

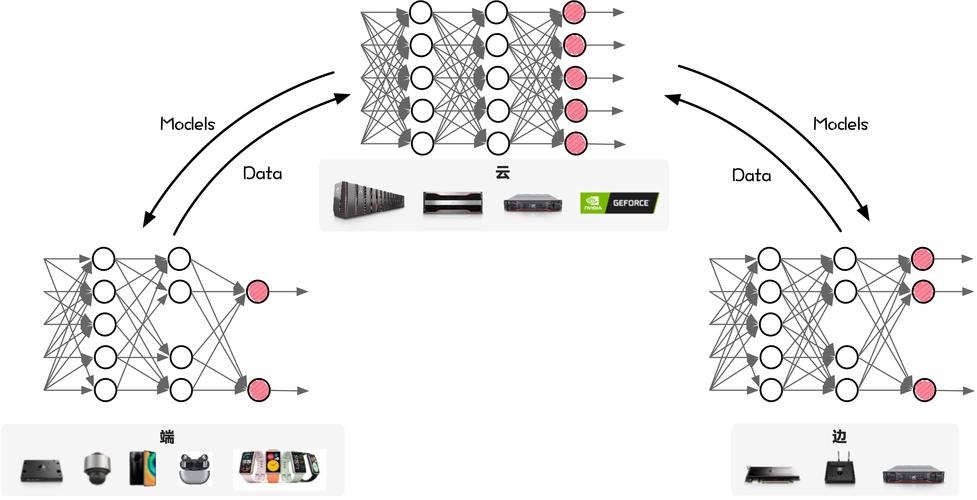
VideoRefer是浙江大学和阿里达摩学院联合推出的,专门用在视频中对象的感知和推理。基于增强视频大型语言模型(Video LLMs)的空间-时间理解能力,让模型能在视频中对任何对象进行细粒度的感知和推理。VideoRefer基于三个核心组件实现:VideoRefer-700K数据集,提供大规模、高质量的对象级视频指令数据;VideoRefer模型,配备多功能空间-时间对象编码器,支持单帧和多帧输入,实现对视频中任意对象的精确感知、推理和检索;VideoRefer-Bench基准,用在全面评估模型在视频指代任务中的性能,推动细粒度视频理解技术的发展。

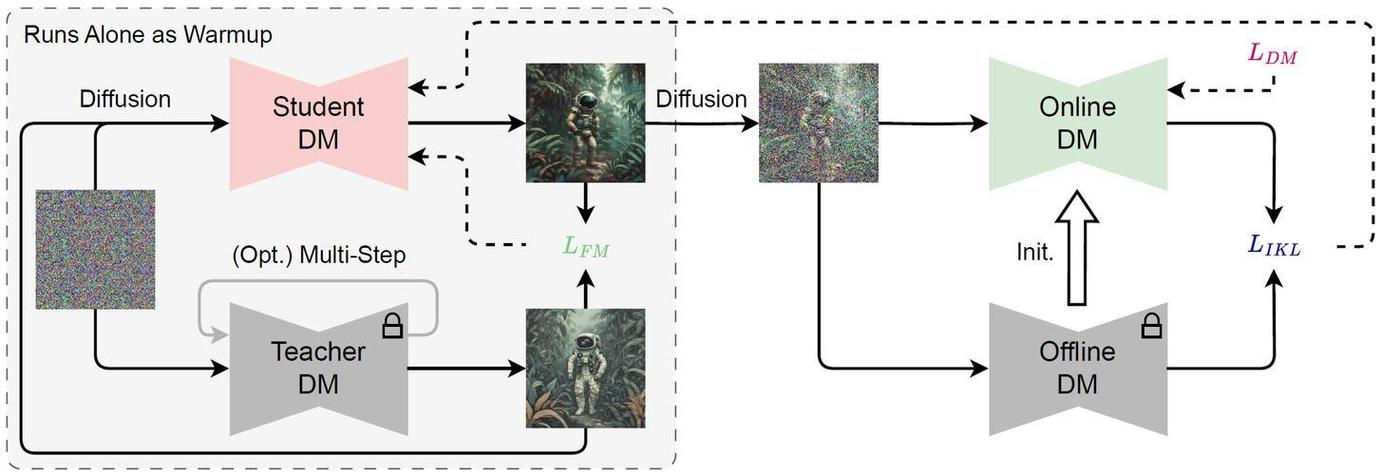
(图片来源网络,侵删)

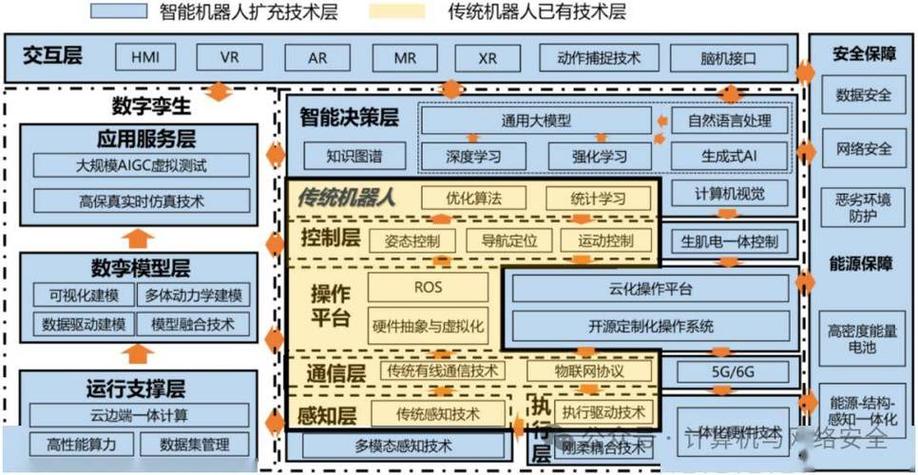
(图片来源网络,侵删)







全部评论
留言在赶来的路上...
发表评论