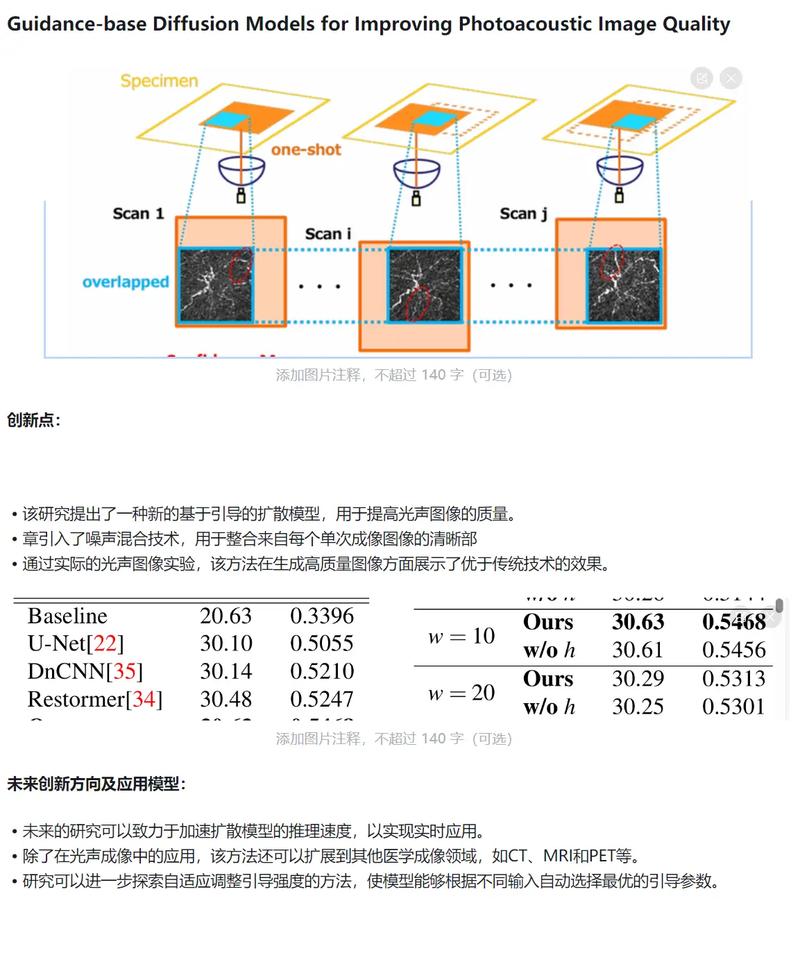
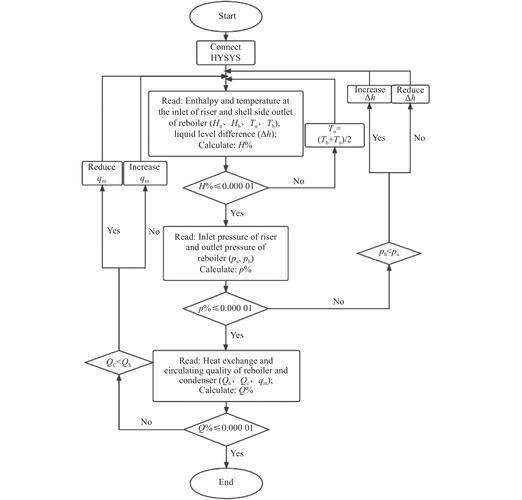
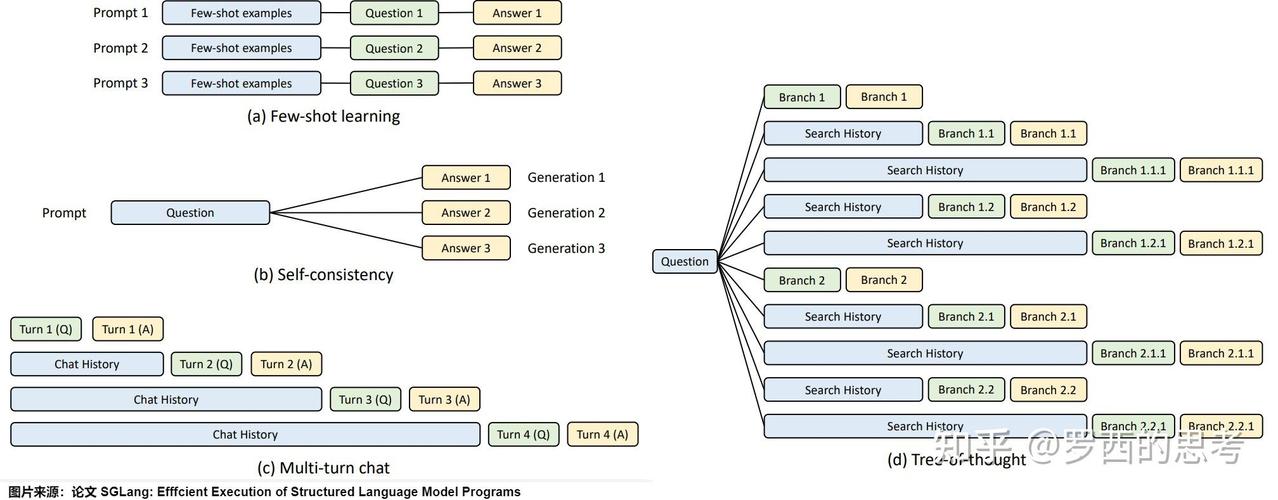
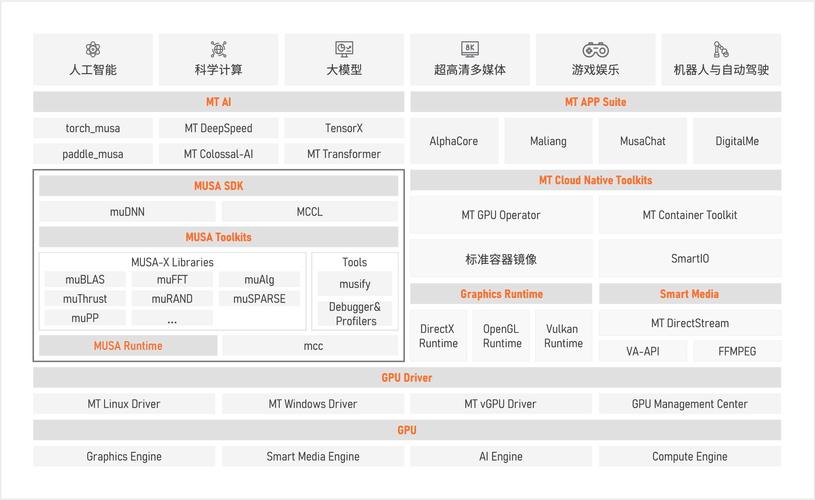
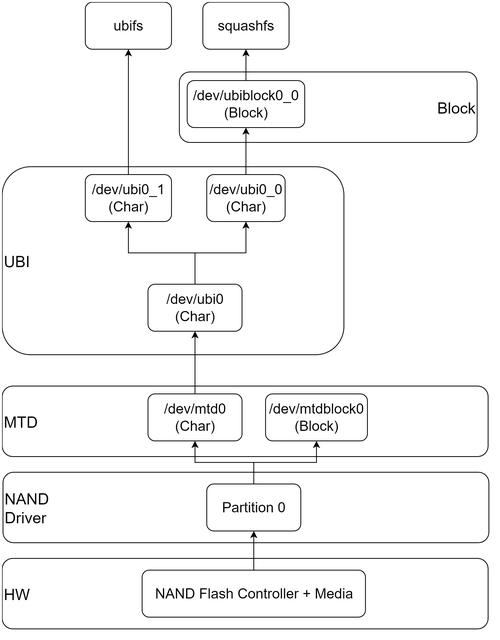
AI工具
发布文章-
发布了文章 2个月前
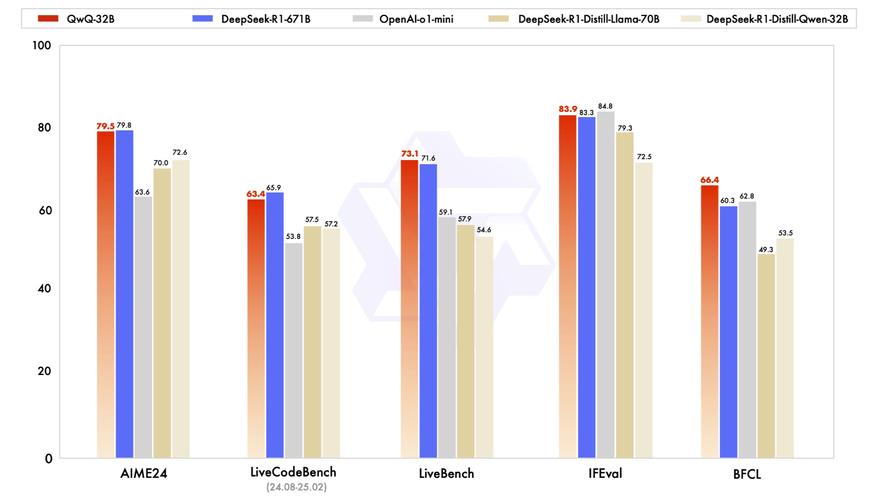
MVoT – 微软联合剑桥和中科院推出的多模态推理可视化框架
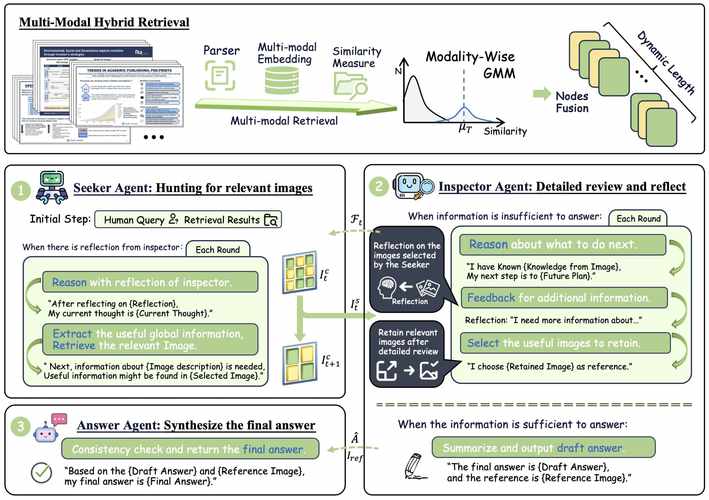
MVoT(Multimodal Visualization-of-Thought)是微软研究院、剑桥大学语言技术实验室、中国科学院自动化研究所推出的新型多模态推理范式,基于生成图像可视化推理痕迹增强多模态大语言模型(MLLM...
-
发布了文章 2个月前
