

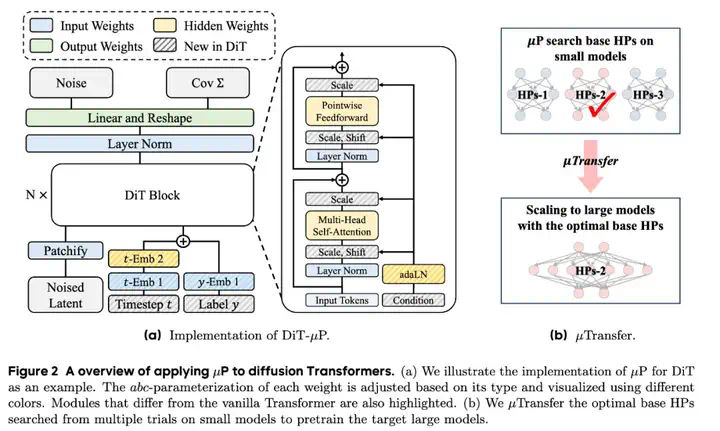
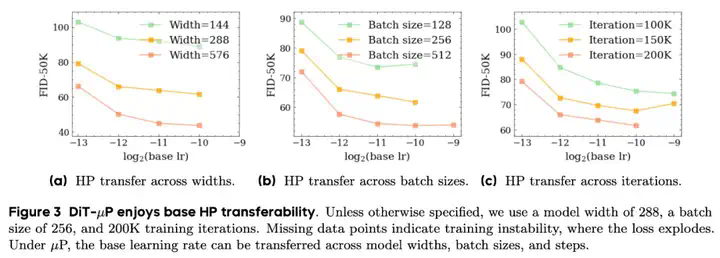
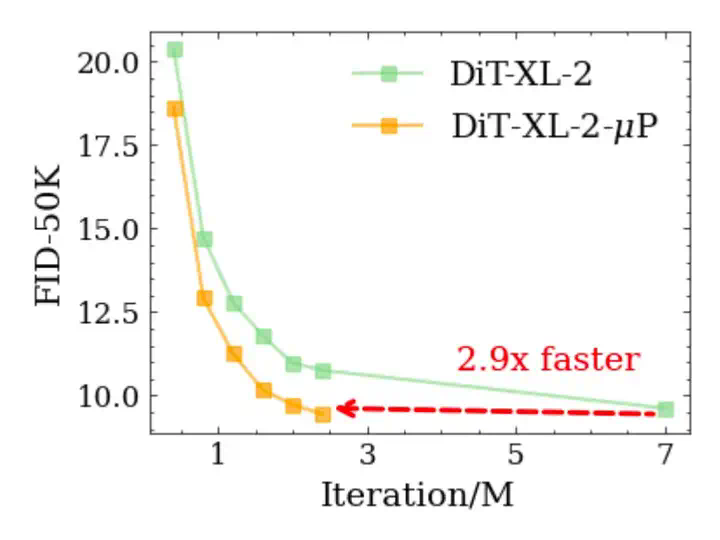
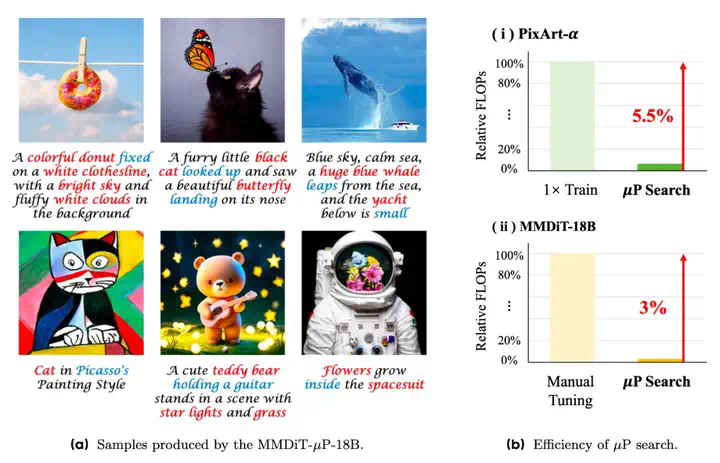
OmniSync是中国人民大学、快手科技和清华大学联合推出的通用框架,基于扩散变换器(Diffusion Transformers)实现视频中人物口型与语音的精准同步。OmniSync基于无掩码训练范式直接编辑视频帧,无需参考帧或显式掩码,支持无限时长推理,同时保持自然的面部动态和身份一致性。OmniSync引入流匹配基础的渐进噪声初始化和动态时空分类器自由引导(DS-CFG)机制,解决音频信号弱的问题,确保精确的口型同步。OmniSync建立AIGC-LipSync基准测试,评估AI生成视频中的口型同步性能。

(图片来源网络,侵删)

(图片来源网络,侵删)









全部评论
留言在赶来的路上...
发表评论