

拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。基于RV1126开发板的AI算法开发流程机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。基于RV1126开发板的AI算法开发流程资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
开发流程由以下流程组成:
算法的功能常常可以用一个短词概括,如人脸识别、司机行为检测、商场顾客行为分析等系统,但是却需要依靠多个子算法的有序运作才能达成。其原因在于子算法的结构各有不同,这些结构的差异化优化了各个子算法在其功能上的实现效果。

以下我们列出组成例子:
例子a: 人脸识别算法 = 人脸检测(检测模型)+ 矫正人脸姿态模型(关键点定位模型)+ 人脸比对模型(相似度比对模型)

例子b: 司机行为检测算法 = 人脸识别算法(具体组成如上例)+ 抽烟玩等危险动作识别(检测模型) + 疲劳驾驶检测(关键点定位模型)+ 车道线偏移检测(检测模型)
例子c: 商场分析 = 人脸识别算法(具体组成如首例)+ 人体跟踪算法(检测模型 + 相似度比对模型)
只有在确定了具体需求所需要的步骤后,我们才能有的放矢的采集数据,优化模型,训练出合乎我们需求的模型。
即使准备数据在大多数人看来是繁琐重复的工作,这期间仍有许多细节需要注意的。
数据样本需要良好的多样性。样本多样性是保证算法泛化能力的基础,例如想要识别农产品的功能中,假如我们只是搜集红苹果的数据,那么训练出来的网络就很难将绿色的苹果准确识别出。同时还需要加入充足的负样本,例如我们只是单纯地把农产品的图片数据喂给神经网络,那么我们就很难期望训练出来的神经网络可以有效区分真苹果还有塑料苹果。为了增强算法的可靠性,我们就需要充分的考虑到实际应用场景中会出现什么特殊情况,并将该种情况的数据添加进我们的训练数据里面。
数据样本是否可被压缩。单个样本数据的大小往往决定了网络模型的运行效率,在保证效果的情况下,应当尽量压缩图片的大小来提高运行效率,如112x112的图片,在相同环境下的处理速度将比224x224图片的快4倍左右。但是有些场景却是需要完整的图片来保证图片信息不会丢失,如山火检测一般需要很高的查全率,过度的压缩都会导致查全率下降导致算法效果不佳。
数据需要合适正确的标注与预处理。数据标注在一定程度上决定了训练效果能达到的高度,过多的错误标记将带来一个无效的训练结果。而数据的预处理,是指先对数据做出一定的操作,使其更容易被机器读懂,例如农产品在画面中的位置,如果是以像素点为单位,如农产品的点在左起第200个像素点,这种处理方式虽然直观准确,但是会因为不同像素点之间的差距过大,导致训练困难,这个时候就需要将距离归一化,如中心点在图中左起40%宽的位置上。而的预处理更为多样,不同的分词方式、傅里叶变换都会影响训练结果。
数据的准备不一定得在一开始就做到毫无遗漏。模型训练完成后,如果有一定的效果但还存在部分缺陷,就可以考虑添加或优化训练样本数据,对已有模型进行复训练修正。即使是后期的优化,增添合适的照片往往是最有效的效果。所以对数据的考量优化应该贯穿整个流程,不能在只是在开头阶段才关注数据样本的问题。
通常来讲,对于同一个功能,存在着不同的模型,它们在精度、计算速率上各有长处。模型来发现主要来源于学术研究、公司之间的公开比赛等,所以在研发过程中,就需从业人员持续地关注有关ai新模型的文章;同时对旧模型的积累分析也是十分重要的,这里我们在 下表 中列出目前在各个功能上较优的模型结构以供参考。
对于有AI开发经验的研发人员,可以用自己熟悉的常见框架训练即可,如、pytorch、caffe等主流框架,我们的开发套件可以将其转为EASY EAI Nano的专用模型。
研发nsorflow、pytorch、caffe等自主的模型后,需先将模型转换为rknn模型。同时一般需要对模型进行量化与预编译,以达到运行效率的提升。
模型转换环境搭建流程如下所示:
为了保证模型转换工具顺利运行,请下载网盘里“AI算法开发/RKNN-Toolkit模型转换工具/rknn-toolkit-v1.7.1/docker/rknn-toolkit-1.7.1-docker.tar.gz”。
网盘下载链接:https://pan.baidu.com/s/1LUtU_-on7UB3kvloJlAMkA 提取码:teuc
把下载完成的docker镜像移到我司的虚拟机ubuntu18.04的rknn-toolkit目录,如下图所示:
在该目录打开终端:
执行以下指令加载模型转换工具docker镜像:
docker lo --input /home/developer/rknn-toolkit/rknn-toolkit-1.7.1-docker.tar.gz
执行以下指令进入镜像bash环境:
docker run -t -i --privileged -v /dev/bus/:/dev/bus/usb rknn-toolkit:1.7.1 /bin/bash
现象如下图所示:
输入“”加载python相关库,尝试加载rknn库,如下图环境测试成功:
至此,模型转换工具环境搭建完成。
EASY EAI Nano支持.rknn后缀的模型的评估及运行,对于常见的tensorflow、tensroflow lite、caffe、darknet、onnx和Pytorch模型都可以通过我们提供的 toolkit 工具将其转换至 rknn 模型,而对于其他框架训练出来的模型,也可以先将其转至 onnx 模型再转换为 rknn 模型。
模型转换操作流程入下图所示:
下载百度网“AI算法开发/模型转换Demo/model_convert.tar.bz2”。把model_convert.tar.bz2解压到虚拟机,如下图所示:
下载链接:https://pan.baidu.com/s/1OjDXM8kGXDbn5BqIeErpmw 提取码:drv0
执行以下指令把工作区域映射进docker镜像,其中/home/developer/rknn-toolkit/model_convert为工作区域,/test为映射到docker镜像,/dev/bus/usb:/dev/bus/usb为映射usb到docker镜像:
