

TypedThinker框架,多维度推理Prompt让LLM推理更精准,卡梅隆和Qwen团队最新
大语言模型推理能力的困境
大语言模型(LLMs)在推理任务上展现出了令人瞩目的能力,但其推理思维方式的单一性一直是制约性能提升的关键瓶颈。目前的研究主要关注如何通过思维链(Chain-of-Thought)等方法来提升推理的质量,却忽视了一个重要维度——推理类型的多样性。
当前研究的局限
1.思维多样性不足
- 现有方法如 AlphaCode 主要依赖随机化难度和标签来增加多样性
- 简单提高采样温度虽能产生表面差异,但难以产生高质量的不同解决方案
- 即使生成10万个解答,大多仍局限于演绎推理思维方式
2.推理策略单一
- 大多数方法仅关注如何优化单一推理路径
- 缺乏根据问题特点选择合适推理策略的机制
- 难以模拟人类灵活运用多种推理方式的能力
3.现有增强方法的不足
- Chain-of-Thought 主要关注推理过程的显式表达
- Tree of Thoughts 着重于推理路径的搜索和优化
- Graph of Thoughts 侧重推理步骤间的关系建模
- 这些方法都未充分考虑推理类型的多样性
卡内基梅隆大学和通义千问团队的研究者们提出了一个发人深省的问题:为什么不让 AI 像人类一样,根据问题特点灵活运用不同的推理方式?这一思路催生了 TypedThinker 框架,为大模型注入了多维度的思维能力。

图片由修猫创作

研究动机
1.认知科学启发
- 人类在解决问题时会根据上下文选择合适的逻辑推理策略
- 不同类型的推理反映了不同的思维方式和解决问题的路径
- 推理类型的选择对问题解决效率有重要影响
2.技术可行性
- 大语言模型展现出执行不同推理类型的潜力
- 通过适当的提示和训练可以引导模型进行特定类型的推理
- 已有研究为实现推理类型的动态选择奠定基础
3.应用需求
- 实际应用中面临各种类型的推理问题
- 单一推理方式难以满足多样化的需求
- 灵活运用多种推理类型可以提升模型的实用性
研究亮点:多维度推理的重要性
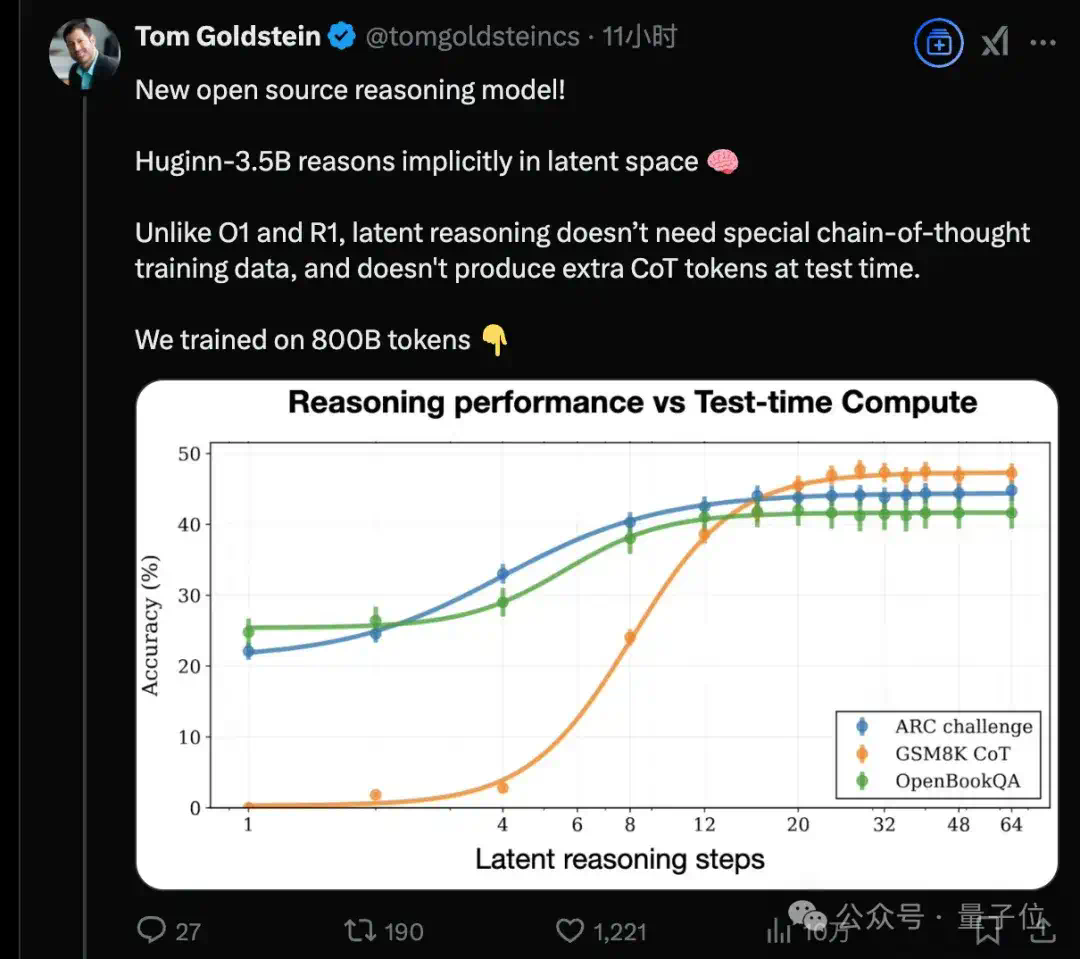
研究团队在四个基准数据集(LogiQA、BBH、GSM8k 和 MATH)上的分析示了一个重要发现:不同类型的推理各有所长,能解决不同类型的问题。
推理类型详解

