

拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。AI生成的测试用例真的靠谱吗?机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。AI生成的测试用例真的靠谱吗?资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
软件测试正经历一场深刻的技术革命。,尤其是以GPT、通义千问、文心一言、Claude等为代表的大语言模型(LLM),开始广泛介入测试流程:从需求分析、测试用例设计,到脚本生成与测试报告撰写,AI的身影无处不在。
尤其在测试用例生成这一传统上高度依赖人工经验的环节,AI展现出令人惊艳的能力——快速、高效、“看起来很专业”。于是,很多测试团队纷纷尝试用AI生成用例,以为找到了银弹。

但问题随之而来:
这是一个不只是技术问题,更是认知与方法论问题。

本文将以技术专业视角深入剖析:AI生成测试用例的优势与陷阱、信任边界与治理方法,并提供可落地的实战建议。
01
AI生成测试用例的底层逻辑:
不是“聪明”,而是“预测”
要理解AI生成测试用例的本质,我们首先要揭开它的“黑盒”面纱。
以大语言模型为例,它是基于海量数据训练出的概率语言模型,本质上是:
给定上下文,预测下一个最可能的“token”。
当我们向AI输入“请根据以下功能说明生成测试用例”,它做的并不是理解功能并设计测试策略,而是:
根据训练中见过的相似描述,预测出最常见的测试用例模式;
用自然语言组织这些模式,使其看起来“像个人写的”。
这意味着,AI生成的测试用例,其质量很大程度上取决于:
模型训练中是否见过类似场景;
提示词(prompt)是否准确引导;
输出是否被专业人员审校。
它没有真正理解系统、也无法从业务优先级、系统风险等多维度进行“测试建模”——除非你显式地告诉它怎么做。
所以,AI生成测试用例并不等于自动化测试建模。
02
AI生成用例的价值:
效率极高,启发性强,但“有限”
我们先正视AI生成用例的价值:
优势一:快速起草,节省设计时间
在时间紧、需求初期、测试用例空白的情况下,AI能迅速生成结构化用例,为测试设计打下基础。
优势二:语言组织优秀,适合文档交付
AI生成的用例语言规范,结构清晰,特别适合用作测试文档初稿、交付材料草稿。
优势三:适合边界值、等价类等基本策略的通用场景
对于逻辑清晰、边界明确的业务,AI可以基于经验样本生成较为全面的等价类测试用例。
优势四:对初级测试人员有“训练作用”
通过对比AI用例和人工用例,初学者可以理解不同用例类型的设计方式,提高测试思维。
03
AI生成用例的问题:
看似合理,实则“无感”业务风险
但AI生成用例也有令人警惕的局限:
问题一:无法准确识别业务重点与高风险场景
AI“平均对待”每一个需求点,却无法识别:
哪些是业务高价值场景(如资金流转、合规风控);
哪些是安全敏感路径;
哪些场景具备高复杂度的状态依赖。
这就导致AI生成的用例覆盖面广但不深、平均但不精准。
问题二:容易忽略边界与异常场景组合
AI生成的边界值往往比较基础(如密码最短6位、号为空等),却难以深入如:
边界+状态依赖的复杂路径(如“密码过期+验证码失效”);
复杂的异常组合(如“token刷新失败+订单并发提交”);
非功能性测试(如性能、兼容性、安全)需求。
问题三:存在语义模糊和业务错误
AI输出的用例经常会出现:
不存在的字段(如用户注册中引用“昵称”字段);
错误的系统行为(如错误输入仍提示成功);
模糊描述(如“检查系统是否正常”)。
这类问题一旦“看起来合理”,就会被不加验证地纳入测试计划,造成测试偏差甚至放过缺陷。
问题四:缺乏与实际系统环境的契合性
AI无法感知以下关键内容:
系统真实返回值、字段名;
第三方依赖、接口调用顺序;
UI元素的具体路径与层级;
动态配置、A/B实验、国际化等运行时差异。
所以,AI生成的测试用例常常只能作为“纸上谈兵”。
04
那我们能信多深?
—分层信任模型
我们可以从以下几个层级,来构建“对AI生成测试用例的信任策略”:
Level 1:参考启发层
用途:用于项目启动、初期需求分析阶段,快速生成测试框架与用例结构草图。
信任方式:辅助人类思考,不直接执行。
Level 2:模板生成层
用途:用于标准化接口、固定业务场景下的通用用例生成。
信任方式:结合模板规则生成,用作“半自动化草稿”。
Level 3:辅助增强层
用途:在已有用例体系中,使用AI扩展边界用例、组合路径、数据多样性等。
信任方式:人机协同设计,由人审查、AI拓展。
Level 4:自动执行层(需谨慎)
用途:直接将AI生成的测试脚本投入执行。
信任方式:必须人工审校、验证数据、回归验证。否则可能造成严重误判或漏测。
05
实战建议:用得好的是“助理”
用不好的是“陷阱”
为了发挥AI在测试用例设计中的最大价值,建议:
建立结构化Prompt模板(Prompt Engineering)
为不同类型用例(功能、接口、安全、异常)设计高质量Prompt模板,引导AI生成结构化内容,降低“发散性”。
使用RAG(Retrieval-Augmented Generaon)增强背景知识
将企业已有的测试用例库、领域词汇表、系统设计文档接入AI,提高上下文感知能力与业务准确性。
建立“AI用例审查机制”
要求每一条AI生成的用例都通过人工或自动审查规则(如字段合法性检查、路径存在性验证)确认有效性。
AI+专家协同建模机制
将AI视为“数据生成器”“策略探索者”,由测试专家进行抽象建模与用例策略控制,实现真正的人机协作。
06
结语:AI生成用例
信任的背后是治理
AI生成测试用例究竟能信多深?答案不是“能”或“不能”,而是:
你是否具备理解、审查、补强与约束AI输出的能力?
测试行业正在迎来一次范式转移,从“人工主导”转向“AI协同”。AI不是银弹,也不是魔法,但它可以成为每一个测试的思维。
只有当我们建立起正确的认知、方法与治理体系,才能真正让AI成为可信赖的测试助手,而不是失控的生成陷阱。
声明:

