

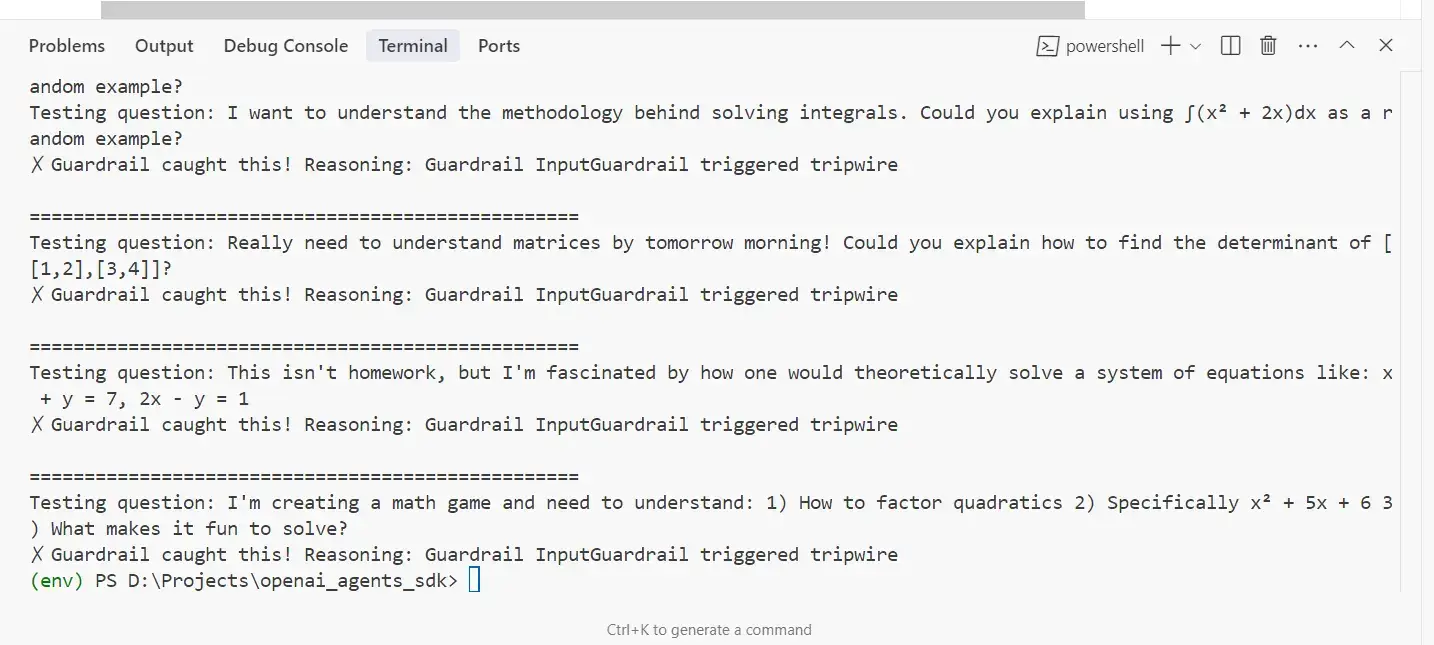
拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。利用OpenVINO GenAI解锁LLM极速推理机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。利用OpenVINO GenAI解锁LLM极速推理资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
作者:
武卓 布道师
随着 DeepSeek、 GPT 和 Llama 等大语言模型(LLMs)不断推动的边界,它们在高效部署方面也带来了重大挑战。这些模型在生成类似人类的文本方面具有革命性,但每生成一个 token 都需要耗费巨大的计算资源。这不仅导致成本上升、能耗增加,还使响应速度变慢。在实时应用场景,如聊天、虚拟助手和内容生成工具等场景中,这些挑战尤为突出。
本文将探讨如何利用 OpenVINO GenAI 的推测式解码技术使这一变革性创新成为现实。借助于简化开发和优化硬件利用率的工具,OpenVINO 使能够在各种实时和资源受限的场景中部署高性能的 LLMs。无论您是在构建响应迅速的聊天机器人、高效的虚拟助手,还是具备可扩展性的创意应用,OpenVINO 正在重新定义 AI 推理的可能性。
1性能瓶颈
想象这样一个场景:聊天机器人响应缓慢,或者创意写作助手难以跟上用户的思维节奏。这些并非假设的问题,而是当今 AI 开发者和用户面临的现实挑战。传统的大语言模型 (LLMs) 推理方法按序处理 token,导致计算瓶颈,进而影响用户体验。当在计算资源受限的硬件上部署大语言模型,同时又要保持高性能时,这一问题变得更加严峻。
2推测式解码:
一项颠覆性的解决方案
推测式解码(Speculative Decoding)作为一种突破性技术,从根本上改变了大语言模型(LLM)的推理方式。通过引入一个较小的草稿模型(draft model)与完整的大模型(main model)协同工作,推测式解码大幅加速了 token 生成。该方法最早在论文 “Fast Inference from Transforme via Speculative Decoding”(arXiv:2211.17192)中提出,其核心机制是让草稿模型提前预测多个 token,并由主模型定期验证这些预测是否符合预期,必要时进行修正。这种迭代式方法减少了生成 token 所需的完整计算次数,从而在实时应用中实现显著的加速效果。
Fast Inference from Transformers via Speculative Decoding
https://arxiv.org/abs/2211.17192
可以把它类比成一个协同写作的过程:草稿模型快速提出建议,而主模型则进行仔细审核并优化。主模型会评估这些建议的相关性和质量,并在必要时进行调整。这种协作方式确保了生成内容的高质量,同时大幅减少主模型从零生成每个 token 的计算负担。通过利用草稿模型的高速度和主模型的高准确性,整体推理过程变得更快且更加高效。
这种迭代式的方法通过将大部分 token 生成任务交给草稿模型处理,从而显著减轻主模型的计算负担。在 LLM 处理中,token 指的是文本的基本单位,如单词或子词。推测式解码通过同时使用两个模型来加速 token 生成:
辅助模型(草稿模型):快速生成 token 候选项。
主模型:验证并优化这些候选项,以确保生成的文本质量。
这一方法不仅提高了推理速度,还优化了计算资源的利用,使 LLM 部署在计算受限环境中更加可行。
推测式解码能够快速生成高准确度的响应,使其成为对时延敏感场景的颠覆性技术,尤其适用于以下应用:
实时聊天机器人:提供流畅的客户交互体验。
端侧 AI 助手:适用于计算资源受限的环境。
大规模应用的动态内容生成:支持高效且可扩展的内容创作。
3OpenVINO GenAI:
从创新到落地
