

字节互联
-
发布了文章 2个月前
字节AI大牛屡传离职,背后有何深意
字节AI大牛屡传离职,背后有何深意...
-
发布了文章 2个月前
VideoWorld – 字节联合交大等机构推出的自回归视频生成模型
VideoWorld是北京交通大学、中国科学技术大学和字节跳动合作开展的一项研究项目,探索深度生成模型是否能仅通过未标注的视频数据学习复杂的知识,包括规则、推理和规划能力。...
-
发布了文章 2个月前
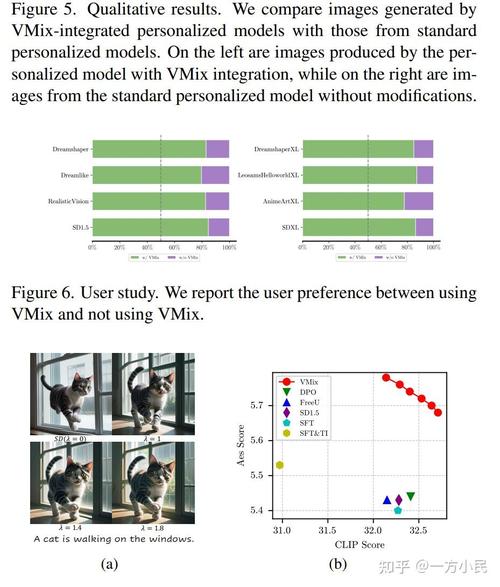
VMix – 字节联合中科大推出增强模型生成美学质量的适配器
VMix是创新的即插即用美学适配器,提升文本到图像扩散模型生成图像的美学质量。通过解耦输入文本提示中的内容描述和美学描述,将细粒度的美学标签(如色彩、光线、构图等)作为额外条件引入生成过程。...
-
发布了文章 2个月前
UniTok – 字节联合港大、华中科技推出的统一视觉分词器
UniTok 是字节跳动联合香港大学和华中科技大学推出的统一视觉分词器,能同时支持视觉生成和理解任务。基于多码本量化技术,将视觉特征分割成多个小块,每块用独立的子码本进行量化,极大地扩展离散分词的表示能力,解决传统分词器在细...
-
发布了文章 2个月前
PhotoDoodle – 字节联合新加坡国立大学等推出的艺术化图像编辑框架
PhotoDoodle是新加坡国立大学、上海交通大学、北京邮电大学、字节跳动和Tiamat团队联合推出的艺术化图像编辑框架,基于少量样本学习艺术家的独特风格,实现照片涂鸦(photo doodling)。PhotoDoodl...

-
发布了文章 2个月前
MMaDA – 字节联合普林斯顿大学等推出的多模态扩散模型
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越...







没有更多内容