

拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。AI输出“偏见”,人类能否信任它的“三观”?机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。AI输出“偏见”,人类能否信任它的“三观”?资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
()已成为我们不可分割的“伙伴”。从聊天、语音助手到自动翻译,AI不断介入人与人之间的交流和理解。然而,它能做到“客观中立”吗?
据美国《麻省理工科技评论》官网报道,一项国际研究指出,大语言模型(LLM)正悄无声息地传播全球各地的刻板印象。从性别歧视、文化偏见,到语言不平等,AI正在把人类的“偏见行李”打包、升级,并以看似权威的方式输出到世界各地。

这不禁让人深思:如果AI模型承载的是带有偏见的“人类共识”,我们能否信任它们的“世界观”?
AI让偏见“跨文化漂移”

这项研究由开源AI公司Hugging Face首席伦理科学家玛格丽特·米切尔领导。他们发起了名为SHADES的项目,收录了300多条全球刻板印象,涵盖性别、年龄、国籍等多个维度。研究人员使用16种语言设计交互式提示,并测试了数种主流语言模型对这些偏见的反应。
结果显示,AI模型对刻板印象的再现具有明显差异化特征。这些AI模型不仅表现出“金发女郎不聪明”“是男性”等常见英语地区刻板印象,在阿拉伯语、西班牙语、印地语等语言环境中,也表现出对“女性更喜爱粉色”“南亚人保守”“拉美人狡猾”等偏见。
据Rest of World网站报道,一些图像生成模型在输入“非洲村庄”关键词时,频繁输出“茅草屋”“赤脚孩童”等刻板印象图像,而在输入“欧洲科学家”时,则清一色为白人男性、穿白大褂、身处实验室。这些视觉偏见已被部分学校课件、初创企业官网不加甄别地直接采用,进一步固化了对他者文化的单一想象。
西班牙《世界报》6月刊文指出,除了放大不同文化的刻板印象外,语言模型有时还会用伪科学或伪历史来为自己辩护。在面对不太常见的刻板印象时,模型往往会调动它“更熟悉”的其他偏见进行回应,反而偏离主题。此外,当关于刻板印象的提示是正面的时,模型的表现往往更差,更容易将偏见误当作客观事实表达出来。
“这意味着,AI不仅被动继承了人类偏见,更无意中推动了‘文化漂移’,将特定社会背景下的偏见当作普遍规则输出。”米切尔表示。
小语种群体受到隐形歧视
除了刻板印象的跨文化传播,AI系统在处理不同语言和文化时还暴露出“隐形歧视”的问题。
据报道,美国斯坦福大学“以人为本”AI研究所的研究表明,尽管这些模型声称支持多语言,但在面对低资源语言(如斯瓦希里语、菲律宾语、马拉地语等)时,表现却远不及主流高资源语言,甚至容易产生负面刻板印象。
研究分析了多语言模型在训练数据匮乏、文化语境缺失等方面的局限性,称其存在“多语言性诅咒”现象,即模型在兼顾多语言时,难以深入理解和准确表达低资源语言的文化和语义细节,导致输出错误或带有偏见。
斯坦福大学团队强调,当前大多数训练数据以英语和西方文化为核心,缺乏对非主流语言及其文化背景的深入理解。这不仅影响模型的准确性,也在无形中强化了语言和文化的不平等,使得使用这些低资源语言的人群难以公平受益于。
“目前全球约有7000种语言,但只有不到5%在互联网中得到有效代表。”研究人员表示,“‘资源匮乏’不仅仅是一个数据问题,而是一种根植于社会的问题。”这意味着,AI研发在数据、人才、资源和权利方面存在结构性不公。
美国《商业内幕》杂志也援引哥伦比亚大学社会学副教授劳拉·尼尔森的观点指出,当前最受欢迎的聊天机器人大多由美国公司开发,训练数据以英语为主,深受西方文化偏见影响。
破解AI的文化偏见难题
面对AI跨文化偏见的现实影响,全球研究机构和企业开始提出系统性的应对路径。
今年4月,斯坦福大学“以人为本”AI研究所在其发布的一份白皮书中建议,应加强对低资源语言与文化的AI投资,特别是建立本地语言语料库,让AI能真正“理解”这些语言背后的语义与文化背景。例如,去年11月,非洲电信公司Orange就与OpenAI和Meta合作,用沃洛夫语、普拉尔语等地区语言训练AI模型,加速提升非洲的数字包容性。
与此同时,模型评估机制也在变得更为精细与开放。Hugging Face团队开发的SHADES数据集,已成为多家公司检测和纠正AI模型文化偏见的重要工具。这套数据帮助团队识别模型在哪些语言和语境中容易自动触发刻板印象,从而优化训练数据和。
在国际政策层面,欧盟《AI法案》要求“高风险”AI系统必须在投放前后进行合规评估,包括对非歧视性与基本权利影响的审查,以及提供必要的透明度与人类监督机制。联合国教科文组织早在2021年发布的《AI伦理建议书》也明确指出,AI系统应“保障文化多样性与包容性”,倡导各国建立法律与制度来确保AI的开发尊重文化差异,并纳入人文维度的衡量。
AI本质上是一面“镜子”,映照并复制着我们输入给它的偏见与价值观。它所呈现的“世界观”并非自主生成,而是由人类赋予。如果人们希望AI真正服务于一个多元化的人类社会,就不能让它仅仅反映单一的声音与文化。
来源:日报

猜你喜欢
-
发布了文章 2周前
失败 AI 产品列表
失败 AI 产品列表简单分享一份下线 AI 产品的信息列表(AI Graveyard),里面囊括的产品小类非常多。...
-
发布了文章 1个月前
白读白度拜读baidu09智联招聘带来AI招聘助手艾琳“Ailin”,接入DeepSeek
为了更好地满足企业和求职者的需求,智联招聘已推出了AI招聘助手“Ailin”。Ailin集AI发职位、AI筛简历、AI人才推荐、AI帮聊、AI易面等功能于一体,旨在通过智能化手段优化招聘流程,提升招聘效率和质量。另外,官方宣...