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/developer/rknn-toolkit/model_convert:/test rknn-toolkit:1.7.1 /bin/bash
执行成功如下图所示:
模型转换测试Demo由coco_object_detect和quant_dataset组成。coco_object_detect存放软件脚本,quant_dataset存放量化模型所需的数据。如下图所示:
coco_object_detect文件夹存放以下内容,如下图所示:
在docker环境切换到模型转换工作目录:
cd /test/coco_object_detect/
如下图所示:
执行gen_list.py生成量化图片列表:
python gen_list.py
命令行现象如下图所示:
生成“量化图片列表”如下文件夹所示:
rknn_convert.py脚本默认进行int8量化操作,脚本代码清单如下所示:
import os import urllib import treback import me import sys import numpy as np import cv2 from rknn.a import RKNN ONNX_MODEL = yolov5_coco.onnx RKNN_MODEL = ./yolov5_coco_rv1126.rknn DATASET = ./pic_path.txt QUANTIZE_ON = True if __name__ == __main__: # Create RKNN object rknn = RKNN(verbose=True) if not os.path.exists(ONNX_MODEL): print(model not exist) exit(-1) # pre-process config print(--> Config model) rknn.config(reorder_channel=0 1 2, mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], optimization_level=3, target_platform = rv1126, output_optimize=1, quantize_input_node=QUANTIZE_ON) print(done) # Load ONNX model print(--> Long model) ret = rknn.load_onnx(model=ONNX_MODEL) if ret != 0: print(Load yolov5 fai!) exit(ret) print(done) # Build model print(--> Building model) ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET) if ret != 0: print(Build yolov5 failed!) exit(ret) print(done) # Export RKNN model print(--> Export RKNN model) ret = rknn.export_rknn(RKNN_MODEL) if ret != 0: print(Export yolov5rknn failed!) exit(ret) print(done)
在执行rknn_convert.py脚本进行模型转换:
python rknn_convert.py
生成模型如下图所示,此模型可以在rknn环境和EASY EAI Nano环境运行:
用yolov5_coco_test.py脚本在PC端的环境下可以运行rknn的模型,如下图所示:
yolov5_coco_test.py脚本程序清单如下所示:
import os import urllib import traceback import time import sys import numpy as np import cv2 import random from rknn.api import RKNN RKNN_MODEL = yolov5_coco_rv1126.rknn IMG_PATH = ./test.jpg DATASET = ./dataset.txt BOX_THRESH = 0.25 NMS_THRESH = 0.6 IMG_SIZE = 640 CLASSES = ("peon", "bicycle", "car","motorbike ","aeroplane ","bus ","train","truck ","boat","traffic light", "fire hydrant","stop sign ","parking meter","bench","bird","cat","dog ","horse ","sheep","cow","elephant", "bear","zebra ","giraffe","backpack","umbrella","handbag","tie","suitcase","frisbee","skis","snowboard","sports ball","kite", "baseball bat","baseball glove","skateboard","suboard","tennis racket","bottle","wine glass","cup","fork","knife", "spoon","bowl","banana","apple","sandwich","orange","broccoli","carrot","hot dog","pizza ","donut","cake","chair","sofa", "pottedplant","bed","diningtable","toilet ","tvmonitor","laptop","mouse","remote ","keyboard ","cell phone","microwave ", "oven ","toaster","sink","refrigerator ","book","clock","vase","scissors ","teddy bear ","hair drier", "toothbrush") def sigmoid(x): return 1 / (1 + np.exp(-x)) def xywh2xyxy(x): # Convert [x, y, w, h] to [x1, y1, x2, y2] y = np.copy(x) y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y return y def process(input, mask, anchors): anchors = [anchors[i] for i in mask] grid_h, grid_w = map(int, input.shape[0:2]) box_confidence = sigmoid(input[..., 4]) box_confidence = np.expand_dims(box_confidence, axis=-1) box_class_probs = sigmoid(input[..., 5:]) box_xy = sigmoid(input[..., :2])*2 - 0.5 col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w) row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h) col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2) row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2) grid = np.concatenate((col, row), axis=-1) box_xy += grid box_xy *= int(IMG_SIZE/grid_h) box_wh = pow(sigmoid(input[..., 2:4])*2, 2) box_wh = box_wh * anchors box = np.concatenate((box_xy, box_wh), axis=-1) return box, box_confidence, box_class_probs def filter_boxes(boxes, box_confidences, box_class_probs): """Filter boxes with box threshold. Its a bit different with origin yolov5 post process! # Arguments boxes: ndarray, boxes of objects. box_confidences: ndarray, confidences of objects. box_class_probs: ndarray, class_probs of objects. # Returns boxes: ndarray, filtered boxes. classes: ndarray, classes for boxes. scores: ndarray, scores for boxes. """ box_scores = box_confidences * box_class_probs box_classes = np.argmax(box_class_probs, axis=-1) box_class_scores = np.max(box_scores, axis=-1) pos = np.where(box_confidences[...,0] >= BOX_THRESH) boxes = boxes[pos] classes = box_classes[pos] scores = box_class_scores[pos] return boxes, classes, scores def nms_boxes(boxes, scores): """Suppress non-al boxes. # Arguments boxes: ndarray, boxes of objects. scores: ndarray, scores of objects. # Returns keep: ndarray, index of effective boxes. """ x = boxes[:, 0] y = boxes[:, 1] w = boxes[:, 2] - boxes[:, 0] h = boxes[:, 3] - boxes[:, 1] areas = w * h order = scores.argsort()[::-1] keep = [] while order.size > 0: i = order[0] keep.append(i) xx1 = np.maximum(x[i], x[order[1:]]) yy1 = np.maximum(y[i], y[order[1:]]) xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]]) yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]]) w1 = np.maximum(0.0, xx2 - xx1 + 0.00001) h1 = np.maximum(0.0, yy2 - yy1 + 0.00001) inter = w1 * h1 o = inter / (areas[i] + areas[order[1:]] - inter) inds = np.where(ovr <= NMS_THRESH)[0] order = order[inds + 1] keep = np.array(keep) return keep def