

拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。AI的“随机性”挑战:它们比人类更“不随机”?机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。AI的“随机性”挑战:它们比人类更“不随机”?资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
你有没有想过,人类真的能做出完全随机的选择吗?答案可能出乎你的意料。事实上,人类天生就不擅长“随机”,我们总能在看似无序的事物中发现规律,甚至在本该随机的场景中创造出模式。这种“伪随机”行为,其实是一种独特的人类特质。最近,来自康奈尔大学探讨了大语言模型(LLMs)在随机性方面的表现。他们通过一个经典的实验——生成二进制随机序列,来观察这些模型是否能像人类一样“不随机”,或者是否能真正实现“随机”。

研究结果令人惊讶。研究者发现,GPT-4和Llama-3在生成随机序列时,不仅表现出人类的偏差,甚至还加剧了这些偏差。
真随机 与 伪随机

人类有一种奇妙的天赋——发现规律。我们总能在生活中找到各种模式:在咖啡的奶泡中看到人脸,在星空里描绘出星座,甚至因为忘记穿幸运衫而觉得勒布朗·詹姆斯投篮不中是自己的错。
然而,这种对规律的敏感也让我们在面对“随机性”时变得格外笨拙。比如,当你让一个人随机选择一个1到10之间的数字时,他们大概率会选择7;或者让他们在脑海中抛硬币,结果多半是正面。这些看似随机的选择,其实背后隐藏着可预测的规律。
抛硬币实验背后的秘密
从20世纪初开始,人类对随机性的研究就从未停止。早在1913年,Fernberger就指出,人类生成随机序列的行为是一个复杂而迷人的课题。此后,无数研究发现,人类生成的随机序列与真正的随机序列有着显著的差异。
我们通过一个经典的行为科学实验来研究这一问题:让人类或机器生成一系列随机结果,比如抛硬币的序列,然后将这些序列与真正的随机序列进行比较。简单来说,就是看看这些序列与“纯粹的随机性”有多大差距。
虚拟硬币实验
▎温度参数:的“随机性开关”
与人类不同,大语言模型有一个关键参数——温度(mperature)。温度决定了模型输出的多样性:温度越低,输出越一致;温度越高,输出越随机、越多样化。然而,当温度过高(比如超过1.5)时,模型的输出可能会变得混乱,甚至无法从中解析出硬币的正反面。因此,我们的实验温度范围设定在0到1.5之间。
当我们让AI连续抛20次硬币时,结果同样有趣。实验发现,所有模型在序列的第一次抛硬币中都倾向于选择“正面”,这与人类的行为高度一致。无论温度如何变化,这种“正面优先”的倾向始终存在。这不仅揭示了AI在随机性任务中继承了人类的偏差,还表明这些偏差在某些情况下可能被进一步放大。
▎AI的“第一印象”偏差
在我们的实验中,超过88%的AI生成的硬币序列以“正面”开始,这一比例远远高于人类数据。这表明AI在“第一印象”上继承了人类的偏差,并且表现得更加明显。尤其是Llama-3,它的偏差比GPT系列模型更强。GPT-4和GPT-3.5之间也存在差异,GPT-4通常表现出更少的偏差。
这种“第一印象”偏差不仅出现在硬币的正反面选择中,还出现在其他二元选择中,比如“真/假”或“A/B”。这可能暗示了语言中的“固定二元组”对AI的决策产生了影响。
▎AI的“平衡”偏差
在实验中,GPT-4和Llama-3生成的序列中,正面和反面的比例往往比随机分布更接近50%,甚至比人类生成的序列还要“平衡”。例如,在8次抛硬币的序列中,它们平均会有4次正面,这与人类的行为非常相似。不过,Llama-3在低温时表现出轻微的正面偏好,而GPT-3.5在低温时则表现出强烈的反面偏好,但在高温时会逐渐接近人类的分布。
▎连续序列与N-g模式人类在生成随机序列时,往往会过度切换正面和反面,认为这样看起来更“随机”。研究表明,人类序列的交替比例通常为60%,而真正的随机序列应该是50%。在AI实验中,这种“过度切换”的倾向被进一步放大。例如,在8次抛硬币的序列中,理论上应该平均有3.5次交替,但AI模型的交替次数普遍高于这个值。GPT-4在低温时几乎总是生成“正反交替”的序列,而Llama-3则倾向于生成“正反正反……”或“正反正正……”的模式。
本文转自:Coggle数据科学

猜你喜欢
-
发布了文章 2周前
失败 AI 产品列表
失败 AI 产品列表简单分享一份下线 AI 产品的信息列表(AI Graveyard),里面囊括的产品小类非常多。...
-
发布了文章 1个月前
白读白度拜读baidu09智联招聘带来AI招聘助手艾琳“Ailin”,接入DeepSeek
为了更好地满足企业和求职者的需求,智联招聘已推出了AI招聘助手“Ailin”。Ailin集AI发职位、AI筛简历、AI人才推荐、AI帮聊、AI易面等功能于一体,旨在通过智能化手段优化招聘流程,提升招聘效率和质量。另外,官方宣...

-
发布了文章 2个月前
Salesforce AI Research 刘志伟:像Agent一样思考 - Agent Insights
Salesforce AI Research 刘志伟:像Agent一样思考 | Agent Insights 一套针对 Agent 的标准协议,可以减少开发者的很多重复劳动。AgentLite 便是其中一个起点,专注从...
-
发布了文章 2个月前
特斯拉亏损扩大面临多重挑战
...
-
发布了文章 2个月前
大从新掌门人应对重生挑战 排放门事件推动改革
...
-
发布了文章 2个月前
谷歌生成式AI终于支持文章总结了
...

-
发布了文章 2个月前
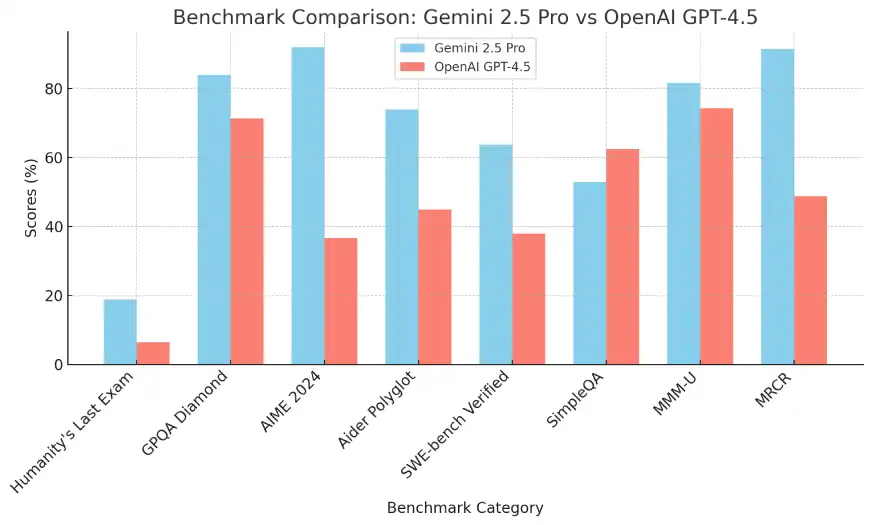
谷歌最新AI模型Gemini 2.5 Pro能否打败GPT 4.5?
...
-
发布了文章 2个月前
谷歌携Codey和Studio Bot杀入AI代码助手战场
...





全部评论
留言在赶来的路上...
发表评论