

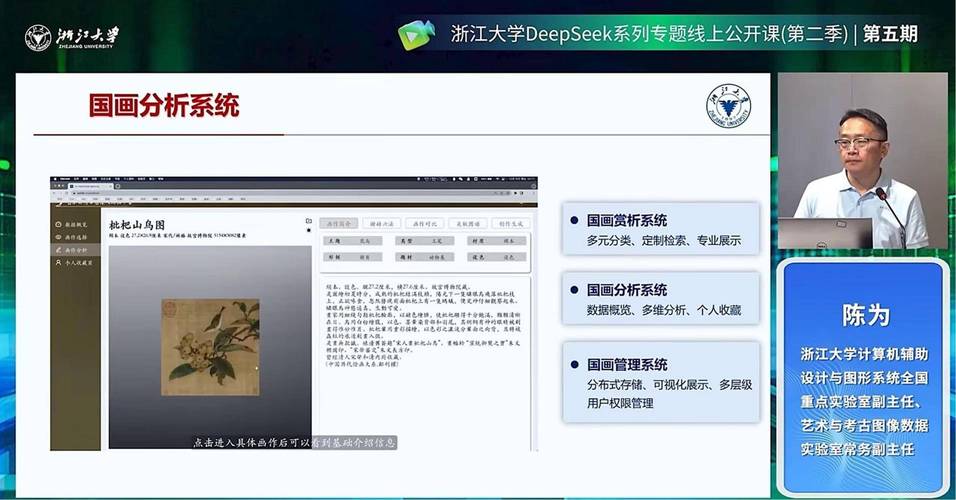
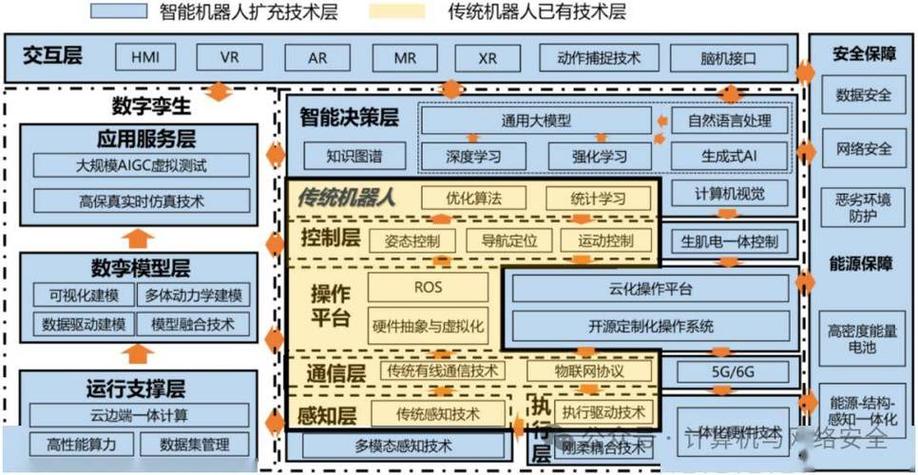
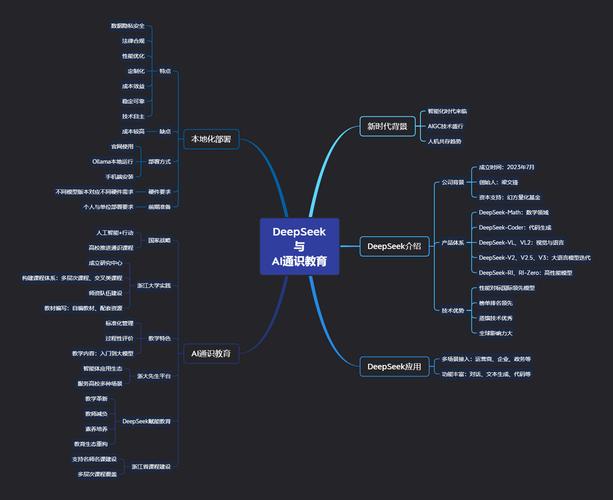
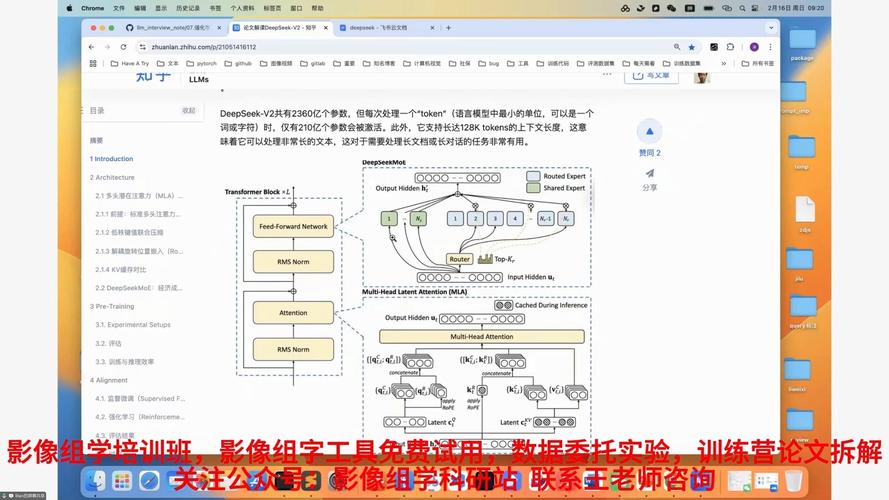
uiuc浙大联合学院
-
发布了文章 2个月前
VideoRefer – 浙大联合阿里达摩学院推出的视频对象感知与推理技术
VideoRefer是浙江大学和阿里达摩学院联合推出的,专门用在视频中对象的感知和推理。基于增强视频大型语言模型(Video LLMs)的空间-时间理解能力,让模型能在视频中对任何对象进行细粒度的感知和推理。...
-
发布了文章 2个月前
ReCamMaster – 浙大联合快手等推出的视频重渲染框架
ReCamMaster 是浙江大学、快手科技等联合推出的视频重渲染框架,能根据新的相机轨迹重新生成视频内容。通过预训练模型和帧维度条件机制,结合多相机同步数据集和相机姿态条件,实现视频视角、运动轨迹的灵活调整。...