MVPaint – 腾讯PCG联合多所高校共同推出的3D纹理生成框架
MVPaint是腾讯PCG 、上海AI LAB、南洋理工大学S-Lab、清华大学共同推出的3D纹理生成框架,基于同步多视角扩散技术实现高分辨率、无缝且多视图一致的3D纹理生成。MVPaint包含三个核心模块:同步多视角生成(...
-
发布了文章 2个月前
MVGenMaster – 复旦联合阿里等实验室推出的多视图扩散模型
MVGenMaster是复旦大学、阿里巴巴达摩院和湖潘实验室共同推出的多视图扩散模型,基于增强3D先验处理多样化的新视角合成(NVS)任务。模型基于度量深度和相机姿态扭曲的3D先验,提升NVS的泛化和3D一致性。...
-
发布了文章 2个月前
MVDrag3D – 南洋理工大学推出的拖拽式多视图3D编辑技术
MVDrag3D是创新的3D编辑框架,结合多视图生成和重建先验实现灵活且富有创造性的拖拽编辑。框架用多视图扩散模型作为生成先验,确保在多个渲染视图间进行一致的拖拽编辑,基于重建模型重建编辑对象的3D高斯表示,用视图特定的变形...
-
发布了文章 2个月前
MV-baidu09MATH – 中科院推出的基准数据集,评估模型处理多视觉信息的数学推理能力
MV-MATH 是中科院自动化所提出的新基准数据集,评估多模态大语言模型(MLLMs)在多视觉场景中的数学推理能力。数据集包含2009个高质量的数学问题,每个问题都结合了多个图像和文本,形成了图文交错的多视觉场景。...
-
发布了文章 2个月前
MV-baidu09Adapter – 北航联合 VAST 等开源的多视图一致图像生成模型
MV-Adapter是多视图一致图像生成模型,是北京航空航天大学、VAST和上海交通大学的研究团队推出的。MV-Adapter能将预训练的文本到图像扩散模型转化为多视图图像生成器,无需改变原始网络结构或特征空间。...
-
发布了文章 2个月前
MUMU – 文本和图像驱动的多模态生成模型
MUMU是一种多模态图像生成模型,通过结合文本提示和参考图像来生成目标图像,从而提高生成的准确率和质量。MUMU模型的架构基于SDXL的预训练卷积UNet,采用了视觉语言模型Idefics2的隐藏状态构建。...
