

拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。2024年AI开发者中间件工具生态全面总结机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。2024年AI开发者中间件工具生态全面总结资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
最近,开源中国 OSCHINA、Gie 与 Gitee 联合发布了《2024 中国开源报告》。 报告聚焦 AI 大模型领域,对过去一年的技术演进动态、技术趋势、以及开源开发者生态数据进行多方位的总结和梳理。
在第二章《TOP 101-2024 大模型观点》中,生成式 AI 开发者莫尔索总结了 2024 年 AI 开发者中间件工具生态。

全文如下:

AI 开发者中间件工具生态 2024 年总结
文 / 莫尔索 AI 应用开发者工具自下而上涵盖了模型托管与推理服务、代理工作流编排、大型模型应用的监控与追踪、模型输出的可控性以及安全工具等多个层面。模型是 AI 应用的核心组成部分,其服务需依赖推理引擎实现。开发者接入模型的方式大致可分为四类:
首先是以模型初创企业为代表,提供先进的商业闭源模型,如 OpenAI、Anthroc、智谱及 MiniMax 等。
其次是由 TogetherAI、Groq、Fireworks、Replicate、硅基流动等组成的 推理集群服务提供商,它们处理扩展与缩减等技术难题,并在基本计算费用基础上收取额外费用,从而让应用公司无需承担构建和管理 GPU 推理集群的高昂成本,而是可以直接利用抽象化的 AI 基础设施服务。
第三类是传统的平台,例如的 Amazon Bedrock、阿里云百炼平台、微软的 Azure AI、谷歌 Vertex AI 等,允许应用开发者轻松部署和使用标准化或定制化的 AI 模型,并通过 API 调用这些模型。
最后一类是本地推理,SGLang、vLLM、TensorRT-LLM 在生产级 GPU 服务负载中表现出色,受到许多有本地托管模型需求的应用开发者的欢迎,此外,Ollama 和 LM Studio 也是在个人计算机上运行模型的优选方案。
除模型层面外,应用层面的工具同样在快速发展,工具的进步紧密跟随 AI 应用的发展趋势。自 ChatGPT 发布以来,应用构建方式大致经历了三个阶段。
首先是基于单一提示词模板的聊天助手类应用,此阶段重点关注模型和提示词的安全性以及模型输出的可控性。例如,garak 可用于检测模型幻觉、数据泄露和生成毒性内容等问题;rebuff 则针对提示词注入进行检测;y 框架提供了系统高效的方法,帮助解决应用开发中的提示编写问题;而 LMFormat Enforcer、Guidance 及 Outlines 等项目旨在帮助开发者控制模型输出的结构,以获得高质量的输出。
第二个阶段涉及通过组合一系列提示词和第三方工具或 API 来编排复杂的工作流,这是目前成熟的 AI 应用构建思路之一。值得注意的是,RAG 技术的出现,得益于大语言模型天然适合处理知识密集型任务,RAG 通过从外部记忆源检索相关信息,不仅提高了模型生成的精确性和相关性,还解决了大语言模型在数据隐私保护、实时数据处理和减少幻觉问题等方面的局限。RAG 技术在数据预处理和构建方面的努力,直接影响最终应用的效果。 尤其是在本地数据预处理方面,PDF 内容处理成为一大难点,众多开源项目应运而生,如基于传统 OCR 技术和版面分析的 Unstructured 和 Marker 库,以及结合了多模态大模型识别能力的 ZeroX 和 GPTPDF 库。