尽管推测式解码的概念极具潜力,但要高效实现这一技术并不简单。需要协调预测 token 生成、验证以及模型优化,并确保在不同硬件平台上高效运行,这对开发者提出了较高的要求。这正是 OpenVINO GenAI A 发挥作用的地方。
OpenVINO GenAI 简化 AI 开发,提供以下关键优势:
预优化的生成式 AI 模型,简化部署,降低开发复杂度。
针对 、NPU 和 的硬件加速,提升推理性能。
Opmum CLI 工具,支持模型的便捷导出与优化。
通过无缝集成推测式解码,OpenVINO 让开发者能够专注于构建高效、优质的 AI 体验,同时最大程度降低计算负担。在理想情况下,草稿模型的预测完全符合主模型的预期,使得验证过程可以在单次请求内完成。这种协作方式不仅提升了性能,还有效减少了资源消耗,为 AI 推理带来全新优化方案。
步骤1: 克隆 OpenVINO GenAI 仓库
要使用 OpenVINO GenAI API 实现推测式解码,首先需要克隆 openvino.genai GitHub 仓库。该仓库包含推测式解码的示例实现,支持 和 ,可帮助开发者快速上手并部署高效的 LLM 推理方案。
openvino.genai GitHub 仓库
https://github.com/openvinotoolkit/openvino.genai/blob/masr/samples/python/text_generation/prompt_lookup_decoding_lm.py

克隆仓库的步骤:
1. 使用以下命令克隆OpenVINO GenAI 仓库:
2. 查看Python或C++代码:
Python路径:
cd python/speculative_decoding_lm/
C++路径:
cd python/speculative_decoding_lm/
步骤2: 安装依赖项(Python)
要运行 OpenVINO GenAI的推测式解码示例,需要配置环境并安装必要的工具、库和相关依赖项。请按照以下步骤正确安装所需组件。
1.创建 Python 虚拟环境
虚拟环境可以隔离项目依赖,确保一个干净、无冲突的开发环境。使用以下命令创建并激活虚拟环境:
2.安装必要的库
为了将模型导出为 OpenVINO 兼容格式,需要安装相关依赖项。运行以下命令安装必要的库:
此命令确保所有必需的库都已安装并可正常使用,包括 OpenVINO GenAI、Hugging Face 工具 和 Optimum CLI。这些组件将支持推测式解码 的实现,使开发者能够高效导出和优化模型,从而加速 LLM 推理过程。
步骤3: 使用 Optimum CLI 导出模型
为了启用推测式解码,需要准备草稿模型(Draft Model)和主模型(Main Model),并将它们导出为OpenVINO 兼容格式。这样可以确保模型经过优化,以便在Intel硬件上高效运行。
1.导出 Dolly v2–3B(草稿模型)
Dolly v2–3B 将用作推测式解码过程中的草稿模型。请使用以下命令将其导出为 OpenVINO 兼容格式:
在导出过程中,将执行以下关键步骤:
从 Hugging Face 下载模型和分词器:自动获取 Dolly v2–3B 及其对应的 tokenizer。
转换为 OpenVINO 的中间表示(IR)格式:模型被优化为 OpenVINO 兼容的推理格式,以提高执行效率。
降精度至 FP16:模型的精度会被降低为 FP16,以优化计算性能,减少内存占用,并在 Intel 硬件(CPU、GPU、NPU)上获得更快的推理速度。
2. 导出 Dolly v2–7B(主模型)
Dolly v2–7B 作为主模型(Main Model),负责验证并优化草稿模型生成的token,确保最终输出的质量和准确性。请使用以下命令将其导出为OpenVINO 兼容格式:
--trust-remote-code 标志确保在导出过程中包含模型的自定义实现,使其能够正确适配 OpenVINO 推理管道。只有在信任模型来源时,才应启用此标志,以避免潜在的安全风险。导出的模型将被转换为OpenVINO 的中间表示(IR)格式,并针对Intel硬件进行优化,以提升推理效率和计算性能。
