

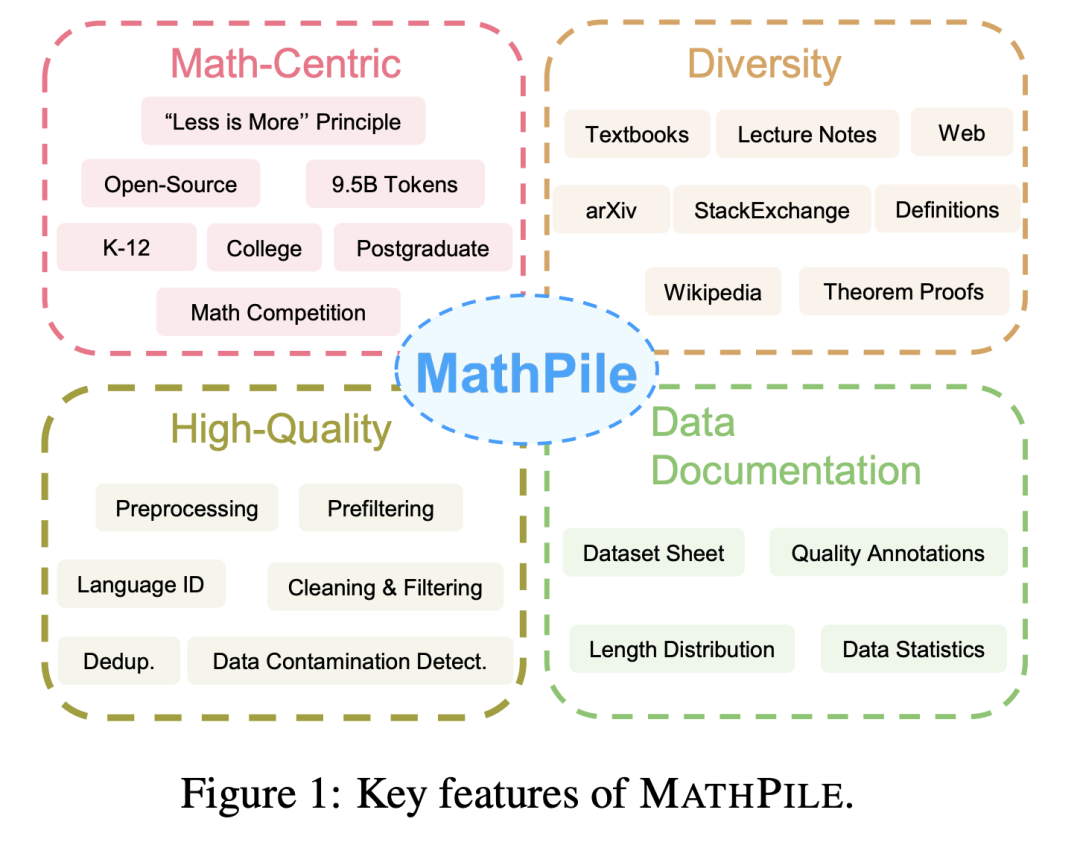
在大模型应用中,如何提升RAG(检索增强生成)的能力?
曾经参与过公司内部的RAG应用,写过一篇关于RAG的技术详情以及有哪些好用的技巧,这次专注于总结一下RAG的提升方法。
还是老样子,深入浅出希望给更多的人进行科普。
什么是RAG?
