

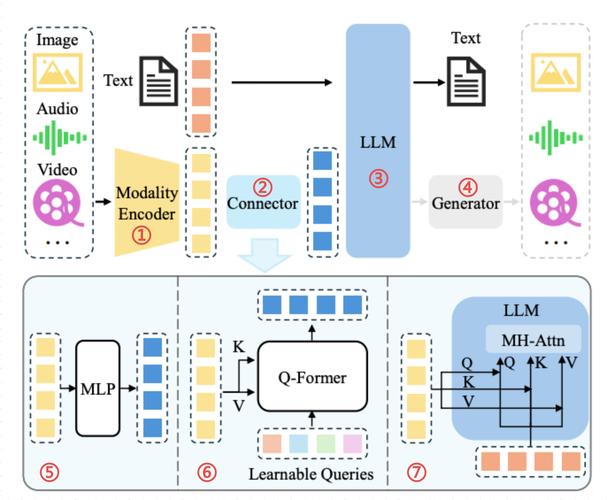
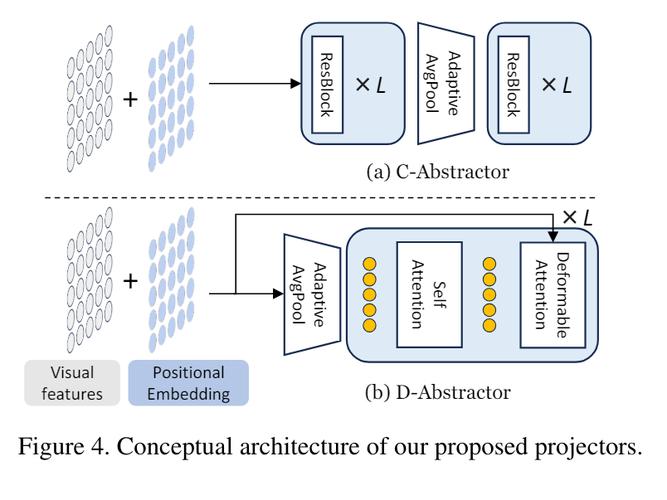
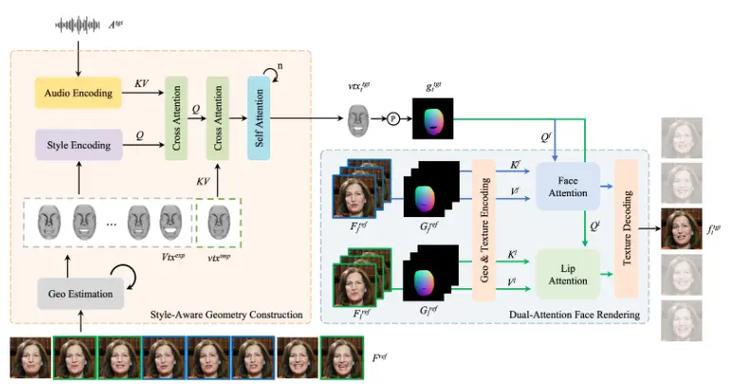
Sa2VA是字节跳动联合加州大学默塞德分校、武汉大学和北京大学共同推出的多模态大语言模型,是SAM2和LLaVA结合而成,能实现对图像和视频的密集、细粒度理解。Sa2VA基于统一的任务表示,将图像或视频指代分割、视觉对话、视觉提示理解等任务整合到一个框架中,用LLM生成的空间-时间提示指导SAM2生成精确分割掩码。Sa2VA采用解耦设计,保留SAM2的感知能力和LLaVA的语言理解能力,引入Ref-SAV数据集,用在提升复杂视频场景下的指代分割性能。

(图片来源网络,侵删)

(图片来源网络,侵删)






全部评论
留言在赶来的路上...
发表评论