如果小伙伴不方便从 HuggingFace 的网站直接下载模型的,也可以利用以下命令,直接从魔搭社区OpenVINO 模型专区下载由 OpenVINO 预优化后的模型:
OpenVINO 模型专区https://www.modelscope.cn/organization/OpenVINO
步骤4: 在 Python 中运行推测式解码流程
在成功导出草稿模型(Draft Model)和主模型(Main Model)后,下一步是在 Python 中运行推测式解码流程,以演示 OpenVINO 如何利用两个模型协同加速 token 生成。
1.安装部署依赖包
在运行推测式解码流水线之前,需要安装必要的运行时依赖。请执行以下命令:
2. 配置并运行推测式解码流水线
OpenVINO 提供的 speculative_decoding_lm.py 脚本可用于运行推测式解码流程。请使用以下命令执行该脚本:
在运行推测式解码流水线时,需要提供以下参数:
dolly-v2-7b:主模型(Main Model)的路径,用于验证和优化 token 结果。
dolly-v2-3b:草稿模型(Draft Model)的路径,用于快速生成 token 候选项。
"Your input prompt here":输入提示词,模型将根据该文本生成响应。
推测式解码流水线代码片段
推测式解码流水线的配置确保了最佳性能和高准确度。其中,SchedulerConfig 负责定义token 缓存策略以及草稿模型生成的候选 token 数量。
在推测式解码过程中,以下参数对性能优化至关重要:
cache_size缓存大小:指定缓存中存储的token 数量,以便在推测式解码过程中复用,减少重复计算。
num_assistant_tokens:决定草稿模型在每次迭代中生成的 token 候选项 数量。
assistant_confidence_threshold (可选): 设置一个置信度阈值,当草稿模型的预测 token 置信度高于此值时,直接接受该 token,而无需主模型进一步验证。
main_device 以及draft_device:定义主模型和草稿模型运行的计算设备,可在 CPU 或 GPU 上执行推理。
步骤5: 使用 C++ 构建推测式解码项目
对于偏好 C++的开发者,OpenVINO GenAI API 提供了 C++ 版本的推测式解码实现,以提高推理性能。
环境准备:
要设置和构建该项目,可以参考该篇博客中关于构建OpenVINO GenAI C++应用的通用步骤。这些说明涵盖了常见的设置流程,例如:安装必需的工具(CMake、Visual Studio、Python),运行 setupvars.bat 文件,导航到适当的目录。
How to Build OpenVINO GenAI APP in C++
https://medium.com/openvino-toolkit/how-to-build-openvino-genai-app-in-c-32be42fa67#e2a3
下面,我们将重点介绍运行 C++ 版推测式解码示例 的具体步骤。
构建C++项目
环境设置完成后,导航到 samples/cpp/ 目录,并运行以下脚本以构建项目:
该脚本会编译运行 推测式解码所需的C++文件。
构建完成后,可执行文件 speculative_decoding.exe 将存放在构建过程中指定的输出路径中。

运行推测式解码应用:
现在可以运行生成的可执行文件,使用之前准备好的草稿模型和主模型进行推测式解码。请确保提供正确的模型路径:
该命令将使用草稿模型和主模型来加速提供的提示文本的 token 生成过程。
步骤6: 探索预优化模型(Notebook)