猜你喜欢
-
发布了文章 2周前
失败 AI 产品列表
失败 AI 产品列表简单分享一份下线 AI 产品的信息列表(AI Graveyard),里面囊括的产品小类非常多。...
-
发布了文章 1个月前
白读白度拜读baidu09智联招聘带来AI招聘助手艾琳“Ailin”,接入DeepSeek
为了更好地满足企业和求职者的需求,智联招聘已推出了AI招聘助手“Ailin”。Ailin集AI发职位、AI筛简历、AI人才推荐、AI帮聊、AI易面等功能于一体,旨在通过智能化手段优化招聘流程,提升招聘效率和质量。另外,官方宣...

-
发布了文章 1个月前
台风桦加沙的生成过程是怎样的?
超强台风“桦加沙”的生成过程1. 初始生成与能量来源“桦加沙”于2025年9月21日8时在菲律宾以东洋面生成,其发展初期得益于高海温区(超过29℃)的持续能量供应,暖水层深厚,为台风增强提供了充沛的热力条件。2...

-
发布了文章 2个月前
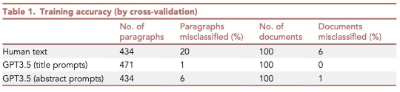
AI检测器又活了?成功率高达98%,吊打OpenAI
AI检测器又活了?成功率高达98%,吊打OpenAI OpenAI都搞不定的问题,被堪萨斯大学的一个研究团队解决了?他们开发的学术AI内容检测器,准确率高达98%。如果将这个技术再学术圈广泛推广,AI论文泛滥的可能得到...
-
发布了文章 2个月前
Salesforce AI Research 刘志伟:像Agent一样思考 - Agent Insights
Salesforce AI Research 刘志伟:像Agent一样思考 | Agent Insights 一套针对 Agent 的标准协议,可以减少开发者的很多重复劳动。AgentLite 便是其中一个起点,专注从...
-
发布了文章 2个月前
通过Test-Time训练生成一分钟视频
...

-
发布了文章 2个月前
谷歌生成式AI终于支持文章总结了
...

-
发布了文章 2个月前
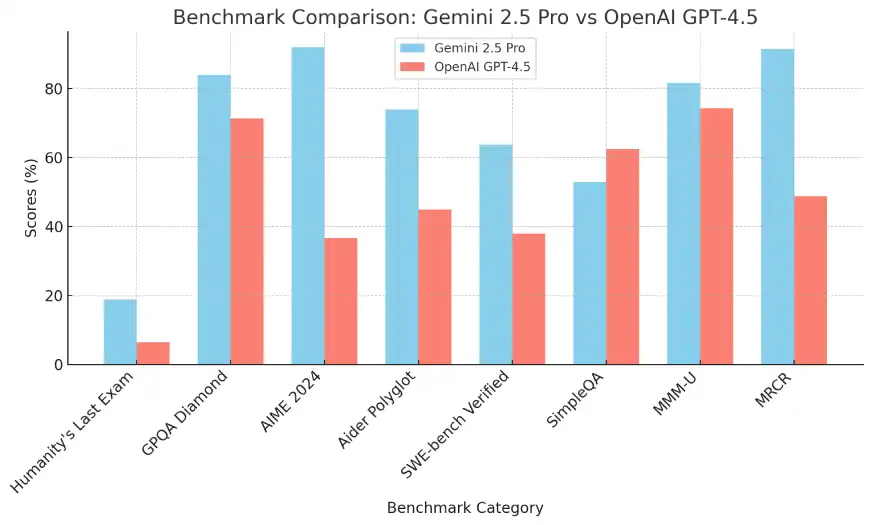
谷歌最新AI模型Gemini 2.5 Pro能否打败GPT 4.5?
...







全部评论
留言在赶来的路上...
发表评论