EDTalk是上海交通大学联合网易研发的音频驱动唇部同步模型,能实现对嘴型、头部姿态和情感表情的独立操控。只需上传一张图片、一段音频和参考视频,就能驱动图片中的人物说话,支持自定义情感,如高兴、愤怒、悲伤等。EDTalk通过三个轻量级模块将面部动态分解成代表口型、姿态和表情的三个独立潜在空间,每个空间由一组可学习的基向量表征,其线性组合定义了特定的动作。这种高效的解耦训练机制提升了训练效率,降低了资源消耗,即使是初学者也能快速上手并探索创新应用。

(图片来源网络,侵删)

(图片来源网络,侵删)


EDTalk是上海交通大学联合网易研发的音频驱动唇部同步模型,能实现对嘴型、头部姿态和情感表情的独立操控。只需上传一张图片、一段音频和参考视频,就能驱动图片中的人物说话,支持自定义情感,如高兴、愤怒、悲伤等。EDTalk通过三个轻量级模块将面部动态分解成代表口型、姿态和表情的三个独立潜在空间,每个空间由一组可学习的基向量表征,其线性组合定义了特定的动作。这种高效的解耦训练机制提升了训练效率,降低了资源消耗,即使是初学者也能快速上手并探索创新应用。

交交是上海交通大学听觉认知与计算声学实验室推出的全球首个纯学术界自研的口语对话情感大模型。交交具备多人对话、多语言交流、方言理解、角色扮演、情感互动及知识问答等强大功能,支持汉语、英语、日语、法语等多种语言,能精准识别中文方...


libcom 是一个由上海交通大学 (BCMI 实验室推出的图像合成工具箱。旨在解决前景和背景之间的不一致性问题,如外观、几何和语义上的不匹配,生成逼真的合成图像。...
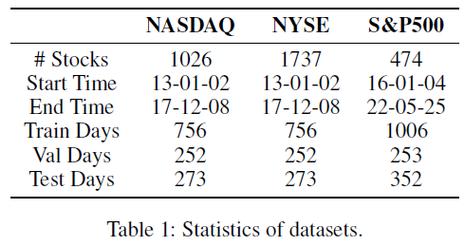
StockMixer是上海交通大学推出的用在股票价格预测的多层感知器(MLP)架构,具备简单和强大的预测能力。架构基于指标混合、时间混合和股票混合三个步骤处理和预测股票数据,有效捕捉股票指标、时间和股票间的复杂相关性。...
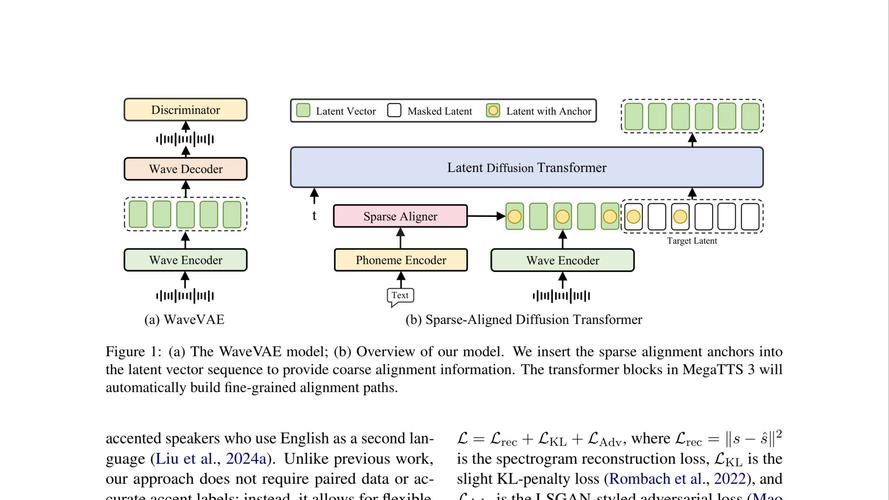
SaRA是一种新型的预训练扩散模型微调方法,由上海交通大学和腾讯优图实验室共同推出。基于重新激活预训练过程中看似无效的参数,让模型能适应新任务。SaRA基于核范数低秩稀疏训练方案避免过拟合,引入渐进式参数调整策略,优化模型性...
PC Agent是上海交通大学和Generative AI Research Lab (GAIR 联合推出的先进AI系统。系统基于模拟人类认知过程,执行如组织研究材料、起草报告和创建演示文稿等复杂数字工作。PC Agent集...

OmniAlign-V 是上海交通大学、上海AI Lab、南京大学、复旦大学和浙江大学联合推出的专为提升多模态大语言模型(MLLMs)与人类偏好的对齐能力设计的高质量数据集。OmniAlign-V包含约20万个多模态训练样本...
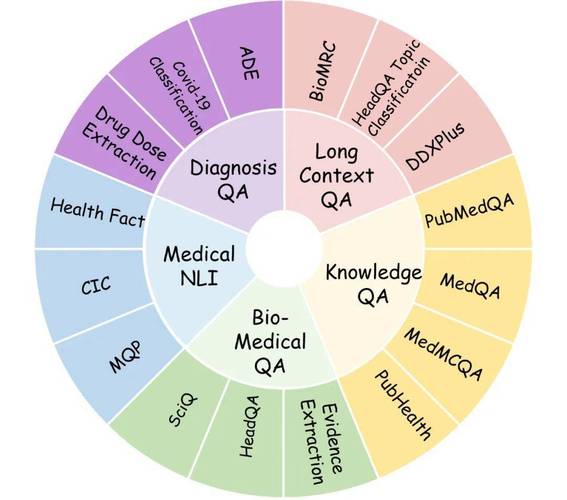
OlympicArena是上海交通大学、上海AI Lab、苏州大学和上海交通大学生成式人工智能实验室(GAIR Lab)联合推出的多学科认知推理基准测试框架。OlympicArena包含11,163道来自国际奥林匹克竞赛的双...

MT-Color是上海交通大学联合哔哩哔哩推出的基于扩散模型的可控图像着色框架,基于用户提供的实例感知文本和掩码实现精确的实例级图像着色。框架基于像素级掩码注意力机制防止色彩溢出,用实例掩码和文本引导模块解决色彩绑定错误问题...


全部评论
留言在赶来的路上...
发表评论