

字节vanessa
-
发布了文章 2个月前
字节扣子搭建大模型擂台:匿名PK效果,用户当裁判,跑分时代要结束了
字节扣子搭建大模型擂台:匿名PK效果,用户当裁判,跑分时代要结束了 字节跳动的扣子(coze.cn),给国产大模型们组了个大局——在同一个“擂台”上,两个大模型为一组,直接以...
-
发布了文章 2个月前
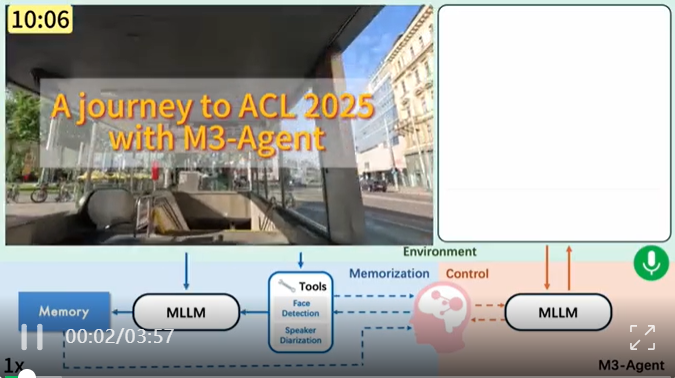
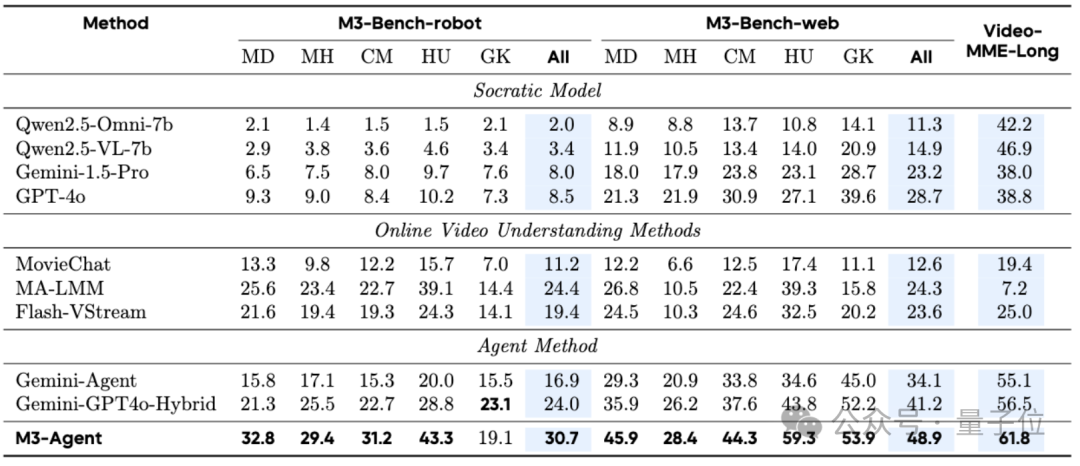
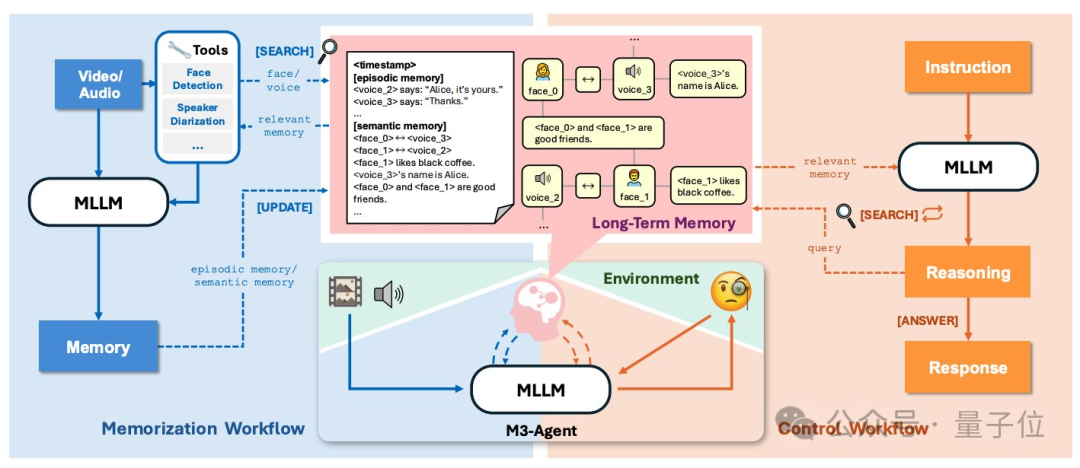
字节Seed开源长线记忆多模态Agent,像人一样能听会看
字节Seed开源长线记忆多模态Agent,像人一样能听会看 字节Seed发布全新多模态智能体框架——M3-Agent。像人类一样能听会看、具备长期记忆,并且免费开源!?...
