Omages是一个开源的3D模型生成项目,基于图像扩散技术将3D形状的几何和纹理信息编码进64×64像素的2D图像中,简化3D建模流程。不仅提高了3D对象生成的效率,还能在低分辨率下保留丰富的细节,为3D视觉技术开辟了新的可能性。

(图片来源网络,侵删)

(图片来源网络,侵删)


Omages是一个开源的3D模型生成项目,基于图像扩散技术将3D形状的几何和纹理信息编码进64×64像素的2D图像中,简化3D建模流程。不仅提高了3D对象生成的效率,还能在低分辨率下保留丰富的细节,为3D视觉技术开辟了新的可能性。

这才是真・开源模型!公开「后训练」一切,性能超越Llama 3.1 Instruct 开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 40...






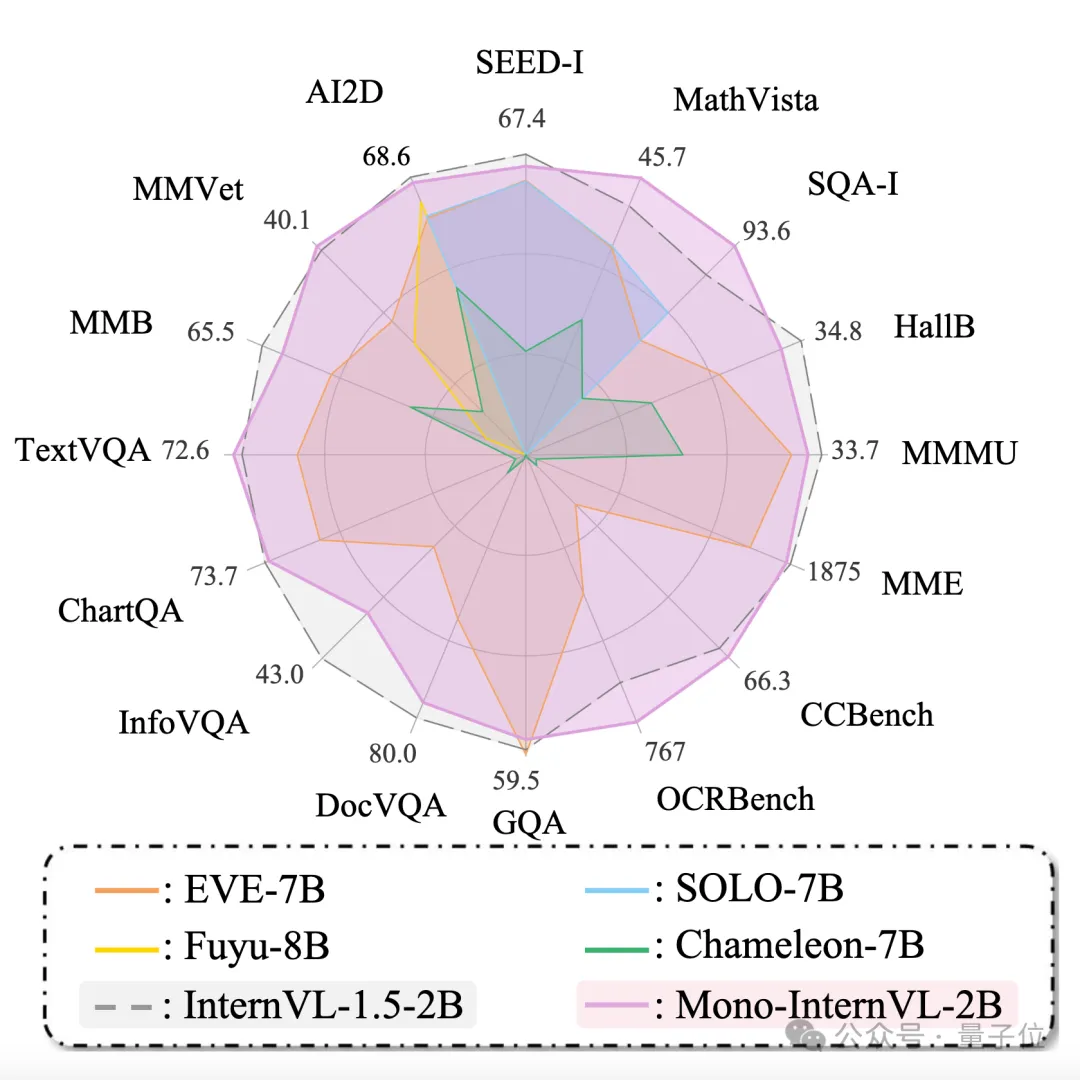
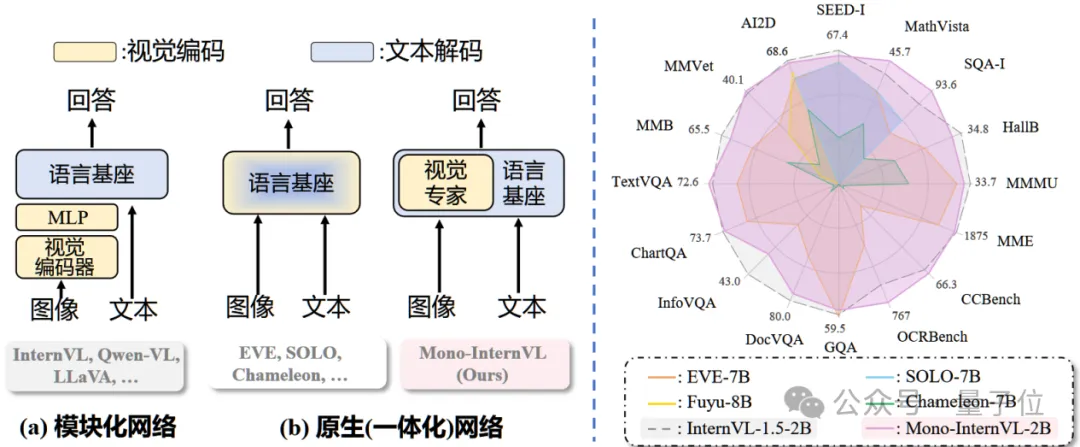
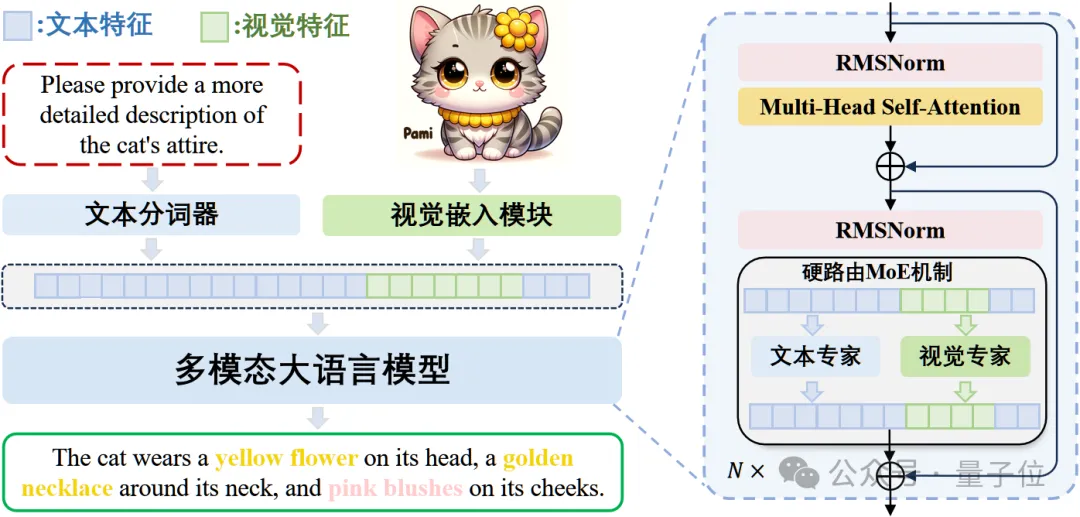
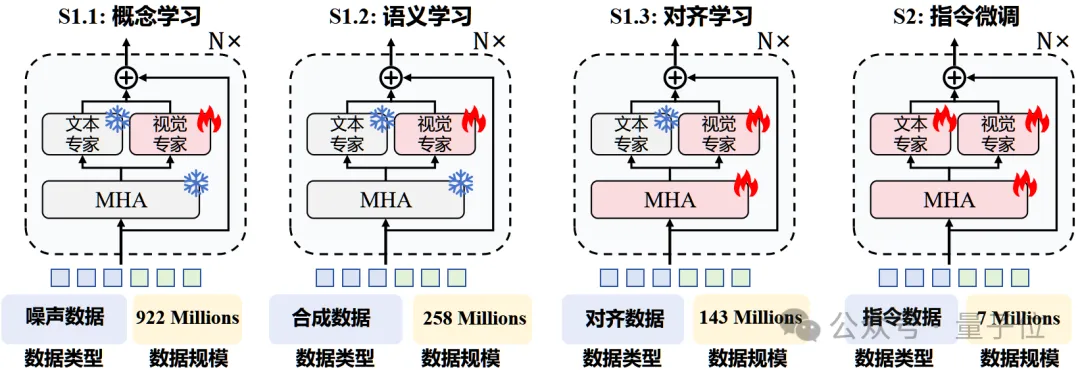
开源模型突破原生多模态大模型性能瓶颈,上海AI Lab代季峰团队出品 原生多模态大模型性能瓶颈,迎来新突破!上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。与非原生模型相比,该模...