yolov5_post_process(input_data): masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]] anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]] boxes, classes, scores = [], [], [] for input,mask in zip(input_data, masks): b, c, s = process(input, mask, anchors) b, c, s = filter_boxes(b, c, s) boxes.append(b) classes.append(c) scores.append(s) boxes = np.concatenate(boxes) boxes = xywh2xyxy(boxes) classes = np.concatenate(classes) scores = np.concatenate(scores) nboxes, nclasses, nscores = [], [], [] for c in set(classes): inds = np.where(classes == c) b = boxes[inds] c = classes[inds] s = scores[inds] keep = nms_boxes(b, s) nboxes.append(b[keep]) nclasses.append(c[keep]) nscores.append(s[keep]) if not nclasses and not nscores: return None, None, None boxes = np.concatenate(nboxes) classes = np.concatenate(nclasses) scores = np.concatenate(nscores) return boxes, classes, scores def scale_coords(x1, y1, x2, y2, dst_width, dst_height): dst_top, dst_left, dst_right, dst_bottom = 0, 0, 0, 0 gain = 0 if dst_width > dst_height: image_max_len = dst_width gain = IMG_SIZE / image_max_len resized_height = dst_height * gain height_pading = (IMG_SIZE - resized_height)/2 print("height_pading:", height_pading) y1 = (y1 - height_pading) y2 = (y2 - height_pading) print("gain:", gain) dst_x1 = int(x1 / gain) dst_y1 = int(y1 / gain) dst_x2 = int(x2 / gain) dst_y2 = int(y2 / gain) return dst_x1, dst_y1, dst_x2, dst_y2 def plot_one_box(x, img, color=None, label=None, line_thickness=None): tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness color = color or [random.randint(0, 255) for _ in range(3)] c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3])) cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA) if label: = max(tl - 1, 1) # font thickness t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0] c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3 cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA) def draw(image, boxes, scores, classes): """Draw the boxes on the image. # Argument: image: original image. boxes: ndarray, boxes of objects. classes: ndarray, classes of objects. scores: ndarray, scores of objects. all_classes: all classes name. """ for box, score, cl in zip(boxes, scores, classes): x1, y1, x2, y2 = box print(class: {}, score: {}.format(CLASSES[cl], score)) print(box coordinate x1,y1,x2,y2: [{}, {}, {}, {}].format(x1, y1, x2, y2)) x1 = int(x1) y1 = int(y1) x2 = int(x2) y2 = int(y2) dst_x1, dst_y1, dst_x2, dst_y2 = scale_coords(x1, y1, x2, y2, image.shape[1], image.shape[0]) #print("img.cols:", image.cols) plot_one_box((dst_x1, dst_y1, dst_x2, dst_y2), image, label={0} {1:.2f}.format(CLASSES[cl], score)) cv2.rectangle(image, (dst_x1, dst_y1), (dst_x2, dst_y2), (255, 