RAG简单来说就是给予LLM的一些增强
- 引入新的信息,这些信息可能不在LLM中。
- 使用RAG控制内容来减少幻觉(模型生成与现实不符的输出),这是RAG的一个常见用途。通常的用例是提供内容给模型,并指示它仅使用该内容来回答问题,不使用LLM自有的知识,以此限制回答来自特定的知识库,减少幻觉。
的能力? 第1张")
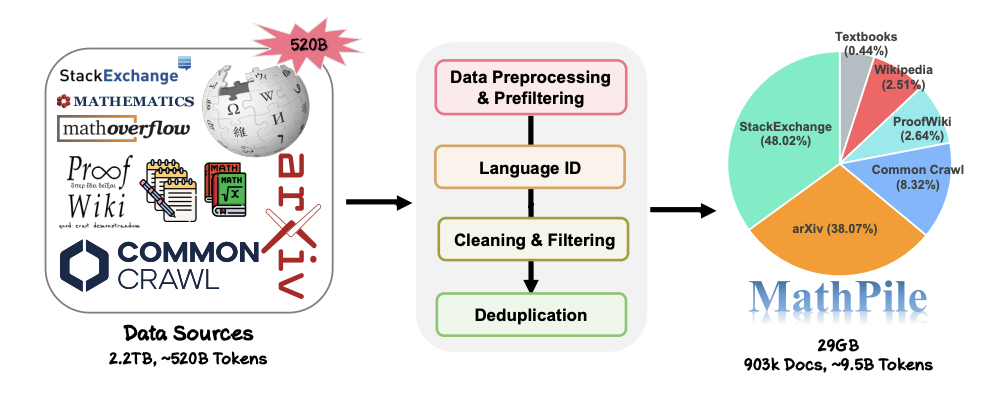
简单来说,RAG主要是由检索和生成两个阶段组成:
- 检索阶段:在检索阶段,算法搜索并检索与用户提示或问题相关的信息片段。向量数据库中查找与Query相关的数据。
- 生成阶段:大模型从增强提示及其训练数据的内部表示中提取信息,以在那一刻为用户量身定制引人入胜的答案。
- 那么,基于RAG的提升方法也是从这两个极端来实现,接下来会用更简单通俗的方法讲解一下RAG存在的痛点和解决方法。
- 检索阶段:痛点和解决方案
的能力? 第2张")
作者:TopGeeky
链接:https://www.zhihu.com/question/643138720/answer/3495870046
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
检索阶段:痛点和解决方案
痛点一:检索质量低
RAG 模型严重依赖于检索到的上下文文档的质量。如果检索器无法找到相关的事实段落,就会严重妨碍模型根据有用信息并产生准确、深入的响应的能力。
特别是现在,稀疏向量检索在语义匹配和检索高质量文档存在困难
解决方案:
- 增强目标域的相关性:通过监督训练信号或模型反馈来微调检索器。
- 采用 DPR 或 ANCE 等模型的密集检索器模型,以获得更高的召回率和相关性。
- 尝试使用多向量表示、近似最近邻搜索和最大内积搜索来不影响准确性的情况下提高检索速度。
- 为了真实性,使用可信度指标检索权威、值得信赖的来源。
痛点二:覆盖范围不足
虽然外部知识对于高质量的 RAG 输出是必不可少的,但即使是最大的语料库也无法完全覆盖用户可能查询的实体和概念。如果无法访问全面的知识源,该模型就会返回对利基或新兴主题的无知、通用的响应。
解决方案:
- 通过集合不同来源的文档来扩展语料库,以增加覆盖的可能性。
- 设计模块化架构以添加/更新知识源,而无需完全重新培训。
- 增加实时检索来覆盖运行时候文档覆盖度
痛点三:情境调节困难
即使具有良好的检索能力,RAG 模型也常常难以正确地调节上下文文档并将外部知识合并到生成的文本中。如果没有有效的情境调节,就无法产生具体的、真实的反应。
解决方案:
- 通过专用的交叉注意力转换器层加强情境化。
- 具有自我监督目标的预训练语言模型,用于训练外部文本。
- 使用更好的情感实体分析方法
痛点四:有效内容划分
对于新增加的文档而言,RAG模型确定所需要检索的内容并用于生成是十分困难的,特别是针对长内容的处理。这就需要针对新增加的信息进行清洗和划分。
解决方案:
- 更好的数据清洗方法,清理文档无效内容和隐私内容
- 调整上下文数据分块大小,较小的块通常可以改善检索,但可能会导致生成过程缺乏周围的上下文
的能力? 第3张")
痛点五:高质量文本排名
在检索源数据时候,需要有效的方法给检索的数据进行排名,找到最想相关的数据才能更好的得到内容。
解决方案:
- 将元数据添加到块中,使用他们来帮助处理结果,包括日期、标记等
- 增加多样性和相关性来进行排序器
- 重新排名是解决相似性和相关性之间差异问题的一种解决方案
的能力? 第4张")
生成阶段: 痛点和解决方案
痛点一:幻觉问题
由于过度依赖语言模型先验,RAG 模型经常生成看似合理但完全错误或不忠实的语句,而没有在检索到的上下文中进行验证。
解决方案:
- 通过训练信号直接最小化产生幻觉文本的可能性。
- 根据与上下文的不匹配自动检测制造。
- 对检索到的文档使用可信度指标,以防止对不可靠来源的限制。
- 通过将优化重点放在上下文基础上来削弱语言模型先验。
痛点二:缺乏可解释性
与传统的 QA 系统不同,RAG 模型无法了解生成文本背后的推理。模型的可解释性仍然是含蓄和不透明的,而不是明确的。
解决方案:
- 设计模型架构,以结构化链/图的形式明确跟踪证据和解释。
- 实施辅助头来预测解释性证据,例如显着数据生成源的内容片段。
- 在每个生成步骤附加有意义的上下文标签以跟踪来源。