此外,还有融合了 OCR 和多模态大模型方案的 PDF-Extrt-API 库。在公开在线数据处理方面,Jina Reer、Crawl4AI 和 Markdowner 等开源项目,能够将网页内容转换成适合大模型处理的上下文,从而利用最新信息提升问题回答的质量。这些项目的共同目标是将原始数据转化为有价值的资产,助力企业大规模部署 AI。 对于结构化数据,如对话历史记录和其他数据源的存储管理同样重要。向量数据库如 Ch、Weaviate、Pinecone、Milvus 等,提供了语义检索和向量存储功能,使得 AI 应用能够利用超出模型上下文限制的数据源。传统数据库 PostgreSQL 现在也支持通过 pgvector 扩展进行向量搜索,基于 PostgreSQL 的公司如 Neon 和 Supabase 为 AI 应用提供了基于嵌入的搜索和存储解决方案。 为了有效管理 AI 应用的复杂工作流程,市场上涌现了 Dify、Wordware、扣子等低代码平台,它们集成了多种大模型,支持外部数据接入、知识库管理和丰富的插件库,通过拖拽式配置帮助初学者快速构建 AI 应用。 同时,在开源生态系统中,LangChAIn、Haystack、Semanc Kernel 等编排框架的出现,使开发者能够构建、定制和测试 Pipeline,确保这些 Pipeline 的组合能够达到特定应用场景的最佳生成效果。 对于 RAG 应用,这是一种由多个环节构成的工作流应用,出现了许多端到端的开源解决方案,如 LlamaIndex 框架,它集成了数据预处理、索引构建、 多样化检索方法等功能,专为大语言模型设计;RAGFlow 是一个基于深度文档理解的开源 RAG 引擎,提供高质量的能力,适用于处理大规模的复杂格式数据;Verba 是向量数据库厂商 Weaviate 开源的一个模块化 RAG 框架,允许开发者根据不同的应用场景灵活定制 RAG 应用的不同环节。
第三个阶段,一些产品团队正探索开发完全由大模型驱动的代理应用。这类代理应用具备从历史记忆中反思、自主规划和使用工具执行特定动作的能力。大语言模型负责选择要调用的工具及其参数,而具体的执行动作则在沙箱环境中进行,以确保安全。 E2B、Modal 等服务提供商正是为了满足这一需求而诞生。代理通过 OpenAI 定义的 JSON 模式调用工具,这使得代理和工具能够在不同的框架中兼容,促进了代理工具生态系统的增长。例如,Composio 是一个支持授权管理的通用工具库,Exa 则提供了一个专门用于网络搜索的工具。随着更多代理应用的构建,工具生态系统将持续扩展,提供更多新功能,如和访问控制。 在代理应用中,记忆管理同样关键。开源项目 Mem0 将记忆分为短期记忆和长期记忆,后者进一步细分为事件记忆、语义记忆和程序记忆,并基于此抽象出一套记忆管理 K。Zep 通过时态知识图谱管理和更新用户信息,跟踪事实变化并提供最新数据线索。MemGPT 借鉴了计算机内存管理机制,虚拟内存,构建了一套记忆管理系统。这些项目使 AI 应用能够记住对话历史,提供更个性化、上下文感知的交互体验,极大地增强了用户的满意度。
此外,代理应用的另一个探索方向是多个代理之间的协同工作。开源社区中出现了许多解决方案,如 CrewAI 和 AutoGen 具备原生的多代理抽象,而 LangGraph 和 Letta 中的代理可以互相调用,良好的多代理系统设计使得跨代理协作变得更加容易实现。 鉴于生成模型本质上是一个概率黑盒,AI 应用作为一个复杂的系统,其在生产环境中的质量评估与监控尤为重要。实际应用中最大的挑战之一就是输出结果的不确定性。 面对这些挑战,需要采用科学的评估方法。LangSmith、Arise、Langfuse、Ragas 和 DeepEval 等项目提供了评估和监控所需的各种指标和工具,帮助开发者量化测量、监控和调试他们的 AI 应用系统。 展望未来,o1 模型的发布标志着大模型研究进入了新的时代。o1 模型的推理能力提升对 AI 基础设施提出了更高的要求,例如并行计算部分思维链路、减少不必要的思维过程等。研究的重点重新回到了层面,而非简单的算力堆砌,这对于中小型模型开发公司和学术界而言是一大利好。o1 模型的更强推理能力推动了越来越多真正的 autopilot 类产品进入⽇常生活,预示着 AI 技术将更加深入地融入人类社会的方方面面。