-
发布了文章 2个月前
字节版Sora火爆24小时,同名论文再次被热议
字节版Sora火爆24小时,同名论文再次被热议 “不需要再等OpenAI的鸽王Sora了”。字节版Sora终于来了,这一次还憋了个大的——一口气推出...
-
发布了文章 2个月前
X-baidu09Dancer – 字节等机构推出音乐驱动的人像舞蹈视频生成框架
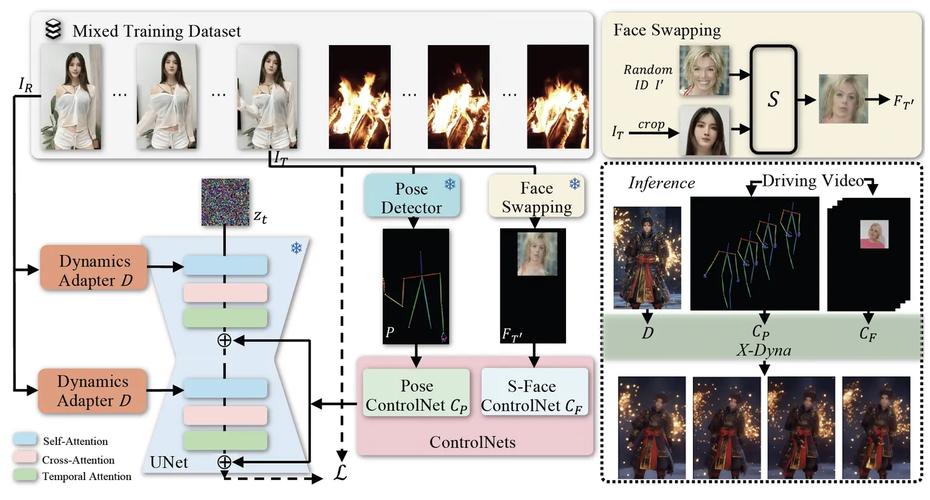
X-Dancer 是字节跳动联合加州大学圣地亚哥分校和南加州大学的研究人员共同推出的音乐驱动的人像舞蹈视频生成框架,支持从单张静态图像生成多样化且逼真的全身舞蹈视频。X-Dancer结合自回归变换器(Transformer)...
-
发布了文章 2个月前
VideoWorld – 字节联合交大等机构推出的自回归视频生成模型
VideoWorld是北京交通大学、中国科学技术大学和字节跳动合作开展的一项研究项目,探索深度生成模型是否能仅通过未标注的视频数据学习复杂的知识,包括规则、推理和规划能力。...
-
发布了文章 2个月前
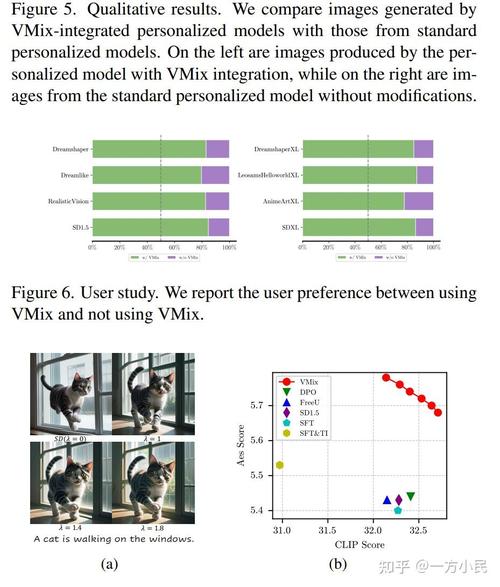
VMix – 字节联合中科大推出增强模型生成美学质量的适配器
VMix是创新的即插即用美学适配器,提升文本到图像扩散模型生成图像的美学质量。通过解耦输入文本提示中的内容描述和美学描述,将细粒度的美学标签(如色彩、光线、构图等)作为额外条件引入生成过程。...
-
发布了文章 2个月前
MARS – 字节推出优化大模型训练效率的框架
MARS(Make vAriance Reduction Shine)是字节跳动推出的创新的优化框架,提升大型模型训练的效率。MARS融合预条件梯度方法与方差减少技术,基于缩放随机递归动量技术优化梯度估计。MARS框架灵活,...
-
发布了文章 2个月前
LiveCC – 字节联合新加坡国立大学开源的实时视频解说模型
LiveCC 是新加坡国立大学Show Lab 团队联合字节跳动推出的实时视频解说模型,基于自动语音识别(ASR)字幕进行大规模训练。LiveCC像专业解说员一样快速分析视频内容,同步生成自然流畅的语音或文字解说。...
