LLaDA-V是中国人民大学高瓴人工智能学院、蚂蚁集团推出的多模态大语言模型(MLLM),基于纯扩散模型架构,专注于视觉指令微调。模型在LLaDA的基础上,引入视觉编码器和MLP连接器,将视觉特征映射到语言嵌入空间,实现有效的多模态对齐。LLaDA-V在多模态理解方面达到最新水平,超越现有的混合自回归-扩散和纯扩散模型。

(图片来源网络,侵删)

(图片来源网络,侵删)


LLaDA-V是中国人民大学高瓴人工智能学院、蚂蚁集团推出的多模态大语言模型(MLLM),基于纯扩散模型架构,专注于视觉指令微调。模型在LLaDA的基础上,引入视觉编码器和MLP连接器,将视觉特征映射到语言嵌入空间,实现有效的多模态对齐。LLaDA-V在多模态理解方面达到最新水平,超越现有的混合自回归-扩散和纯扩散模型。

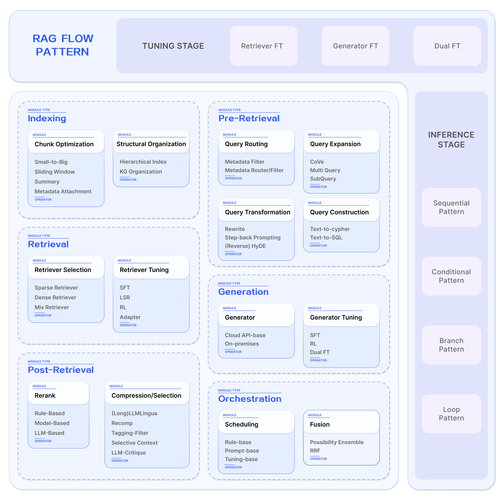
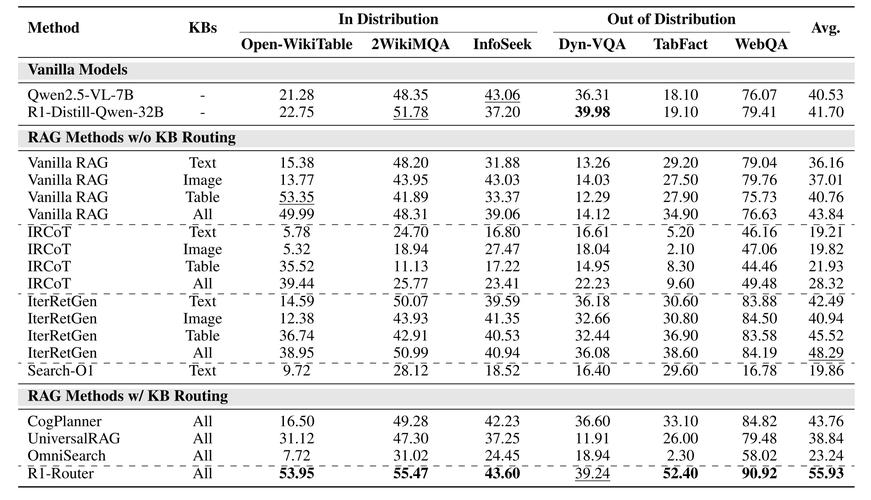
Search-o1是中国人民大学和清华大学推出的创新框架,能提升大型推理模型(LRMs)在面对复杂问题时的推理能力。基于整合代理检索增强生成(RAG)机制和Reason-in-Documents模块,让LRMs在推理过程中动...
全部评论
留言在赶来的路上...
发表评论