猜你喜欢
-
发布了文章 2周前
失败 AI 产品列表
失败 AI 产品列表简单分享一份下线 AI 产品的信息列表(AI Graveyard),里面囊括的产品小类非常多。...
-
发布了文章 1个月前
白读白度拜读baidu09更快速度,2024 FE电动方程式回归中国
2014年9月,电动方程式历史上的第一场比赛在北京的街道上举行。从那时起,经历了不停更迭,现在推出的GEN3赛车是电动方程式有史以来最快、最轻、动力最强大、最高效的赛车。这款新一代赛车的动力增加了75%,最高时速比之前的车型...

-
发布了文章 1个月前
白读白度拜读baidu09智联招聘带来AI招聘助手艾琳“Ailin”,接入DeepSeek
为了更好地满足企业和求职者的需求,智联招聘已推出了AI招聘助手“Ailin”。Ailin集AI发职位、AI筛简历、AI人才推荐、AI帮聊、AI易面等功能于一体,旨在通过智能化手段优化招聘流程,提升招聘效率和质量。另外,官方宣...

-
发布了文章 2个月前
2024天津车展:全新哈弗H9硬派SUV亮相,售价区间为19.99-22.99万元
2024天津车展:全新哈弗H9硬派SUV亮相,售价区间为19.99-22.99万元在9月29日揭幕的2024天津车展上,长城汽车旗下全新哈弗H9正式亮相,吸引了众多消费者的目光。这款新车已于9月25日上市,共推出3款车型,售...
-
发布了文章 2个月前
2024即将结束,中国AI应用支棱起来了吗?这家公司交出95分答卷
2024即将结束,中国AI应用支棱起来了吗?这家公司交出95分答卷 在 AI 生成的这些视频中,你能判断出哪个是 Sora 生成的吗?...
-
发布了文章 2个月前
Salesforce AI Research 刘志伟:像Agent一样思考 - Agent Insights
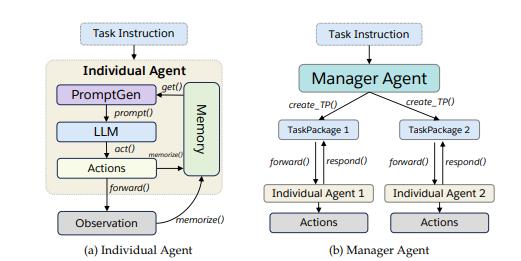
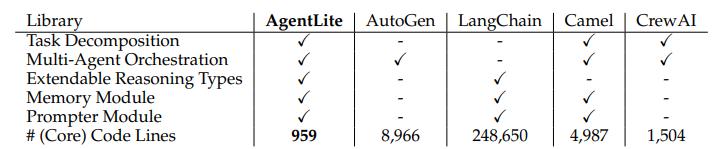
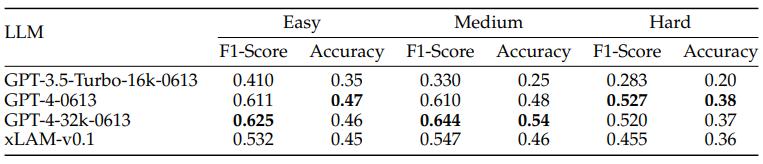
Salesforce AI Research 刘志伟:像Agent一样思考 | Agent Insights 一套针对 Agent 的标准协议,可以减少开发者的很多重复劳动。AgentLite 便是其中一个起点,专注从...
-
发布了文章 2个月前
2024年Automechanika Kuala Lumpur呈现马来西亚汽车市场发展活力,收获与会各方盛赞
...

-
发布了文章 2个月前
2024年Automechanika Frankfurt进一步扩容,重点聚焦汽车产业转型和可持续发展
...











全部评论
留言在赶来的路上...
发表评论