

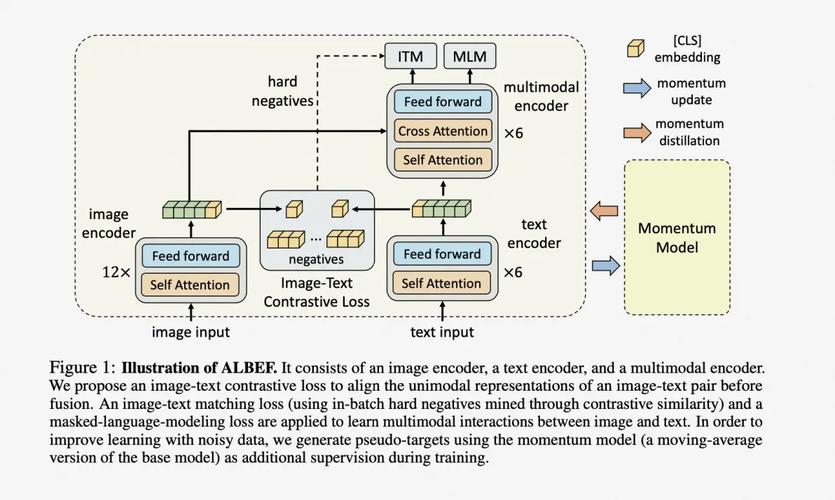
MVoT(Multimodal Visualization-of-Thought)是微软研究院、剑桥大学语言技术实验室、中国科学院自动化研究所推出的新型多模态推理范式,基于生成图像可视化推理痕迹增强多模态大语言模型(MLLMs)在复杂空间推理任务中的表现。MVoT模仿人类在思考时同时使用语言和图像的机制,让模型在推理过程中生成文字和图像的交错推理痕迹,更直观地表达推理过程。MVoT基于引入token discrepancy loss解决自回归MLLMs中语言和视觉嵌入空间之间的不一致性问题,显著提高生成图像的质量和推理的准确性。

(图片来源网络,侵删)

(图片来源网络,侵删)




全部评论
留言在赶来的路上...
发表评论