- 通过引用内容来源来生成描述推理的自然语言解释。
- 总结查询和上下文之间证明响应合理性的关键语义联系。
的能力? 第5张")
痛点三:推理速度慢
检索与生成的耦合阻碍了 RAG 模型与标准语言模型的延迟匹配。推理管道缺乏对需要毫秒响应的实时应用程序的优化。
解决方案:
- 优化标记化、编码和检索推理,以最大程度地减少生成之前的开销。
- 使用 NMSLIB、FAISS 或 ScaNN 等库采用高效的近似最近邻索引。
- 利用模型并行性和批量检索+生成来提高管道效率。
- 设计模型蒸馏方法,以最小的质量损失压缩检索器-生成器组合。
- 尽可能将检索转移到离线状态,以避免运行时瓶颈。
痛点四:个性化落地难
在通用语料库上训练的 RAG 模型缺乏针对特定用户需求、上下文和查询生成响应的能力。如果没有个人理解,他们无法解决模棱两可的信息请求。
解决方案:
- 设计角色上下文记忆来跟踪对话中的用户配置文件和上下文。
- 在匹配目标用户的标记查询->响应对上微调 RAG 模型。
- 对先前对话和用户反馈进行多任务训练。
- 利用元学习开发少量的个性化技术。
- 构建用户特定的扩展模块来补充检索语料库。
的能力? 第6张")
痛点五:质量评估难
可能的接地响应的多样性使得使用自动化指标可靠地评估 RAG 模型输出的正确性和质量变得具有挑战性。人类评估也缺乏可扩展性。这阻碍了迭代改进。
解决方案:
- 生成带有专家原理的带注释的测试集,以实现标准化评估。
- 根据语义而不是 n 元语法重叠开发专门的指标。
- 通过有针对性的自动评估,分别量化相关性、连贯性、一致性等关键轴。
- 利用用户反馈信号作为个性化质量判断来设计在线学习方案。
- 构建以注释而不是数字分数为中心的交互式评估界面。
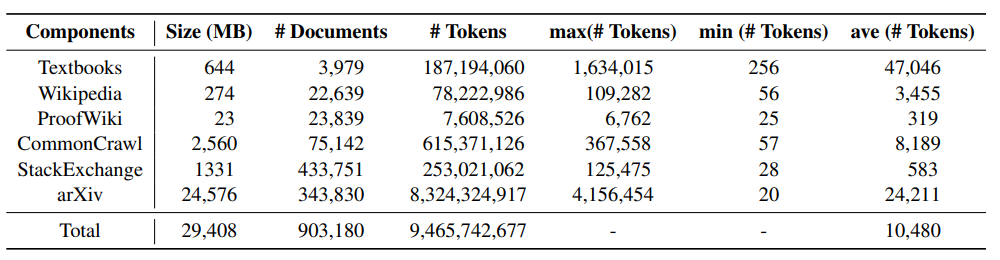
RAG 的评价指标
的能力? 第7张")
在RAG架构中会存在一下评价指标
- 真实性:判断生成内容是否与事实一致
- 答案相关性:答案与提示的相关性
- 上下文精度:检查相关块的排名是否较高。
- 上下文回忆:比较真实情况与上下文,检查是否检索到所有相关信息
- 上下文实体召回:评估检索到的上下文中存在的实体数量与真实值
- 上下文相关性:检索到的上下文与提示的相关性
- 答案语义相似度:生成的答案与实际答案在语义上的相似程度
- 答案正确性:评估生成答案与实际答案的准确性和一致性
总结
RAG 是一种很有前途的提高 LLM 准确性和可靠性的方法,具有事实依据、减少偏见和降低维护成本等优点。虽然未知识别和检索优化等领域仍然存在挑战,但正在进行的研究正在突破 RAG 功能的界限,并为更值得信赖和信息丰富的LLM应用铺平道路。
References:
- Seven Failure Points When Engineering a Retrieval Augmented Generation System
- Top RAG Pain Points and Solutions
- 最具影响力的 RAG 论文
- LongContextReorder
- Output Parsing Modules
- Pydantic Program
- OpenAI JSON Mode vs. Function Calling for Data Extraction
- Parallelizing Ingestion Pipeline
- Query Transformations
- Query Transform Cookbook
- Chain of Table Notebook
- Jerry Liu’s X Post on Chain-of-table
- Mix Self-Consistency Notebook
- Embedded Tables Retriever Pack w/ Unstructured.io
- LlamaIndex Documentation on Neutrino AI
- Neutrino Routers
- Neutrino AI
- OpenRouter Quick Start
文章来自 “知乎‘,作者 “TopGeeky” 重庆大学 软件工程硕士
的能力? 第8张")













全部评论
留言在赶来的路上...
发表评论