0, 0), 2) cv2.putText(image, {0} {1:.2f}.format(CLASSES[cl], score), (dst_x1, dst_y1 - 6), cv2.FONT_HERSHEY_PLEX, 0.6, (0, 0, 255), 2) def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)): # Resize and pad image while meeting stride-multiple constraints shape = im.shape[:2] # current shape [height, width] if isinstance(new_shape, int): new_shape = (new_shape, new_shape) # Scale ratio (new / old) r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) # Compute padding ratio = r, r # width, height ratios new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding dw /= 2 # divide padding into 2 sides dh /= 2 if shape[::-1] != new_unpad: # resize im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_) top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1)) left, right = int(round(dw - 0.1)), int(round(dw + 0.1)) im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border return im, ratio, (dw, dh) if __name__ == __main__: # Create RKNN object rknn = RKNN(verbose=True) print(--> Loading model) ret = rknn.load_rknn(RKNN_MODEL) if ret != 0: print(load rknn model failed) exit(ret) print(done) # init runtime environment print(--> Init runtime environment) ret = rknn.init_runtime() # ret = rknn.init_runtime(rv1126, device_id=1126) if ret != 0: print(Init runtime environment failed) exit(ret) print(done) # Set inputs img = cv2.imread(IMG_PATH) letter_img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE)) letter_img = cv2.cvtColor(letter_img, cv2.COLOR_BGR2RGB) # Inference print(--> Running model) outputs = rknn.inference(inputs=[letter_img]) print(--> inference done) # post process input0_data = outputs[0] input1_data = outputs[1] input2_data = outputs[2] input0_data = input0_data.reshape([3,-1]+list(input0_data.shape[-2:])) input1_data = input1_data.reshape([3,-1]+list(input1_data.shape[-2:])) input2_data = input2_data.reshape([3,-1]+list(input2_data.shape[-2:])) input_data = list() input_data.append(np.transpose(input0_data, (2, 3, 0, 1))) input_data.append(np.transpose(input1_data, (2, 3, 0, 1))) input_data.append(np.transpose(input2_data, (2, 3, 0, 1))) print(--> transpose done) boxes, classes, scores = yolov5_post_process(input_data) print(--> get result done) #img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) if boxes is not None: draw(img, boxes, scores, classes) cv2.imwrite(./result.jpg, img) #cv2.imshow("post process result", img_1) #cv2.waitKeyEx(0) rknn.release()
执行yolov5_coco_test.py脚本测试rknn模型:
python yolov5_coco_test.py
执行后得到result.jpg如下图所示:
由于rknn模型用NPU API在EASY EAI Nano加载的时候启动速度会好慢,在评估完模型精度没问题的情况下,建议进行模型预编译。预编译的时候需要通过EASY EAI Nano主板的环境,所以请务必接上adb口与ubuntu保证稳定连接。
板子端接线如下图所示,拨码开关需要是adb:
虚拟机要保证接上adb设备:
由于在虚拟机里ubuntu环境与docker环境对adb设备资源是竞争关系,所以需要关掉ubuntu环境下的adb服务,且在docker里面通过apt-get安装adb软件包。以下指令在ubuntu环境与docker环境里各自执行:
在docker环境里执行adb devices,现象如下图所示则设备连接成功:
运行precompile_rknn.py脚本把模型执行预编译:
python precompile_rknn.py
执行效果如下图所示,生成预编译模型yolov5_coco_int8_rv1126_pre.rknn:
至此预编译部署完成,模型转换步骤已全部完成。生成如下预编译后的int8量化模型:
在使用 RKNN-Toolkit 的所有 API 时,都需要先调用 RKNN()方法初始化 RKNN 对象,并 不再使用该对象时,调用该对象的 release()方法进行释放。
初始化 RKNN 对象时,可以设置 verbose 和 verbose_file 参数,以打印详细的日志信息。其中 verbose 参数指定是否要在屏幕上打印详细日志信息;如果设置了 verbose_file 参数,且 verbose 参 数值为 True,日志信息还将写到该参数指定的文件中。如果出现 Error 级别的错误,而 verbose_file 又被设为 None,则错误日志将自动写到 log_feedback_to_the_rknn_toolkit_dev_team.log 文件中。
反馈错误信息给 NPU 团队时,建议反馈完整的错误日志。
举例如下:
# 将详细的日志信息输出到屏幕,并写到 mobilenet_build.log 文件中 rknn = RKNN(verbose=True, verbose_file=’./mobilenet_build.log’) # 只在屏幕打印详细的日志信息 rknn = RKNN(verbose=True) … rknn.release()
在构建 RKNN 模型之前,需要先对模型进行通道均值、通道顺序、量化类型等的配置,这些 操作可以通过 config 接口进行配置。
举例如下:
# model config rknn.config(mean_values=[[103.94, 116.78, 123.68]], std_values=[[58.82, 58.82, 58.82]], reorder_channel=’0 1 2’, need_horizontal_merge=True, target_platform=[‘rk1808’, ‘rk3399pro’]
RKNN-Toolkit 目前支持Caffe, Darknet, Keras, MXNet, ONNX, PyTorch, TensorFlow,和TensorFlow Lite等模型的加载转换,这些模型在加载时需调用对应的接口,以下为这些接口的详细 说明。
举例如下:
#从当前路径加载 mobilenet_v2 模型 ret = rknn.load_caffe(model=’./mobilenet_v2.prototxt’, proto=’caffe’, blobs=’./mobilenet_v2.caffemodel’)
举例如下:
# 从当前目录加载yolov3-tiny模型 ret= rknn.load_darknet(model=‘./yolov3-tiny.cfg’, weight=’./yolov3.weights’)
举例如下:
# 从当前目录加载 xception 模型 ret = rknn.load_keras(model=’./xception_v3.h5’)
举例如下:
# 从当前目录加载 resnext50 模型 ret = rknn.load_mxnet(symbol=’resnext50_32x4d-symbol.json’, params=’resnext50_32x4d-4ecf62e2.params’, input_size_list=[[3,224,224]] )
举例如下:
# 从当前目录加载 resnet50v2 模型 ret = rknn.load_onnx(model = ./resnet50v2.onnx, inputs = [data], input_size_list = [[3, 224, 224]], outputs=[resnetv24_dense0_fwd])
举例如下:
# 从当前目录加载 resnet18 模型 ret = rknn. Load_pytorch(model = ‘./resnet18.pt’, input_size_list=[[3,224,224]])
举例如下:
# 从当前目录加载 ssd_mobilenet_v1_coco_2017_11_17 模型 ret = rknn.load_tensorflow( tf_pb=’./ssd_mobilenet_v1_coco_2017_11_17.pb’, inputs=[‘FeatureExtractor/MobilenetV1/MobilenetV1/Conv2d_0 /BatchNorm/batchnorm/mul_1’], outputs=[‘concat’, ‘concat_1’], input_size_list=[[300, 300, 3]])
举例如下:
# 从当前目录加载 mobilenet_v1 模型 ret = rknn.load_tflite(model = ‘./mobilenet_v1.tflite’)
注:如果在执行脚本前设置RKNN_DRAW_DATA_DISTRIBUTE 环境变量的值为1,则 RKNN Toolkit会将每一层的weihgt/bias(如果有)和输出数据的直方图保存在当前目录下的 dump_data_distribute文件夹中。使用该功能时推荐只在dataset.txt中存放单独一个(组)输入。
举例如下:
# 构建 RKNN 模型,并且做量化 ret = rknn.build(do_quantization=True, dataset=./dataset.txt)
通过该接口导出 RKNN 模型文件,用于模型部署。
举例如下:
