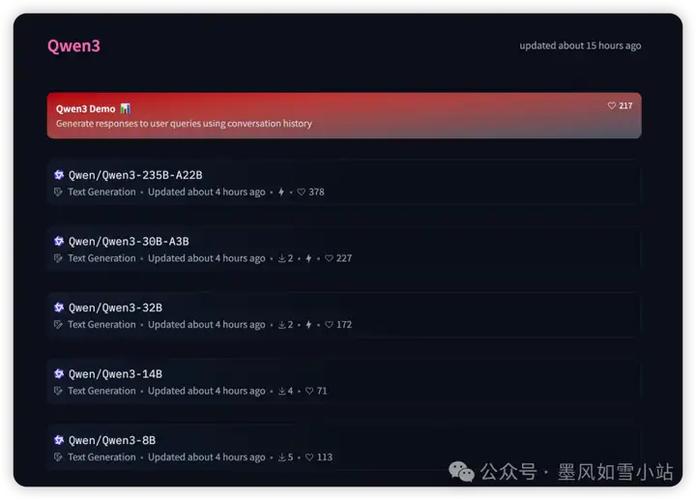
Qwen3 – 阿里通义开源的新一代混合推理模型系列
Qwen3 是阿里巴巴推出的新一代大型语言模型,Qwen3 支持“思考模式”和“非思考模式”两种工作方式,思考模式模型会逐步推理,经过深思熟虑后给出最终答案,适合复杂问题。非思考模式模型提供快速、近乎即时的响应,适用于简单问...
-
发布了文章 2个月前
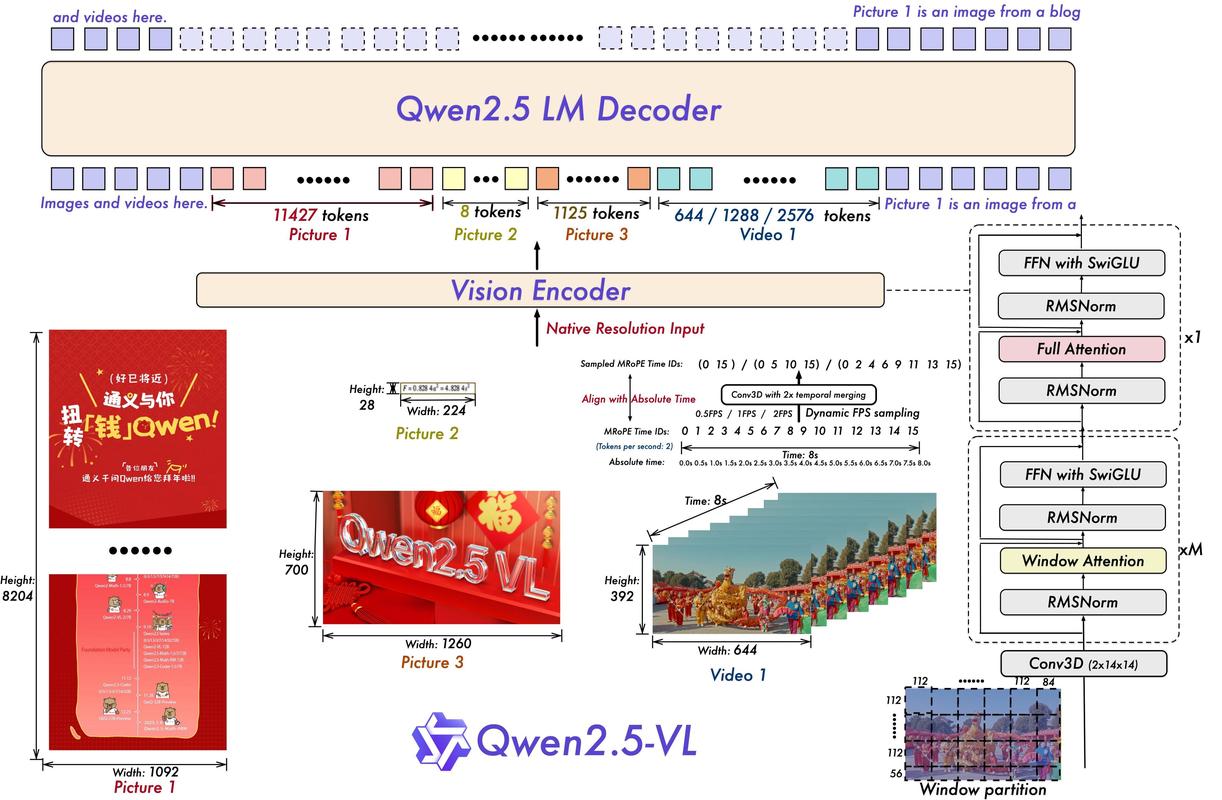
Qwen2.5 – 阿里通义千问团队最新开源的最强AI大模型
Qwen2.5 是阿里通义千问团队最新开源的最强AI大模型,具有多种参数规模的模型,包括 0.5B、1.5B、3B、7B、14B、32B 和 72B。模型在预训练时使用了最新的大规模数据集,包含多达 18 万亿个 token...