开源模型穷途末路?Stability AI欠下1亿美元,四处找钱寻求「卖身」 曾经创造出Stable Diffusion系列模型的Stability AI,目前面临前所未有的财务危机。这个曾经有10亿美元估值,却只有1...

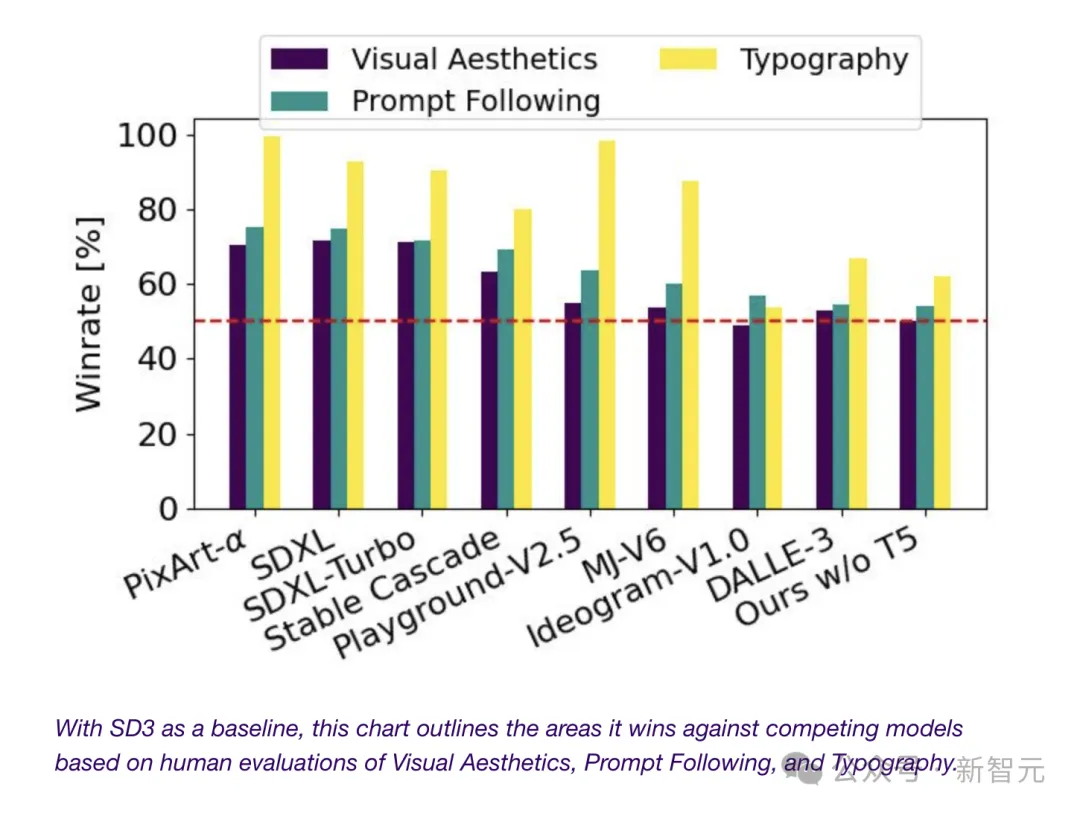



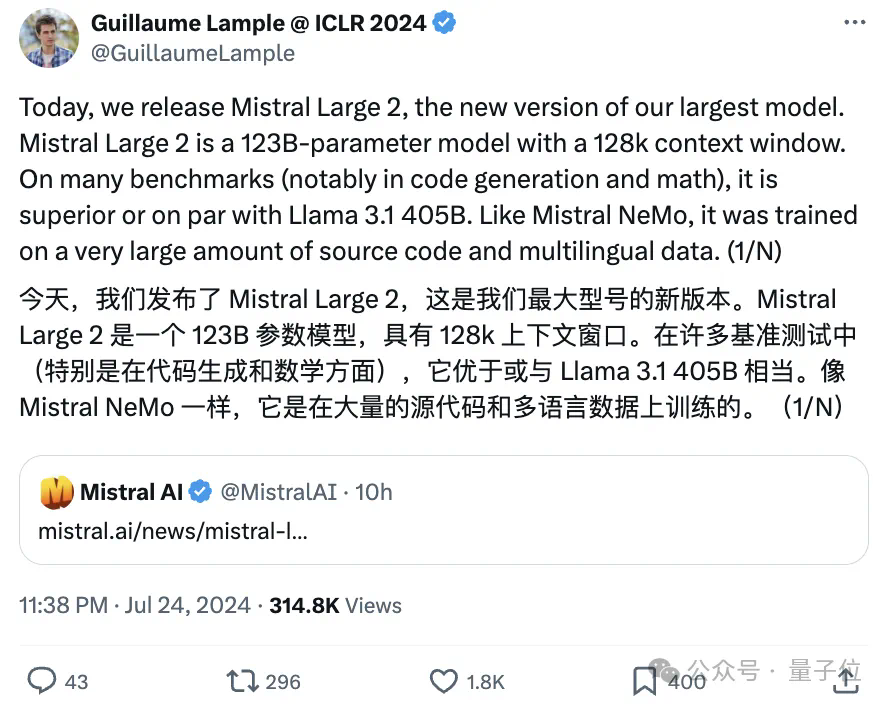