…… # 将构建好的 RKNN 模型保存到当前路径的 mobilenet_v1.rknn 文件中 ret = rknn.export_rknn(export_path = ./mobilenet_v1.rknn) ……
举例如下:
# 从当前路径加载 mobilenet_v1.rknn 模型 ret = rknn.load_rknn(path=./mobilenet_v1.rknn)
在模型推理或性能评估之前,必须先初始化运行时环境,明确模型在的运行平台(具体的目标硬件平台或软件模拟器)。
举例如下:
# 初始化运行时环境 ret = rknn.init_runtime(target=rk1808, device_id=012345789AB) if ret != 0: print(Init runtime environment failed) exit(ret)
在进行模型推理前,必须先构建或加载一个 RKNN 模型。
对于分类模型,如mobilenet_v1,模型推理代码如下(完整代码参考 example/tflite/mobilent_v1):
# 使用模型对图片进行推理,输出 TOP5 …… outputs = rknn.inference(inputs=[img]) show_outputs(outputs) ……
输出的 TOP5 结果如下:
-----TOP 5----- [156]: 0.85107421875 [155]: 0.09173583984375 [205]: 0.01358795166015625 [284]: 0.006465911865234375 [194]: 0.002239227294921875
举例如下:
# 对模型性能进行评估 …… rknn.eval_perf(inputs=[image], is_print=True) ……
举例如下:
# 对模型内存使用情况进行评估 …… memory_detail = rknn.eval_memory() ……
如 example/tflite 中的 mobilenet_v1,它在 RK1808 上运行时内存占用情况如下:
============================================== Memory Profile Info Dump ============================================== System memory: maximum allocation : 22.65 MiB total allocation : 72.06 MiB NPU memory: maximum allocation : 33.26 MiB total allocation : 34.57 MiB Total memory: maximum allocation : 55.92 MiB total allocation : 106.63 MiB INFO: When evaluating memory usage, we need consider the size of model, current model size is: 4.10 MiB ==============================================
使用混合量化功能时,第一阶段调用的主要接口是 hybrid_quantization_step1,用于生成模型结构文件( {model_name}.json )、权重文件( {model_name}.data ) 和量化配置文件({model_name}.quantization.cfg)。接口详情如下:
举例如下:
# Call hybrid_quantization_step1 to generate quantization config …… ret = rknn.hybrid_quantization_step1(dataset=./dataset.txt) ……
使用混合量化功能时,生成混合量化 RKNN模型阶段调用的主要接口是 hybrid_quantization_step2。接口详情如下:
举例如下:
# Call hybrid_quantization_step2 to generate hybrid quantized RKNN model …… ret = rknn.hybrid_quantization_step2( model_input=./ssd_mobilenet_v2.json, data_input=./ssd_mobilenet_v2.data, model_quantization_cfg=./ssd_mobilenet_v2.quantization.cfg, dataset=./dataset.txt) ……
注:如果在执行脚本前设置 RKNN_DRAW_DATA_DISTRIBUTE 环境变量的值为 1,则 RKNNToolkit 会将每一层的 weihgt/bias(如果有)和输出数据的直方图保存在当前目录下的 dump_data_distribute 文件夹中。
举例如下:
…… print(--> config model) rknn.config(channel_mean_value=0 0 0 1, reorder_channel=0 1 2) print(done) print(--> Loading model) ret = rknn.load_onnx(model=./mobilenetv2-1.0.onnx) if ret != 0: print(Load model failed! Ret = {}.format(ret)) exit(ret) print(done) # Build model print(--> Building model) ret = rknn.build(do_quantization=True, dataset=./dataset.txt) if ret != 0: print(Build rknn failed!) exit(ret) print(done) print(--> Accuracy analysis) rknn.accuracy_analysis(inputs=./dataset.txt, target=rk1808) print(done) ……