-
发布了文章 2个月前
OmniThink – 浙大联合阿里通义实验室推出的深度思考机器写作框架
OmniThink是浙江大学和阿里巴巴通义实验室联合开发的创新的机器写作框架,通过模拟人类的迭代扩展和反思过程,突破大型语言模型在机器写作中的知识边界。框架通过信息树和概念池的结构化组织,逐步深化对主题的理解,生成高质量的长...
-
发布了文章 2个月前
OmniCam – 浙大联合上海交大等高校推出的多模态视频生成框架
OmniCam 是先进的多模态视频生成框架,通过摄像机控制实现高质量的视频生成。支持多种输入模态组合,用户可以提供文本描述、视频中的轨迹或图像作为参考,精确控制摄像机的运动轨迹。...
-
发布了文章 2个月前
MagicTryOn – 浙大联合vivo等机构推出的视频虚拟试穿框架
MagicTryOn是浙江大学计算机科学与技术学院、vivo移动通信等机构推出的基于视频扩散Transformer的视频虚拟试穿框架。框架替换传统的U-Net架构为更具表现力的扩散Transformer(DiT),结合全自注...
-
发布了文章 2个月前
LanDiff – 浙大联合月之暗面推出的文本到视频生成混合框架
LanDiff是用于高质量的文本到视频(T2V)生成的创新混合框架,结合了自回归语言模型(LLM)和扩散模型(Diffusion Model)的优势,通过粗到细的生成方式,有效克服了单一方法在语义理解和视觉质量上的局限性。...
-
发布了文章 2个月前
InftyThink – 浙大联合北大推出的无限深度推理范式
InftyThink是创新的大模型推理范式,突破传统模型在长推理任务中的局限性。通过分段迭代的方式,将复杂的推理过程分解为多个短片段,在每个片段后生成中间总结,实现分块式思考。...
-
发布了文章 2个月前
HumanDiT – 浙大联合字节推出的姿态引导人体视频生成框架
HumanDiT 是浙江大学和字节跳动联合提出的姿态引导的高保真人体视频生成框架。基于扩散变换器(Diffusion Transformer,DiT),能在大规模数据集上训练,生成具有精细身体渲染的长序列人体运动视频。...





没有更多内容