1.演绎推理(Deductive)
- 定义:从一般规则推导出具体结论
- 特点:逻辑严密,结论可靠
- 适用场景:有明确前提和规则的问题
- 案例:
前提1:所有程序员都懂编程
前提2:小明是程序员
结论:小明懂编程
- 优势:推理过程清晰,结论可靠
- 局限:需要完整的前提条件
2.归纳推理(Inductive)
- 定义:从具体观察总结出普遍规律
- 特点:基于经验归纳,结论具有概率性
- 适用场景:需要从数据中发现规律的问题
- 案例:
观察1:1+3=4
观察2:2+3=5
观察3:4+3=7
规律:任意数加3,结果比原数大3
- 优势:能发现潜在规律
- 局限:结论可能存在不确定性
3.溯因推理(Abductive)
- 定义:通过验证假设来寻找最佳解释
- 特点:从结果推测原因,具有创造性
- 适用场景:需要解释现象或验证猜想的问题
- 案例:
现象:地面是湿的
可能原因1:下雨了(最可能)
可能原因2:有人浇水
可能原因3:水管破裂
- 优势:能处理不完整信息
- 局限:需要验证多个假设
4.类比推理(Analogical)
- 定义:基于相似性进行推理
- 特点:利用已知问题的解决方案
- 适用场景:可以找到相似参考案例的问题
- 案例:
已知:太阳系中地球绕太阳运转
类比:其他行星也可能绕太阳运转
验证:观察证实推测正确
- 优势:可以借鉴已有经验
- 局限:依赖相似案例的质量
实验验证
研究团队通过大规模实验证明了推理类型的重要性:
1.数据规模
- 使用4个标准数据集
- 每个数据集包含数千个测试样本
- 覆盖逻辑推理和数学问题两大领域
2.实验设置
- 对每个问题使用不同推理类型各采样10次
- 采样温度设置为1以保证多样性
- 记录每种推理类型的成功率
3.关键发现

不同推理类型的优势互补
- MATH 数据集中11.03%的问题只能通过归纳推理解决
- BBH 数据集中演绎推理和类比推理表现最好
- LogiQA 数据集上各种推理类型表现相近
- GSM8k 数据集上溯因推理特别有效
TypedThinker 框架详解
框架设计
TypedThinker 框架包含三个核心组件,每个组件都经过精心设计以实现特定功能:

