

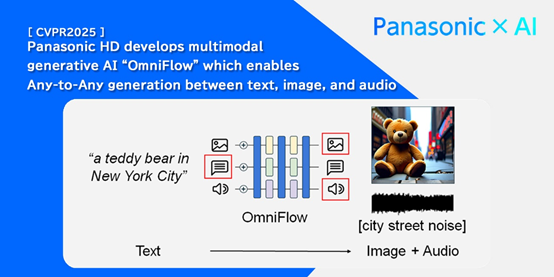
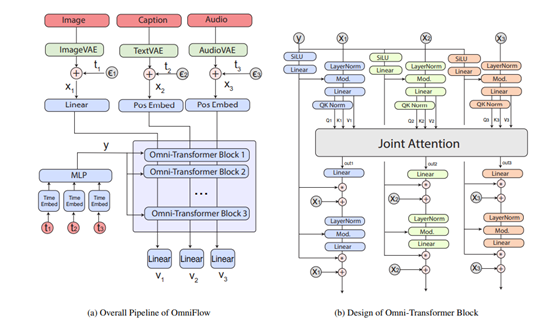
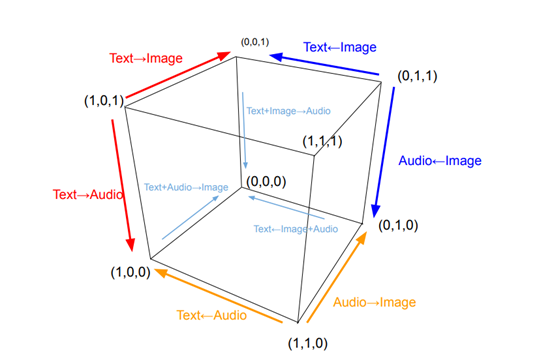
OmniFlow是松下与加州大学洛杉矶分校(UCLA)合作推出的多模态AI模型。模型能实现文本、图像和音频之间的任意到任意(Any-to-Any)生成任务,例如将文本转换为图像或音频,或将音频转换为图像等。OmniFlow扩展现有的图像生成流匹配框架,基于连接和处理三种不同数据特征,学习复杂的数据关系,避免简单平均不同模态数据特征的局限性。模型用模块化设计,支持独立预训练和微调,显著提升训练效率和模型的扩展性。OmniFlow在多模态生成领域展现了强大的性能和灵活性。

(图片来源网络,侵删)

(图片来源网络,侵删)


全部评论
留言在赶来的路上...
发表评论