-
发布了文章 2个月前
Salesforce AI Research 刘志伟:像Agent一样思考 - Agent Insights
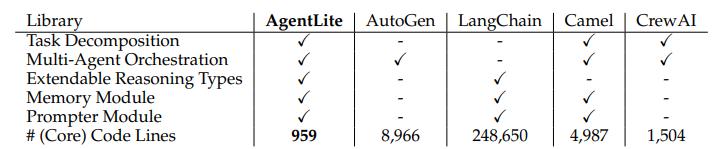
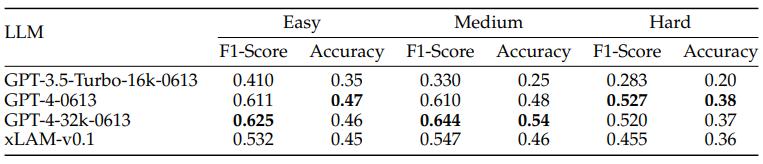
Salesforce AI Research 刘志伟:像Agent一样思考 | Agent Insights 一套针对 Agent 的标准协议,可以减少开发者的很多重复劳动。AgentLite 便是其中一个起点,专注从...
-
发布了文章 2个月前
谷歌生成式AI终于支持文章总结了
...

-
发布了文章 2个月前
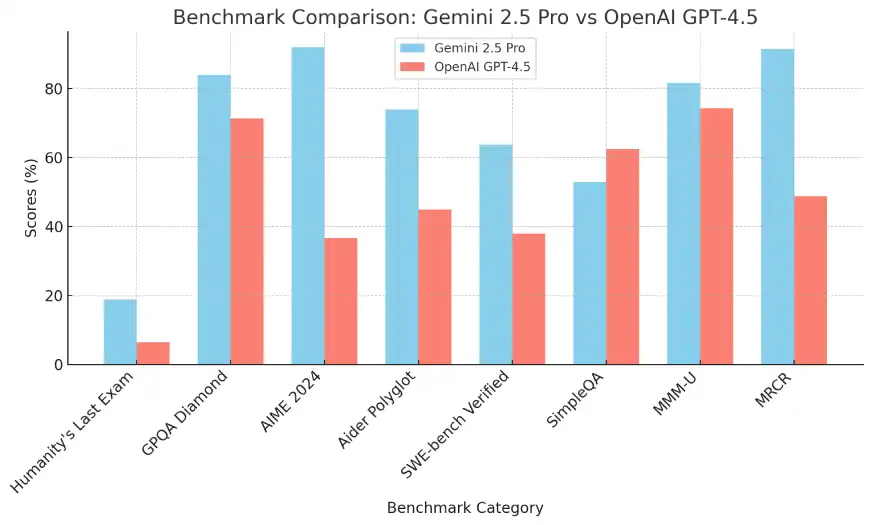
谷歌最新AI模型Gemini 2.5 Pro能否打败GPT 4.5?
...
-
发布了文章 2个月前
谷歌携Codey和Studio Bot杀入AI代码助手战场
...
-
发布了文章 2个月前
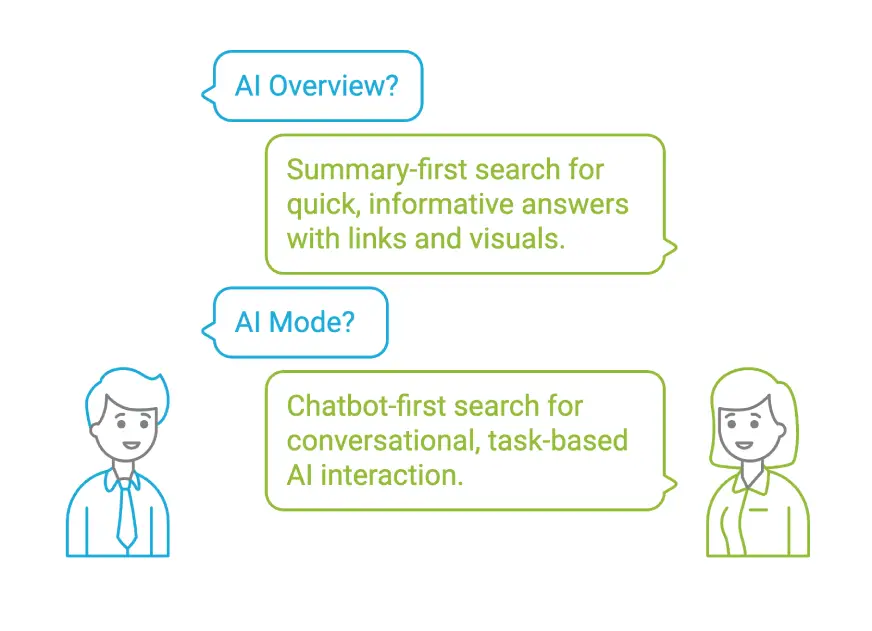
谷歌搜索的两项新AI功能:AI概览和AI模式
...
-
发布了文章 2个月前
谷歌将生成式AI带进搜索领域
...






全部评论
留言在赶来的路上...
发表评论