-
发布了文章 2个月前
DanceGRPO – 字节Seed联合港大推出的统一视觉生成强化学习框架
DanceGRPO 是字节跳动 Seed 和香港大学联合推出的首个统一视觉生成强化学习框架。将强化学习应用在视觉生成领域,覆盖两大生成范式(diffusion 和 rectified flow)、三项任务(文本到图像、文本到...
















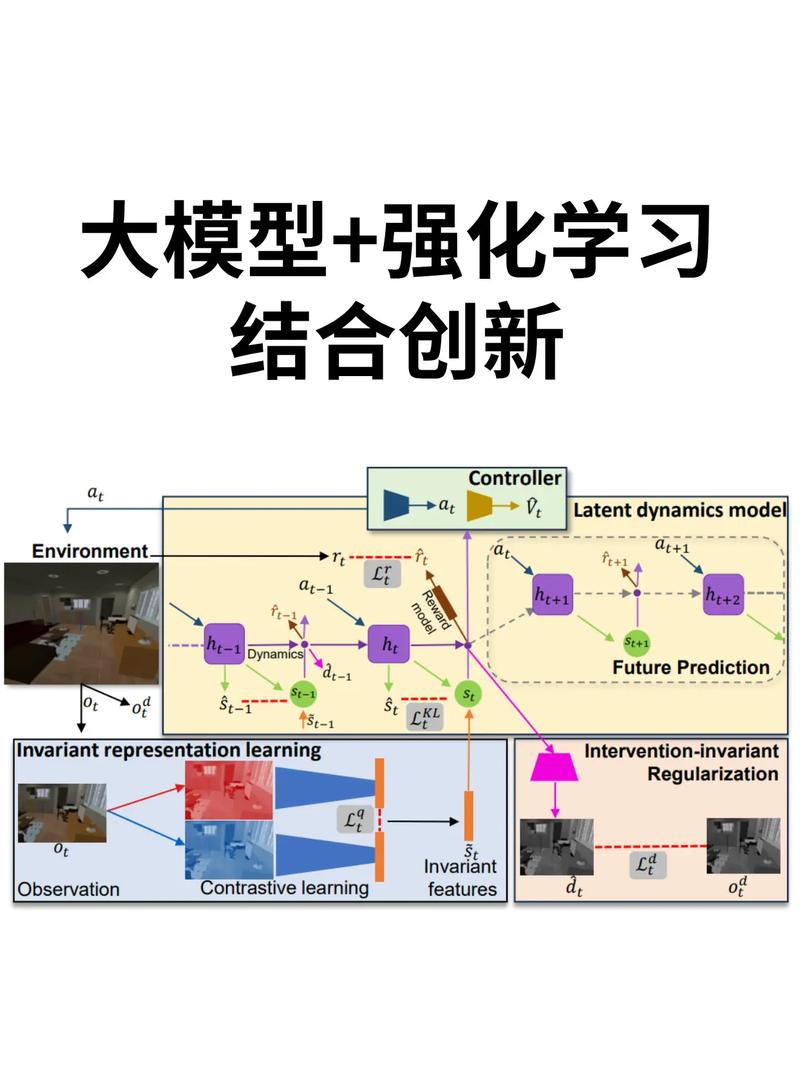
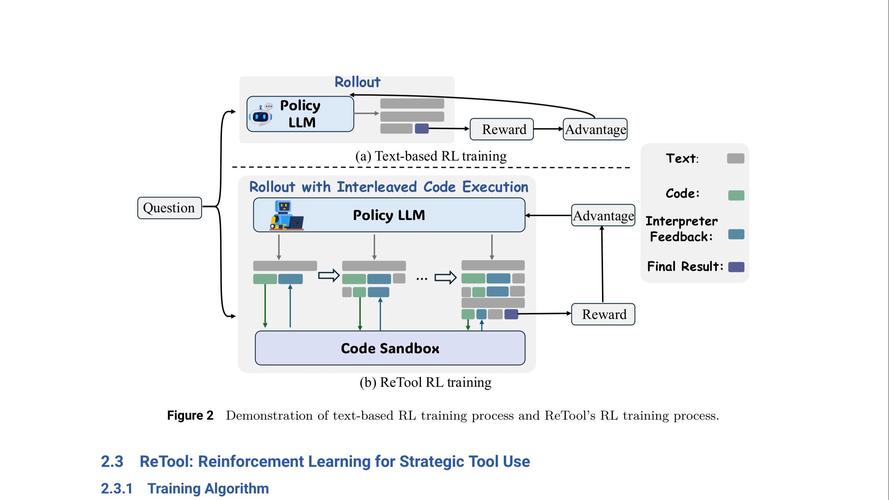
没有更多内容