-
发布了文章 2个月前
OmniSearch – 阿里通义推出的多模态检索增强生成框架
OmniSearch是阿里巴巴通义实验室推出的多模态检索增强生成框架,具备自适应规划能力。OmniSearch能动态拆解复杂问题,根据检索结果和问题情境调整检索策略,模拟人类解决复杂问题的行为,提升检索效率和准确性。Omni...
-
发布了文章 2个月前
MaskSearch – 阿里通义推出的检索增强预训练框架
MaskSearch是阿里巴巴通义实验室推出的新型通用预训练框架,提升大型语言模型(LLM)的智能体搜索能力。通过检索增强掩码预测(RAMP)任务,让模型在输入文本中对关键信息掩码。...
-
发布了文章 2个月前
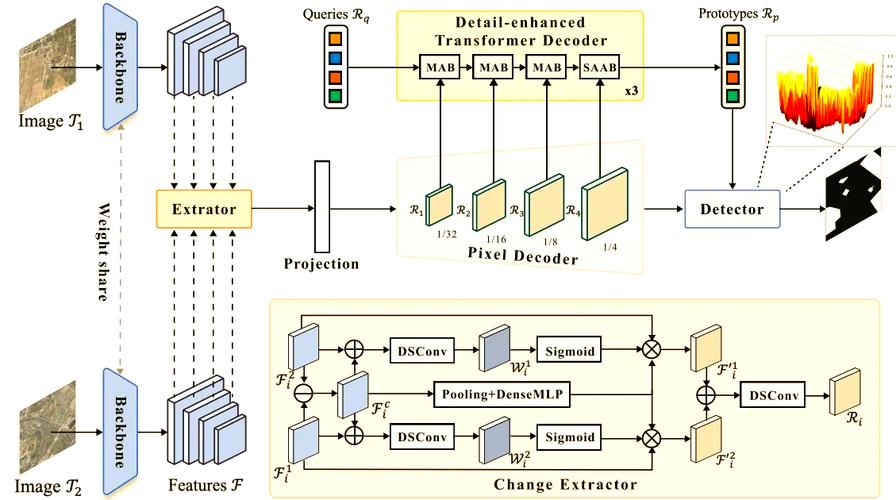
LLMDet – 阿里通义联合中山大学等机构推出的开放词汇目标检测模型
LLMDet是阿里巴巴集团通义实验室、中山大学计算机科学与工程学院、鹏城实验室等机构推出的开放词汇目标检测器,基于与大型语言模型(LLM)协同训练提升目标检测性能。LLMDet能收集包含图像、定位标签和详细图像级描述的数据集...
-
发布了文章 2个月前
HumanOmniV2 – 阿里通义开源的多模态推理模型
HumanOmniV2 是阿里通义实验室开源的多模态推理模型。模型基于强制上下文总结机制、大模型驱动的多维度奖励体系及基于 GRPO 的优化训练方法,解决多模态推理中全局上下文理解不足和推理路径简单的问题。...
-
发布了文章 2个月前
HumanOmni – 阿里通义等推出专注人类中心场景的多模态大模型
HumanOmni 是专注于人类中心场景的多模态大模型,视觉和听觉模态融合而成。通过处理视频、音频或两者的结合输入,能全面理解人类行为、情感和交互。模型基于超过240万视频片段和1400万条指令进行预训练,采用动态权重调整机...
-
发布了文章 2个月前
DiffuEraser – 阿里通义实验室推出的视频修复模型
DiffuEraser是基于稳定扩散模型的视频修复模型,以更丰富的细节和更连贯的结构填充视频中的遮罩区域。模型通过结合先验信息来提供初始化和弱条件,有助于减少噪声伪影和抑制幻觉。为了在长序列推理期间提高时间一致性,Diffu...
-
发布了文章 2个月前
ChatAnyone – 阿里通义推出的实时风格化肖像视频生成框架
ChatAnyone是阿里巴巴通义实验室推出的实时风格化肖像视频生成框架。通过音频输入,生成具有丰富表情和上半身动作的肖像视频。采用高效分层运动扩散模型和混合控制融合生成模型,能实现高保真度和自然度的视频生成,支持实时交互,...