参考代码如下所示。注意,该接口要在模型转换前调用。自定义算子的使用和开发请参考 《Rockchip_Developer_Guide_RKNN_Toolkit_Custom_OP_CN》文档。
rknn.register_op(./resize_area/ResizeArea.rknnop) rknn.load_tensorflow(…)
构建RKNN模型时,可以指定预编译选项以导出预编译模型,这被称为离线编译。同样,RKNN Toolkit 也提供在线编译的接口:export_rknn_precompile_model。使用该接口,可以将普通 RKNN 模型转成预编译模型。
举例如下:
from rknn.api import RKNN if __name__ == __main__: # Create RKNN object rknn = RKNN() # Load rknn model ret = rknn.load_rknn(./test.rknn) if ret != 0: print(Load RKNN model failed.) exit(ret) # init runtime ret = rknn.init_runtime(target=rk1808, rknn2precompile=True) if ret != 0: print(Init runtime failed.) exit(ret) # Note: the rknn2precompile must be set True when call init_runtime ret = rknn.export_rknn_precompile_model(./test_pre_compile.rknn) if ret != 0: print(export pre-compile model failed.) exit(ret) rknn.release()
该接口的功能是将普通的 RKNN 模型转成分段模型,分段的位置由用户指定。
举例如下:
from rknn.api import RKNN if __name__ == __main__: rknn = RKNN() ret = rknn.export_rknn_sync_model( input_model=./ssd_inception_v2.rknn, sync_uids=[206, 186, 152, 101, 96, 67, 18, 17], output_model=./ssd_inception_v2_sync.rknn) if ret != 0: print(export sync model failed.) exit(ret) rknn.release()
该接口的功能是将普通的 RKNN 模型进行加密,得到加密后的模型。
举例如下:
from rknn.api import RKNN if __name__ == __main__: rknn = RKNN() ret = rknn.export_encrypted_rknn_model(test.rknn) if ret != 0: print(Encrypt RKNN model failed.) exit(ret) rknn.release()
举例如下:
# 获取 SDK 版本信息 …… sdk_version = rknn.get_sdk_version() ……
返回的 SDK 信息如下:
============================================== RKNN VERSION: API: 1.7.1 (566a9b6 build: 2021-10-28 14:53:41) DRV: 1.7.1 (566a9b6 build: 2021-11-12 20:24:57) ==============================================
举例如下:
from rknn.api import RKNN if __name__ == __main__: rknn = RKNN() rknn.list_devices() rknn.release()
返回的设备列表信息如下(这里有两个 RK1808 开发板,它们的连接模式都是 adb):

猜你喜欢
-
发布了文章 2个月前
基于RV1126开发板的resnet50训练部署教程
本教程基于图像分类算法ResNet50的训练和部署到EASY-EAI-Nano(RV1126 进行说明...
-
发布了文章 2个月前
基于RV1126开发板实现驾驶员行为检测方案
在RV1126上实现驾驶员行为检测:通过图像识别出这几种行为:打电话、抽烟、疲劳驾驶。...

-
发布了文章 2个月前
基于RV1126开发板实现网络摄像头方案
...
-
发布了文章 2个月前
基于RV1126开发板实现安全帽检测方案
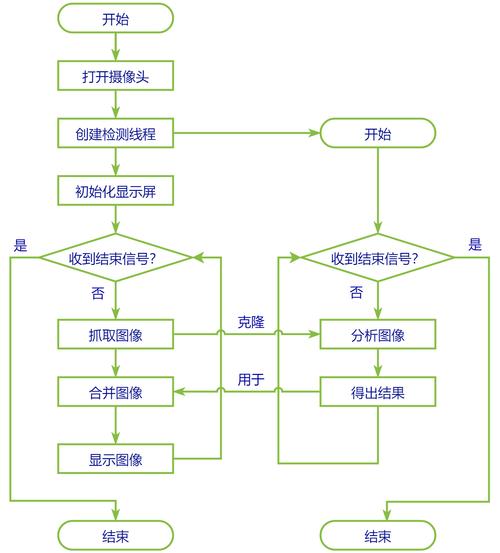
在RV1126开发板上实现安全帽检测:在图像中找出人头/安全帽。 方案设计逻辑流程图,方案代码分为分为两个业务流程,主体代码负责抓取、合成图像,算法代码负责安全帽检测功能。...
-
发布了文章 2个月前
基于RV1126开发板实现人脸识别门禁系统解决方案
本方案为类人脸门禁机的产品级解决方案,已为用户构建一个带调度框架的UI应用工程;准备好我司的easyeai-api链接调用;准备好UI的开发环境。具备低模块耦合度的特点。其目的在于方便用户快速拓展自定义的业务功能模块,以及快...
-
发布了文章 2个月前
基于RV1126开发板实现人脸检测方案
在RV1126开发板上实现人脸检测:在图像中找出人脸,以及每张人脸的landmarks位置。 方案设计逻辑流程图,方案代码分为分为两个业务流程,主体代码负责抓取、合成图像, 算法代码负责人脸检测功能。...
-
发布了文章 2个月前
基于RV1126开发板实现人员检测方案
在RV1126上实现人员检测:在图像中找出人。 方案设计逻辑流程图,方案代码分为分为两个业务流程,主体代码负责抓取、合成图像,算法代码负责人员检测功能。...






全部评论
留言在赶来的路上...
发表评论