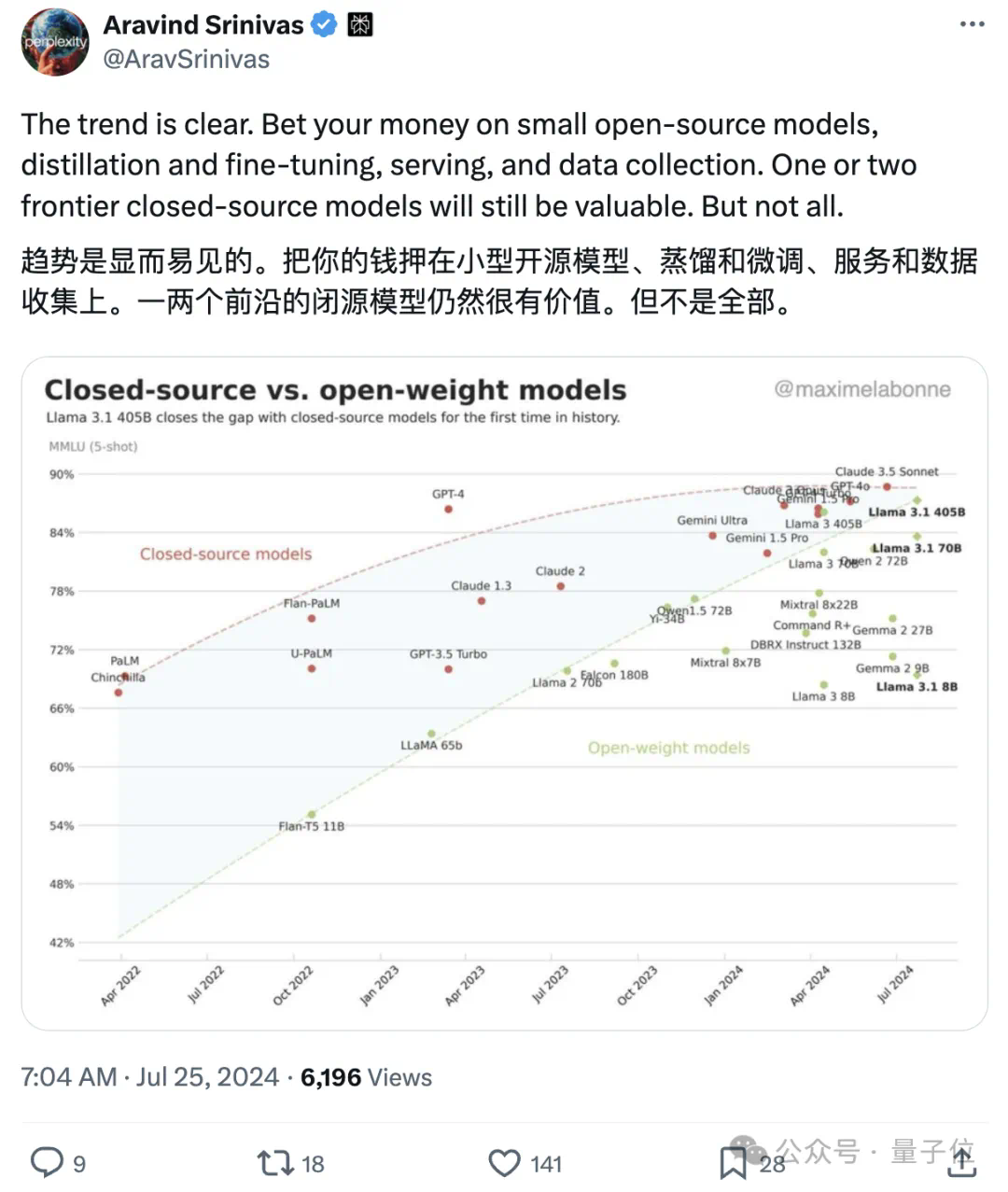
开源大模型杀疯了!Mistral新模型三分之一参数卷爆Llama 3.1,“新趋势已显而易见” Llama 3.1 405B“最强模型”宝座还没捂热乎,就被砸场子了——Mistral AI发布最新模型Mistral...


全部评论
留言在赶来的路上...
发表评论