1.元思考者(Meta-thinker)
- 使用成功经验作为训练数据
- 采用监督学习优化预测准确率
- 通过自训练持续改进
- 基于预训练语言模型
- 使用特定提示模板引导分析
- 输出每种推理类型的有效性得分(0-1)
- 分析问题特征
- 预测推理类型有效性
- 选择最优推理策略
- 核心功能
- 技术实现
- 训练方法
2.显式记忆库(Explicit Memory)
- 定期加入新的成功经验
- 保持每类推理的样本平衡
- 优先保留高质量解答
- 使用语义相似度匹配
- 设置相似度阈值(δ=0.5)
- 返回 top-k 相关经验
- 按推理类型分类存储
- 每个问题保存最详细的成功解答
- 包含问题、推理过程和答案
- 数据组织
- 检索机制
- 更新策略
3.推理器(Reasoner)
- 使用统一的推理器处理所有类型
- 通过提示词指定推理类型
- 可以组合多种推理类型
- 利用检索到的相关经验
- 通过指令微调提升能力
- 支持多步骤推理
- 执行特定类型推理
- 生成详细推理过程
- 得出最终答案
- 基本功能
- 增强机制
- 实现细节
工作流程
TypedThinker 的完整工作流程包含以下步骤:
1.问题分析
- 提取问题关键信息
- 识别问题类型和特征
- 准备元思考者输入
2.推理类型选择
- 元思考者分析问题
- 预测各推理类型有效性
- 确定最优推理策略
3.经验检索
- 计算问题相似度
- 检索相关成功经验
- 筛选最有价值的参考案例
4.推理执行
- 设置推理类型和参考经验
- 生成详细推理过程
- 得出问题答案
5.结果处理
- 单一推理类型:直接输出结果
- 多推理类型:加权投票决策
- 更新经验库(如果成功)
自训练机制
TypedThinker 采用创新的自训练方式来持续优化性能:
1.数据收集
- 对每个训练样本使用不同推理类型
- 每种类型采样10次
- 记录成功和失败案例
2.效果评估
- 计算每种推理类型的成功率
- 分析失败案例的原因
- 识别最有效的推理策略
3.模型优化
- 使用成功经验训练元思考者
- 微调推理器提升执行能力
- 更新记忆库中的经验
4.质量控制
- 验证推理类型的正确性
- 筛选高质量的解答
- 保持样本的多样性
5.持续改进
- 定期评估系统性能
- 分析改进空间
- 调整优化策略
实验结果与分析
实验设置
1.数据集
- LogiQA:3757训练/500验证/511测试
- BBH:1904训练/320验证/1600测试
- GSM8k:6473训练/1000验证/1319测试
- MATH:6500训练/1000验证/5000测试
2.基线模型
- Few-shot:使用3个示例的少样本学习
- CoT Selection:提示选择最佳推理类型
- Zero-shot MoR:零样本混合推理
- Few-shot MoR:少样本混合推理
3.评估指标
- 准确率:答案完全匹配的比例
- 推理类型预测准确率
- Kendall's τ 相关系数
性能提升
在四个基准数据集上的详细实验结果:

1.Mistral 7B
- LogiQA:准确率从48.5%提升到55.4%
- BBH:准确率从34.6%提升到42.3%
- GSM8k:准确率从36.9%提升到38.6%
- MATH:准确率从7.4%提升到9.2%
- 平均提升:3.4个百分点
2.LLaMA3 8B
- LogiQA:准确率从56.6%提升到55.0%
- BBH:准确率从31.8%提升到53.3%
- GSM8k:准确率从47.2%提升到53.5%
- MATH:准确率从10.5%提升到19.3%
- 平均提升:16.7个百分点
3.泛化性验证
- 在新数据集 Contexthub 上测试
- Mistral 7B 准确率提升3.3%
- LLaMA3 8B 准确率提升2.5%
4.GPT-4提升效果
- LogiQA:76%→81%
- BBH:84%→90%
- GSM8k:97%→96%
- MATH:89%→91%
关键发现
1.推理类型的重要性
a. 独特优势
b. 互补性
c. 适应性
- 不同问题适合不同推理类型
- 灵活选择推理类型很重要
- 错误的推理类型会导致性能下降
- 不同推理类型能力互补
- 组合使用可以提高整体性能
- 避免了单一推理类型的局限
- 每种推理类型都有其特定的优势领域
- MATH 数据集中11.03%问题仅能通过归纳推理解决
- BBH 数据集中演绎推理在某些任务上优势明显
- GSM8k 中溯因推理对解决应用题特别有效
2.元思考者的效果
a. 预测准确性
b. 泛化能力
c. 决策可靠性
- 有效预防不当推理类型的使用
- 准确识别最优推理策略
- 提供可靠的推理类型选择
- 可以处理未见过的问题类型
- 在新数据集上表现良好
- 适应不同难度的任务
- 统一训练后预测准确率显著提升
- 与经验数据相关性达到68.3%
- 在逻辑推理任务上准确率超过75%
3.记忆库的作用
a. 逻辑推理
b. 数学问题
c. 经验积累
- 持续积累有效经验
- 提升推理质量
- 促进知识迁移
- 需要谨慎使用检索到的案例
- 避免数值计算的干扰
- 关注推理思路而非具体计算
- 提供有价值的参考案例
- 帮助理解推理步骤
- 提升推理准确性
案例分析
1.逻辑推理案例
问题:越往高处走,气压越小。因为兰州的海拔比天津高,所以兰州的气压比天津低。
下列哪种推理最相似?
选项:
A. 市场竞争越激烈,产品质量和广告投入越大,产品销量就越大。A公司比B公司投入更多广告费用,
所以A公司的产品销量比B公司大。
B. 人越老越成熟。老张比他儿子大,所以老张比他儿子成熟。
C. 树越老年轮越多。老张家院子里的洋槐树比老李家的年龄大,所以老张家的洋槐树比老李家的年轮多。
D. 一种语言的词汇量越大,学习起来越困难。英语比意大利语难学,所以英语的词汇量比意大利语大。
分析过程:
1. 元思考者分析
- 归纳推理得分:0.5
- 演绎推理得分:0.4
- 类比推理得分:0.4
- 溯因推理得分:0.4
2. 推理执行
使用归纳推理:
- 原问题揭示规律:高度↑ → 气压↓
- 应用规律:兰州高度>天津 → 兰州气压<天津
- 对比选项寻找相似规律:
A:广告投入与销量关系不完整
B:年龄与成熟度关系可能不成立
C:树龄与年轮数量存在必然关系
D:难度与词汇量关系反向推导
3. 结论
选择C,因为树龄与年轮数量的关系最符合原问题中高度与气压的关系特征。
2.数学问题案例
问题:一个正整数m在30到80之间,是6的倍数。当m除以8时余2,
除以5时也余2。求m的值。
分析过程:
1. 元思考者分析
- 溯因推理得分:0.6
- 演绎推理得分:0.3
- 归纳推理得分:0.2
- 类比推理得分:0.1
2. 推理执行
使用溯因推理:
a) 列出可能的m值
- 6的倍数:36、42、48、54、60、66、72、78
b) 验证除以8的余数
- 36÷8=4余4
- 42÷8=5余2 √
- 48÷8=6余0
- ...
c) 对42验证除以5的余数
- 42÷5=8余2 √
3. 结论
m=42满足所有条件
实践启示
对于 Prompt 工程师,TypedThinker 的研究可以在写prompt时注意以下要点:
推理类型的选择
1.问题分析
- 仔细分析问题特征
- 识别可能适用的推理类型
- 考虑问题的复杂度
2.选择策略
- 简单问题优先单一推理
- 复杂问题考虑组合推理
- 动态调整推理策略
3.注意事项
- 避免不当推理类型
- 保持推理过程清晰
- 验证推理结果
提示词设计
1.基础模板
使用[推理类型]来解决问题。
[推理类型]的定义是:[定义]。
示例:[相关案例]
现在请解决:[问题描述]
2.推理类型定义
演绎推理:从一般规则推导出具体结论
归纳推理:从具体观察总结出普遍规律
溯因推理:通过验证假设来寻找最佳解释
类比推理:基于相似性进行推理
3.示例要求
- 与目标问题相关
- 推理过程清晰
- 难度适中
实践建议
1.简单问题处理
- 直接使用单一推理类型
- 保持推理过程简洁
- 注重效率
2.复杂问题处理
- 分解为多个子问题
- 针对性选择推理类型
- 注意推理步骤的连贯性
3.效果优化
- 收集成功案例
- 持续改进提示词
- 建立问题类型库
局限与展望
当前局限
1.复杂问题的处理
- 多步骤推理协调困难
- 推理类型切换不够流畅
- 缺乏整体推理策略
2.推理类型的选择
- 预测准确率有待提高
- 某些问题类型难以判断
- 组合推理策略不够完善
3.记忆库的使用
- 检索效率需要优化
- 经验质量参差不齐
- 泛化能力有限
未来方向
1.技术层面
- 开发新的推理类型
- 改进选择机制
- 优化记忆检索
2.应用层面
- 扩展应用场景
- 提供开发工具
- 简化使用流程
3.理论层面
- 研究推理本质
- 探索可解释性
- 完善评估体系
写在最后
TypedThinker 框架通过引入多维度的推理类型,并结合元思考者和记忆库的创新设计,该框架不仅显著提升了模型性能,也为我们理解和改进 AI 推理能力提供了新的视角。对于 Prompt 工程师而言,这项研究提供了实用的工具和方法,有助于设计更有效的提示策略。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




全部评论
留言在赶来的路上...
发表评论