

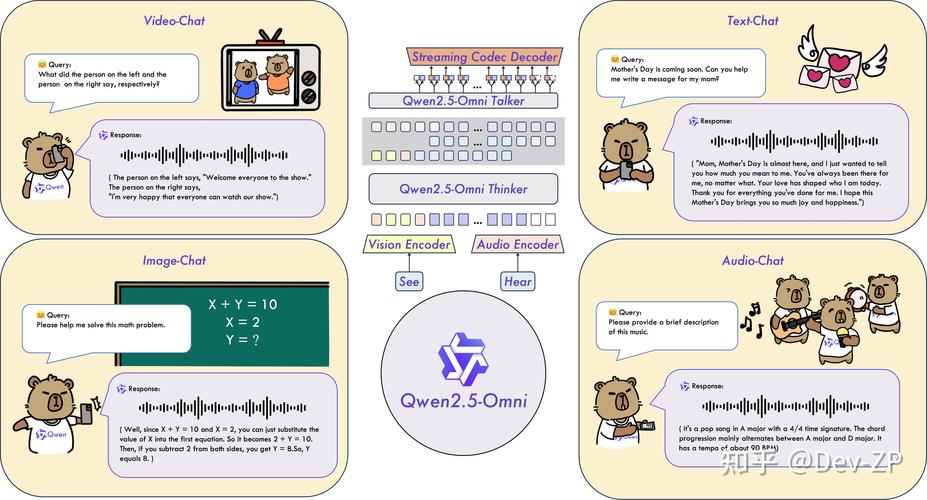
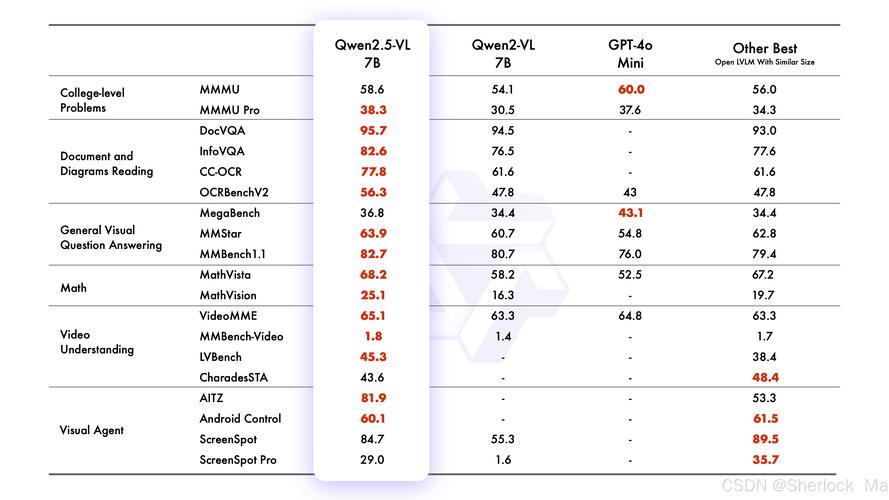
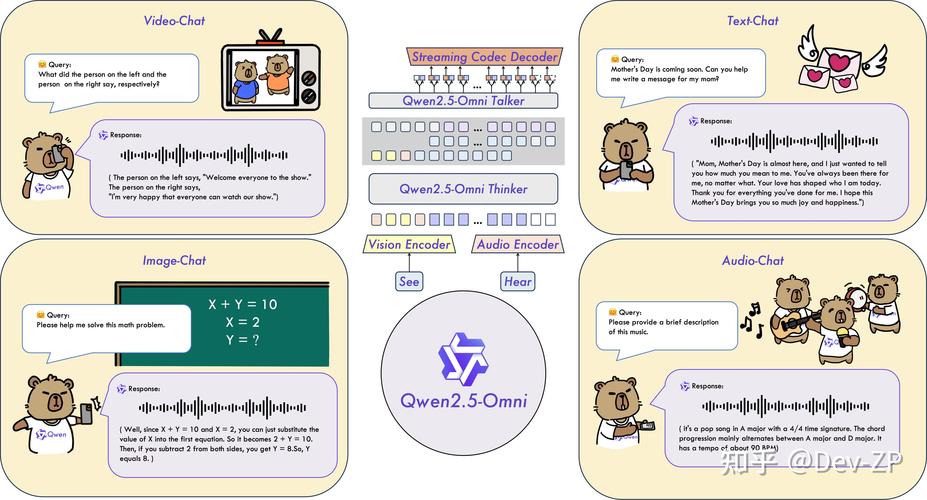
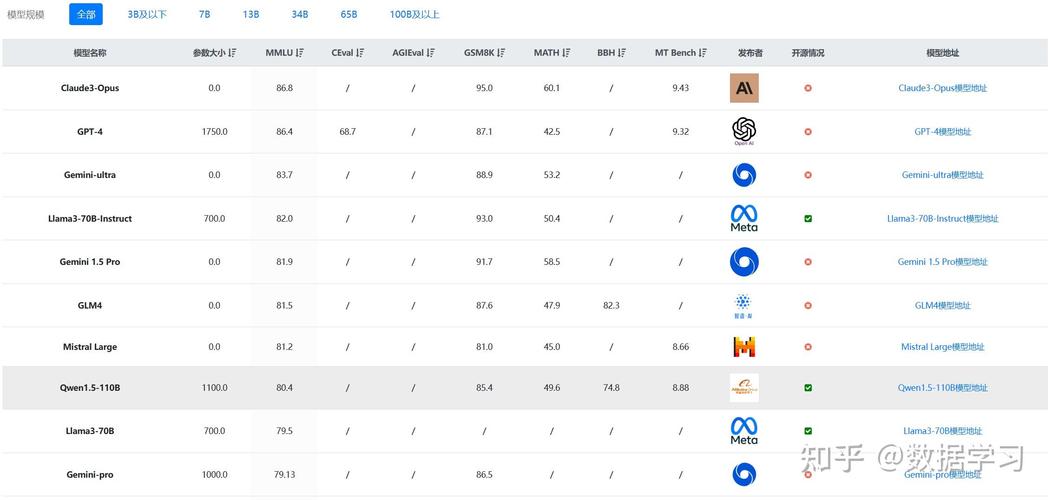
Qwen2.5-VL是阿里通义千问团队开源的旗舰视觉语言模型,具有3B、7B和72B三种不同规模。模型在视觉理解方面表现出色,能识别常见物体,分析图像中的文本、图表等元素。Qwen2.5-VL具备作为视觉Agent的能力,可以推理并动态使用工具,能初步操作电脑和手机。在视频处理上,能理解超过1小时的长视频,精准定位相关片段捕捉事件。模型支持发票、表单等数据的结构化输出。在性能测试中,Qwen2.5-VL-72B-Instruct在多个领域和任务中表现优异,在文档和图表理解方面优势明显。7B模型在多项任务中超越了GPT-4o-mini。

(图片来源网络,侵删)

(图片来源网络,侵删)



全部评论
留言在赶来的路上...
发表评论