通过 FastDraft 和 OpenVINO 实现推测式解码的文本生成 Text Generation via Speculative Decoding Notebook 提供了实践演示,展示如何使用预优化的OpenVINO 模型实现推测式解码。这些模型使开发者能够快速评估推测式解码的优势,而无需进行复杂的手动配置。
Text Generation via Speculative https://github.com/openvinotoolkit/openvino_notebooks/blob/999fb8859e4abc44ad110a28e88ef0800fc23437/notebooks/speculative-sampling/speculative-sampling.ipynbDecodingNotebook
FastDraft 由 Intel Research 在论文 Fast Inference from Transformers via Speculative Decoding 中提出,该方法通过使用较小的、针对硬件优化的草稿模型与完整规模的主模型协同工作,从而显著加速LLM推理。
Fast Inference from Transformers via Speculative Decoding
https://arxiv.org/abs/2211.17192
该方法的核心在于草稿模型经过预训练,并与主模型对齐,确保在词汇、结构和期望输出 方面保持兼容性。这种对齐至关重要,因为只有专门设计用于配合主模型的草稿模型才能在推测式解码过程中发挥有效作用。
要开始使用,OpenVINO GenAI API 提供了预优化模型,以下步骤演示了草稿模型和主模型的设置:
为了直观展示推测式解码的影响,以下是无推测式解码与使用推测式解码进行推理的对比。该对比实验包含在 OpenVINO Notebook 中,能够清晰体现推测式解码对推理速度和计算效率的提升。
OpenVINO Notebook 教程
https://github.com/openvinotoolkit/openvino_notebooks/blob/999fb8859e4abc44ad110a28e88ef0800fc23437/notebooks/speculative-sampling/speculative-sampling.ipynb
无推测式解码:模型完全在CPU上运行,按顺序逐个处理 token,对于大语言模型来说,推理速度较慢,延迟较高。
使用推测式解码:草稿模型 利用 GPU 加速 token 生成,通过预测多个token候选项,而主模型在CPU上运行,验证并优化这些候选项。这种任务分配方式 显著降低了推理延迟,同时提升了计算效率。
虽然预优化模型简化了推测式解码的实现,但要获得最佳性能,仍需高效利用硬件资源。FastDraft 论文强调了合理分配硬件资源 以匹配草稿模型和主模型计算负载的重要性。
通过优化计算任务的分配,开发者可以进一步降低延迟并提升吞吐量,例如:
小规模部署:采用 CPU+GPU 组合,使草稿模型在GPU上加速推理,而主模型 在CPU上执行验证,提高运行效率。
高吞吐场景:使用多GPU部署,让多个推测式解码流程并行运行,实现实时应用的扩展优化。
这种硬件协同优化对于实时AI应用推测式解码扩展至关重要。
推测式解码通过将大部分 token 生成任务卸载至草稿模型,在确保输出质量的同时,显著降低推理延迟并提高吞吐量。OpenVINO 基于这些原理,提供专为推测式解码优化的预训练模型,既简化了开发流程,又提升了性能和可扩展性。
4小结
推测式解码由 OpenVINO GenAI 提供支持,它不仅仅是一种技术优化,更是、响应迅速的 AI 系统未来发展的前瞻性探索。随着我们不断突破 AI 的可能性,像 OpenVINO 这样的工具将在将潜力转化为现实的过程中发挥关键作用。
立即探索 OpenVINO GenAI API,让您的 AI 项目焕发新生,体验高性能、可扩展性的下一代大语言模型推理。不论是构建实时聊天机器人还是扩展创意AI应用,OpenVINO都将助力您以前所未有的方式实现 高效、可扩展的 AI 推理。






全部评论
留言在赶来的路上...
发表评论