-
发布了文章 2个月前
MTVCrafter – 中科院联合中国电信等机构推出的人像动画生成框架
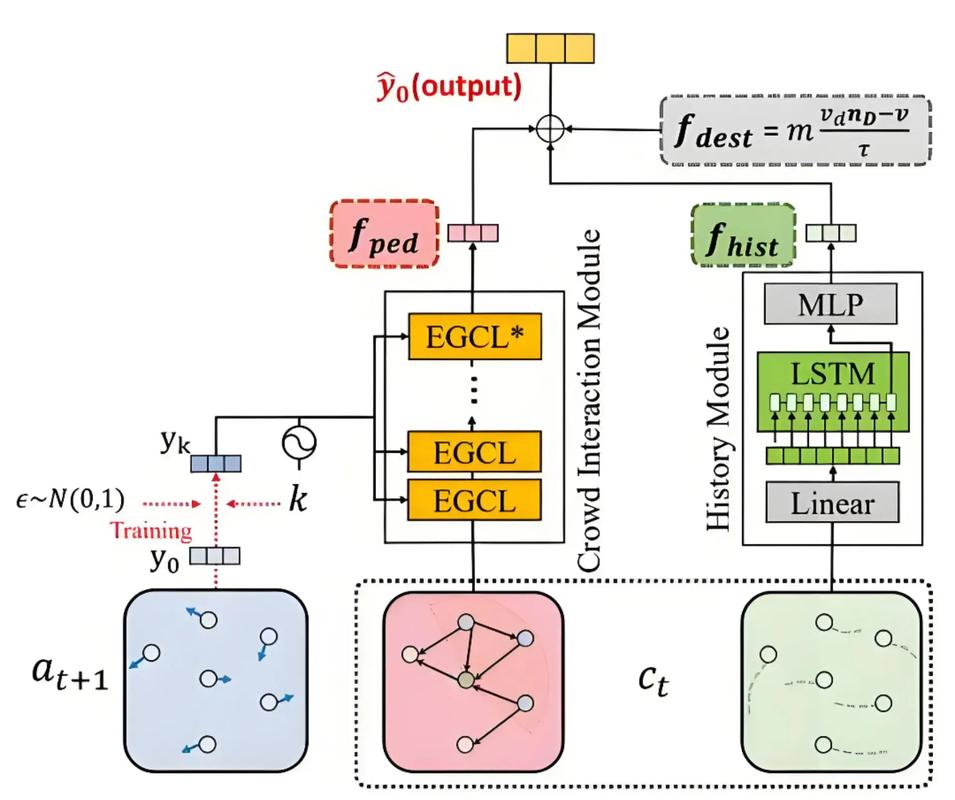
MTVCrafter是中国科学院深圳先进技术研究院计算机视觉与模式识别实验室、中国电信人工智能研究所等机构推出的新型人类图像动画框架,基于原始3D运动序列进行高质量动画生成。框架基于4D运动标记化(4DMoT)直接对3D运动...
-
发布了文章 2个月前
MT-baidu09TransformerEngine – 摩尔线程开源的高效训练与推理优化框架
MT-TransformerEngine 是摩尔线程开源的高效训练与推理优化框架,专为 Transformer 模型设计。框架通过算子融合、并行加速等技术,充分基于摩尔线程全功能 GPU 的计算潜力,显著提升训练效率。...
-
发布了文章 2个月前
MT-baidu09MegatronLM – 摩尔线程开源的混合并行训练框架
MT-MegatronLM 是摩尔线程推出的面向全功能 GPU 的开源混合并行训练框架,主要用于高效训练大规模语言模型。支持 dense 模型、多模态模型及 MoE(混合专家)模型的训练。框架基于全功能 GPU 支持 FP8...
-
发布了文章 2个月前
MT-baidu09Color – 上海交大联合哔哩哔哩推出的可控图像着色框架
MT-Color是上海交通大学联合哔哩哔哩推出的基于扩散模型的可控图像着色框架,基于用户提供的实例感知文本和掩码实现精确的实例级图像着色。框架基于像素级掩码注意力机制防止色彩溢出,用实例掩码和文本引导模块解决色彩绑定错误问题...
-
发布了文章 2个月前
MSQA – 大规模多模态3D情境推理数据集
MSQA(Multi-modal Situated Question Answering)是大规模多模态情境推理数据集,提升具身AI代理在3D场景中的理解与推理能力。数据集包含251K个问答对,覆盖9个问题类别,基于3D场景...
-
发布了文章 2个月前
MOSS-baidu09TTSD – 清华实验室开源的口语对话语音生成模型
MOSS-TTSD(Text to Spoken Dialogue)是开源的口语对话语音生成模型,由清华大学语音与语言实验室(Tencent AI Lab)开发。能将文本对话脚本转化为自然流畅、富有表现力的对话语音,支持中英...
-
发布了文章 2个月前
MOFA-baidu09Video – 腾讯开源的可控性AI图生视频模型
MOFA-Video是由腾讯AI实验室和东京大学的研究人员开源的一个可控性的图像生成视频的模型,该技术利用生成运动场适应器对图像进行动画处理以生成视频。...
-
发布了文章 2个月前
MNN – 阿里开源的移动端深度学习推理框架
MNN(Mobile Neural Network)是阿里巴巴集团开源的轻量级深度学习推理框架,为移动端、服务器、个人电脑、嵌入式设备等多种设备提供高效的模型部署能力。MNN支持TensorFlow、Caffe、ONNX等主...