

浙江大学zjuuiuc联合学院
-
发布了文章 2个月前
VideoRefer – 浙大联合阿里达摩学院推出的视频对象感知与推理技术
VideoRefer是浙江大学和阿里达摩学院联合推出的,专门用在视频中对象的感知和推理。基于增强视频大型语言模型(Video LLMs)的空间-时间理解能力,让模型能在视频中对任何对象进行细粒度的感知和推理。...
-
发布了文章 2个月前
VideoMaker – 浙大联合腾讯和华为推出的零样本定制视频生成框架
VideoMaker是浙江大学、腾讯和华为诺亚方舟实验室共同开发的创新项目,基于视频扩散模型(VDM)的零样本定制视频生成框架。与传统方法不同,VideoMaker无需额外模型即可直接从参考图片中提取和注入主题特征,实现个性...
-
发布了文章 2个月前
Prometheus – 浙大联合蚂蚁等高校推出的3D感知潜在扩散模型
Prometheus是创新的3D感知潜在扩散模型,专门用于快速生成文本到3D场景的内容。能在几秒钟内完成对象和场景级别的3D生成,同时保持高质量的输出和良好的泛化能力。核心在于基于2D先验知识来驱动高效且可泛化的3D合成过程...
-
发布了文章 2个月前
OmniThink – 浙大联合阿里通义实验室推出的深度思考机器写作框架
OmniThink是浙江大学和阿里巴巴通义实验室联合开发的创新的机器写作框架,通过模拟人类的迭代扩展和反思过程,突破大型语言模型在机器写作中的知识边界。框架通过信息树和概念池的结构化组织,逐步深化对主题的理解,生成高质量的长...
-
发布了文章 2个月前
OmniCam – 浙大联合上海交大等高校推出的多模态视频生成框架
OmniCam 是先进的多模态视频生成框架,通过摄像机控制实现高质量的视频生成。支持多种输入模态组合,用户可以提供文本描述、视频中的轨迹或图像作为参考,精确控制摄像机的运动轨迹。...
-
发布了文章 2个月前
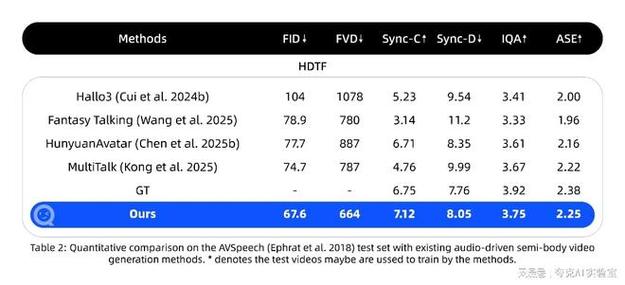
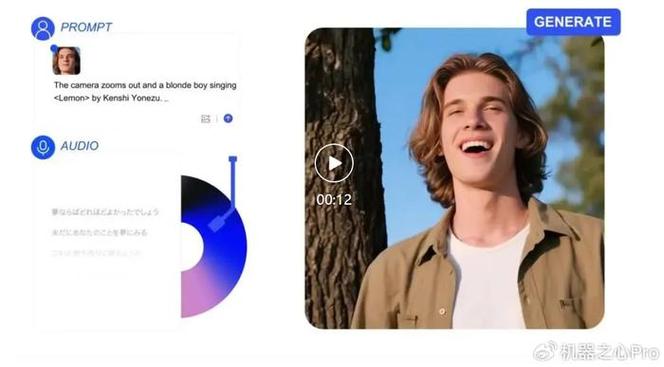
OmniAvatar – 浙大联合阿里推出的音频驱动全身视频生成模型
OmniAvatar是浙江大学和阿里巴巴集团共同推出的音频驱动全身视频生成模型。模型根据输入的音频和文本提示,生成自然、逼真的全身动画视频,人物动作与音频完美同步,表情丰富。...
-
发布了文章 2个月前
MagicTryOn – 浙大联合vivo等机构推出的视频虚拟试穿框架
MagicTryOn是浙江大学计算机科学与技术学院、vivo移动通信等机构推出的基于视频扩散Transformer的视频虚拟试穿框架。框架替换传统的U-Net架构为更具表现力的扩散Transformer(DiT),结合全自注...
-
发布了文章 2个月前
LanDiff – 浙大联合月之暗面推出的文本到视频生成混合框架
LanDiff是用于高质量的文本到视频(T2V)生成的创新混合框架,结合了自回归语言模型(LLM)和扩散模型(Diffusion Model)的优势,通过粗到细的生成方式,有效克服了单一方法在语义理解和视觉质量上的局限性。...
-
发布了文章 2个月前
AnimateAnything – 浙江大学联合北航推出的统一可控视频生成技术
AnimateAnything是浙江大学和北京航空航天大学研究者推出的统一可控视频生成技术。AnimateAnything能精确操作视频,包括控制相机轨迹、文本提示和用户动作注释。基于多尺度控制特征融合网络,该技术将控制信息...









没有更多内容