

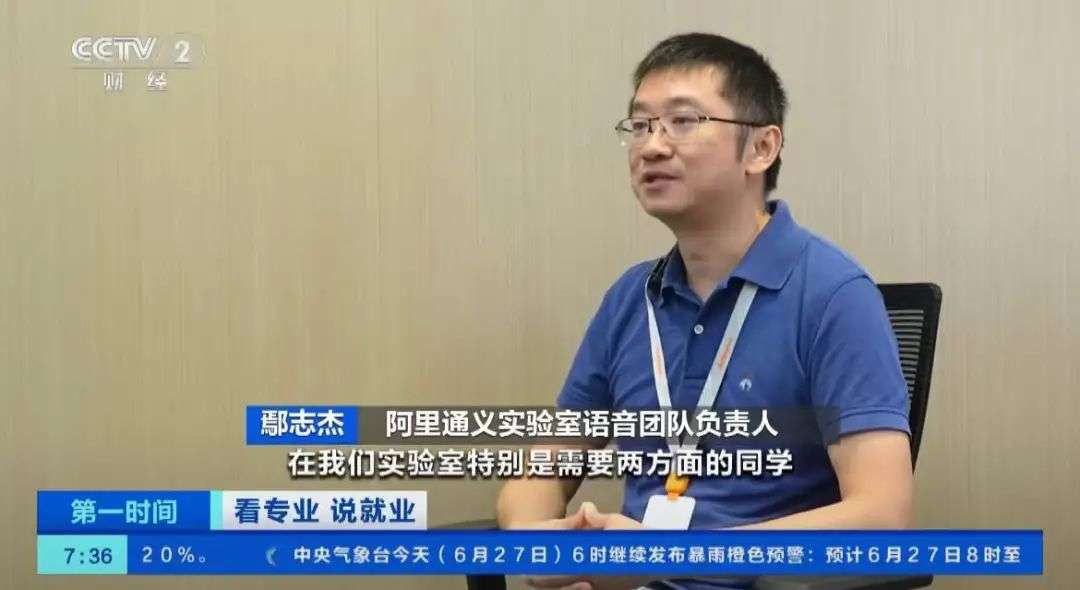
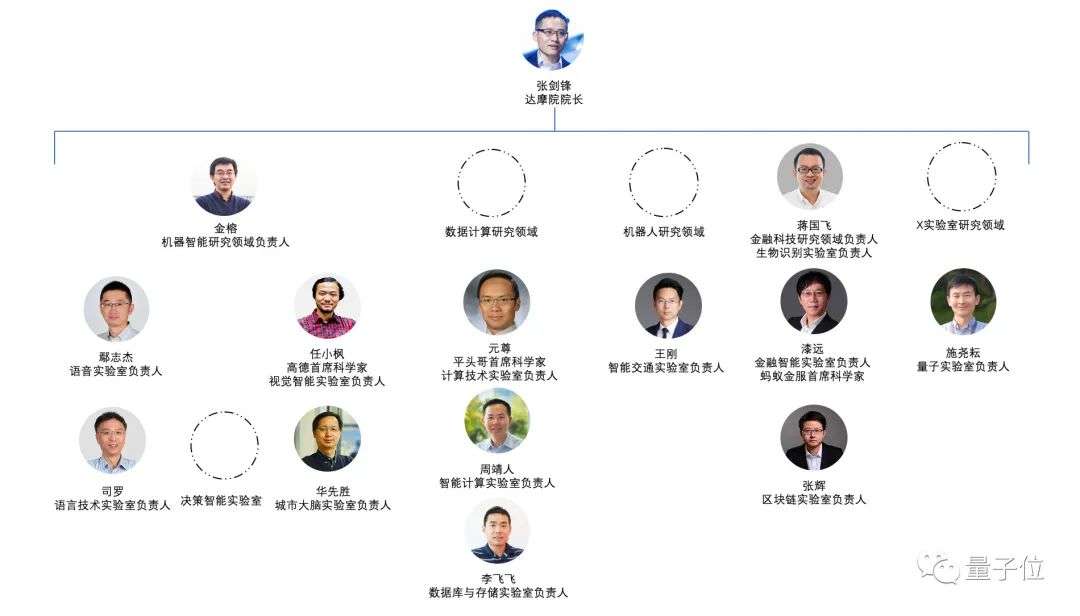
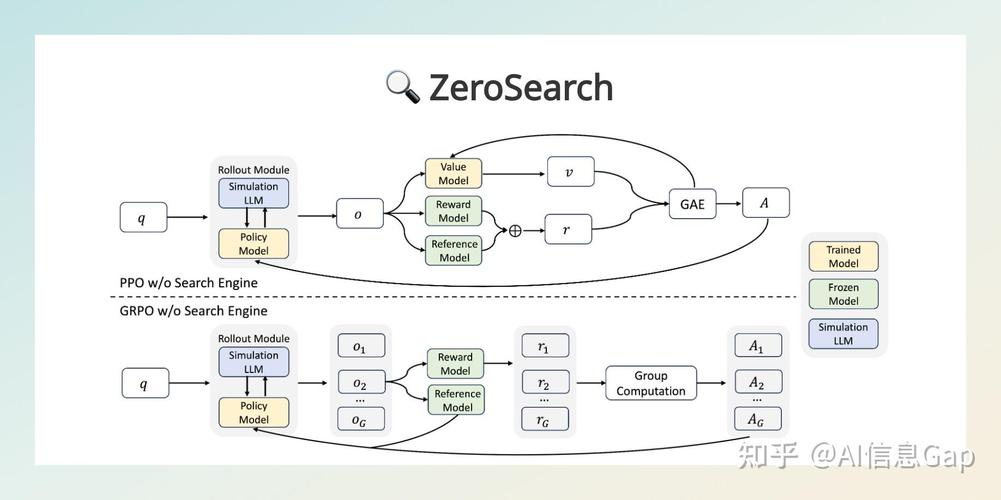
ThinkSound是阿里通义语音团队推出的首个CoT(链式思考)音频生成模型,用在视频配音,为每一帧画面生成专属匹配音效。模型引入CoT推理,解决传统技术难以捕捉画面动态细节和空间关系的问题,让AI像专业音效师一样逐步思考,生成音画同步的高保真音频。模型基于三阶思维链驱动音频生成,包括基础音效推理、对象级交互和指令编辑。模型配备AudioCoT数据集,包含带思维链标注的音频数据。在VGGSound数据集上,ThinkSound超越6种主流方法(Seeing&Hearing、V-AURA、FoleyCrafter、Frieren、V2A-Mapper和MMAudio),展现出卓越的性能。

(图片来源网络,侵删)






全部评论
留言在赶来的路上...
发表评论